大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
沿着这条技术演进路线,下一步是什么?
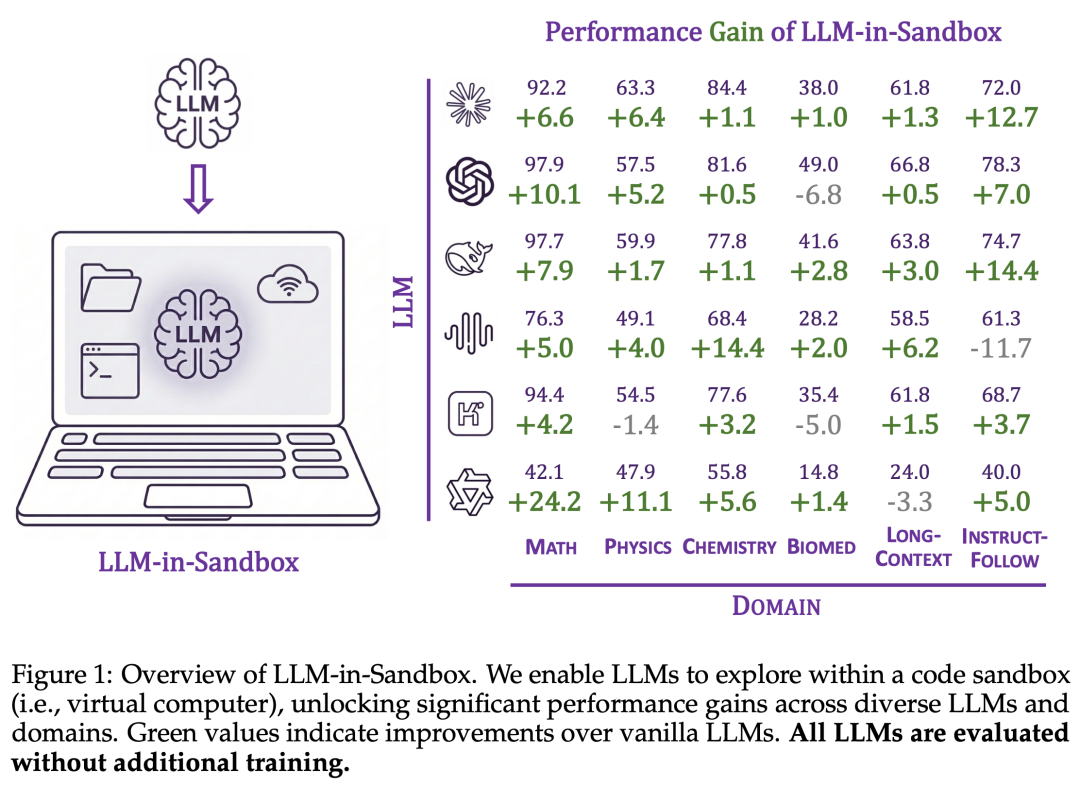
近日,来自中国人民大学高瓴人工智能学院、微软研究院和清华大学的研究者提出了一个简洁而有效的范式:LLM-in-Sandbox——让大模型在代码沙盒(即虚拟电脑)中自由探索来完成任务。实验表明,这一范式不仅在代码任务上有效,更能显著提升模型在数学、物理、化学、生物医学、长文本理解、指令遵循等多个非代码领域的表现,且无需额外训练,同时显著减少长文本场景下的 token 消耗,并保持相当水平的推理速度。
研究者已将 LLM-in-Sandbox 开源为 Python 包,可与 vLLM、SGLang 等主流推理后端无缝集成。LLM-in-Sandbox 应当成为大模型的默认部署范式,取代纯 LLM 推理。

-
论文标题:LLM-in-Sandbox Elicits General Agentic Intelligence
-
论文链接:https://arxiv.org/abs/2601.16206
-
代码链接:https://github.com/llm-in-sandbox/llm-in-sandbox
-
项目主页:https://llm-in-sandbox.github.io
1. 核心思想:给大模型一台电脑
电脑可能是人类创造的最通用的工具,几乎任何任务都可以通过电脑完成。这种通用性源于三大元能力(Meta-Capabilities):
-
外部资源访问:通过网络获取信息和知识
-
文件管理:持久化地读写和组织数据
-
程序执行:编写并运行任意程序
正如人类借助电脑完成各种任务,研究者假设:将大模型与虚拟电脑结合,或许能够解锁其通用智能的潜力。
2. LLM-in-Sandbox:
代码沙盒激发通用能力
2.1 轻量级通用沙盒
与现有软件工程智能体(SWE-Agent)需要为每个任务配置特定环境不同,LLM-in-Sandbox 采用轻量级、通用化的设计:
-
基于 Docker 的 Ubuntu 环境
-
仅预装 Python 解释器和基础科学计算库
-
将领域特定工具的获取交给模型自主完成

这种设计带来两个优势:泛化性(同一环境支持多种任务)和可扩展性(无需为每个任务维护独立镜像)。例如,当扩展到数千个任务时,SWE 智能体可能需要高达 6TB 的存储空间用于任务特定镜像,而 LLM-in-Sandbox 仅需约 1.1GB 的共享镜像。
2.2 最小化工具集
研究者为模型配备了三个基础工具:
-
execute_bash:执行任意终端命令
-
str_replace_editor:文件的创建、查看和编辑
-
submit:标记任务完成
这三个工具共同实现了电脑的核心能力,足以支撑复杂任务的完成。
2.3 探索式工作流
LLM-in-Sandbox 采用多轮交互的工作流:模型在每一轮生成工具调用,接收执行结果作为反馈,然后决定下一步行动,直到调用 submit 或达到最大轮次限制。

2.4 实验结果:无需训练的显著提升
研究者在六个非代码领域进行了实验:数学、物理、化学、生物医学、长文本理解和指令遵循。

实验结果表明,强大的语言模型在 LLM-in-Sandbox 模式下获得了一致性的提升。值得注意的是,这些提升完全无需额外训练:模型能够自发地利用沙盒环境来增强任务表现。
2.5 涌现的工具使用能力
研究者通过案例分析揭示了模型如何自主利用沙盒的三大能力。
-
外部资源访问:在化学任务中,模型被要求根据化合物名称预测分子性质。为此,模型自主安装了 Java 运行环境,并下载了 OPSIN 库来将化学名称转换为分子结构,这些工具并非预装在基础环境中。

-
文件管理:在长文本理解任务中,面对超过 100K tokens 的行业报告,模型并未尝试在 prompt 中处理整个文档,而是使用 grep、sed 等 shell 工具定位相关段落,然后编写 Python 脚本系统性地提取信息。

-
计算执行:在指令遵循任务中