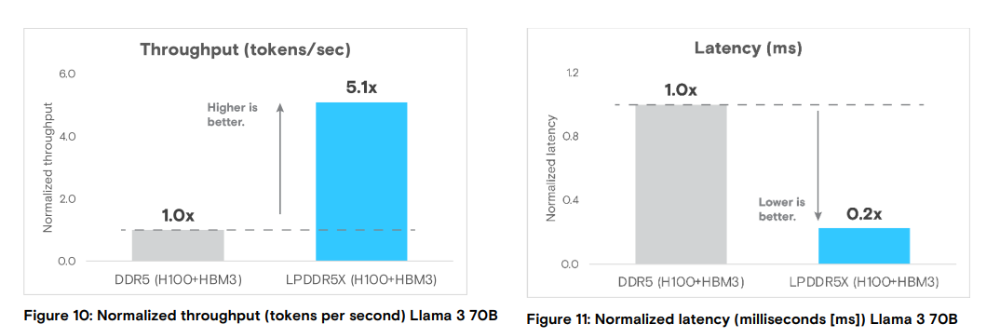
LPDDR5X具有高带宽、低功耗、高容量密度等特性,可用于AI推理等对能效和成本有严苛要求的场景。科技大厂例如英伟达、高通、微软等都将LPDDR5X应用于AI数据中心领域。而存储厂商们包括三星、美光、SK海力士以及长鑫存储等也不断拉高LPDDR5X的规格,有望拓展继智能终端之后AI数据中心这类新应用。 三星电子 三星发布的比前代快1.25倍、功耗效率提升25%的高端低功耗DRAM LPDDR5X,不仅应用于移动设备,还广泛用于PC、服务器、汽车以及新兴的端侧AI应用,未来将引领低功耗DRAM市场的扩展。 设备自身运行AI的端侧AI时代。LPDDR5X支持高达10.7Gbps的惊人超高速数据处理速度。对于需要高性能计算的5G、AI、AR、VR、自动驾驶和元宇宙等未来IT技术和端侧AI生态系统,LPDDR5X是优化的内存解决方案。 LPDDR5X采用了最先进的12nm工艺和创新的电路设计。通过应用更高级的电压可变优化技术(FDVFS)和低功耗运行区间扩展技术,相较于上一代产品,性能提升且功耗减少近25%。在智能手机和笔记本电脑等移动设备中,LPDDR5X提供了更长的电池续航时间;在用于数据中心的服务器中,它有助于降低运营成本(CTO),从而减少碳排放。 移动 DRAM LPDDR5X 在单个封装中支持高达32 GB 的容量,将应用范围从智能手机和笔记本电脑扩展到高性能 PC、服务器和设备上的人工智能应用。三星的LPDDR5X还通过了 AEC-Q100 认证,可在极高和极低温度下提供可靠的性能。 SK海力士 SK 海力士基于第5代10 纳米级(1b nm)工艺的 16Gb LPDDR5X 内存运行速率为 10.7Gbps,相较上代 9.6Gbps LPDDR5T 速度高出约 10%,能效方面提升达到 15%。SK 海力士计划以 SOCAMM 和 LPCAMM 的模组形态向服务器和 PC 市场推出 LPDDR5X 产品,以响应 AI 计算对高性能 DRAM 的需求。 美光科技 美光科技全球首款基于 1γ(1-gamma)工艺节点的LPDDR5X内存支持业界最快的10.7 Gbps 速率,同时功耗最高可降低 20%,封装厚度压缩至 0.61 毫米 ,相比竞品薄 6%,较上一代产品厚度降低14%。 NVIDIA Grace Hopper GH200是首款采用 LPDDR5X 技术的商用产品。该创新系统将 ARM CPU 与H100 GPU相结合,代表高性能计算基础设施的前沿方案。 根据美光的对比分析,基于LPDDR5X的Grace Hopper与同期的DDR5 服务器配置来看,二者的核心架构差异体现在内存封装方式,LPDDR5X 内存直接焊接在 Grace Hopper 板卡上,而 DDR5 则是通过 64 位带宽的模块连接到 CPU。Grace Hopper 的架构采用32个内存控制器,每个控制器管理来自单个 LPDDR5X 封装的16位通道。这种配置在数据处理中提供了更高的并行性与效率,因为每个通道可独立运行。 相比之下,DDR5 系统采用了更传统的设计,4 个内存控制器,每个控制器包含 4 条 32 位通道(使用 2 条 32 位子通道),总计 16 条 32 位通道。LPDDR5X 配置支持 4 个 rank,而 DDR5 仅支持2个rank,进一步提升访问并行性(因为每个 rank 可独立运行)。性能数据凸显了 LPDDR5X 的优势,其峰值理论带宽达 384GB/s,略高于DDR5 的358GB/s。这种更高的数据速率、更强的并行性与更大的带宽相结合,使 LPDDR5X 成为高性能计算应用与混合内存访问模式的优选技术。 在 CPU/GPU系统中使用 LPDDR5X 进行大语言模型推理的效果如何呢。美光科技评估了 LPDDR5X 在两种场景下的大语言模型推理性能:仅使用 CPU 的配置和 CPU+GPU 的配置。 在仅使用 CPU | Llama 3 8B的评估下,在 LPDDR5X 和 DDR5 系统上都运行Llama 3 8B 模型。参数规模在 80 到 200 亿之间的模型通常被认为适合仅在 CPU 上运行。DDR5 系统配备了高性能的 x86 CPU,时钟频率为 3.9 GHz,且具有大容量的末级缓存(L3),其原始性能更优:生成tokens的速度快1.7 倍,首token延迟也低约 1.1 倍。 然而,在评估每瓦性能(衡量能效的关键指标)时,LPDDR5X 系统表现更出色。它借助 LPDDR5X 内存和低功耗的基于ARM架构的 Grace CPU,实现了1.1 倍的能效提升,这有望显著降低推理部署成本。 在CPU 和 GPU | Llama 3 70B的评估下,为了更好地理解在 CPU+GPU 场景下的推理运行中 LPDDR5X 所起的作用,美光科技研究了一个拥有 700 亿参数的 Llama 3 模型。这种规模的模型由于对带宽和计算有更高的要求,需要GPU 和HBM 资源。 并采用了两种配置的 H100/HBM3 GPU:・集成了 H100/HBM3 GPU 的LPDDR5X 系统(NVIDIA Grace Hopper 超级芯片)・标准 DDR5 系统,为了使对比保持一致,在该系统中安装了相同的 H100/HBM3。 关键的差异在于互连性能。Grace Hopper 超级芯片配备了集成的 NVIDIA NVLink,具有 900 GB/s 的双向带宽,而标准 DDR5 系统的 PCIe Gen5 链路仅提供 128 GB/s 的双向带宽。 LPDDR5X 系统的性能大幅优于 DDR5 系统,主要体现在 互连速度(CPU - GPU)快 7 倍 设备到主机的传输速度为346 GB/s,主机到设备的传输速度为 334 GB/s,而 DDR5 的单向传输速度为 55 GB/s 推理吞吐量高 5 倍 推理延迟低 80% 长鑫存储 LPDDR5/5X 是第五代超低功耗双倍速率动态随机存储器。通过创新的封装技术和优化的内存设计,长鑫存储 LPDDR5X在容量、速率、功耗上都有显著提升,目前提供12Gb和16Gb两种单颗粒容量,最高速率达到10667Mbps ,达到国际主流水平,较上一代LPDDR5提升了66%,同时可以兼容LPDDR5,功耗则比LPDDR5降低30%。 英伟达、微软、高通将LPDDR应用于AI数据中心 近日,Cadence宣布与微软合作开发出一款面向数据中心的LPDDR5X 9600Mbps内存系统解决方案。 该方案将Cadence的 LPDDR5X IP 与微软专有的纠错算法RAIDDR(冗余独立双倍数据速率阵列)ECC(纠错码)相结合。该方案可同时实现高性能、低功耗和高可靠性。微软计划在其数据中心部署此方案。双方强调,通过应用RAIDDR ECC技术,实现了与现有服务器DDR5 内存相当的数据保护能力。 此前,美光与英伟达合作开发了SOCAMM,专为支援英伟达 GB300 Grace Blackwell Ultra 超级芯片而设计,能为英伟达的相关AI平台提供低功耗、高容量的内存支持。 去年,高通推出面向数据中心的下一代AI推理优化解决方案,基于Qualcomm AI200与AI250芯片的加速卡及机架系统。Qualcomm AI200带来专为机架级AI推理打造的解决方案,每张加速卡支持768GB LPDDR内存,实现更高内存容量与更低成本,为AI推理提供卓越的扩展性与灵活性。 Qualcomm AI250解决方案将首发基于近存计算(Near-Memory Computing)的创新内存架构,实现超过10倍的有效内存带宽提升并显著降低功耗,为AI推理工作负载带来能效与性能的跨越性提升。 两款机架解决方案均支持直接液冷散热,以提升散热效率,支持PCIe纵向扩展与以太网横向扩展,并具备机密计算,保障AI工作负载的安全性,整机架功耗为160千瓦。据悉,Qualcomm AI200与AI250预计将分别于2026年和2027年实现商用。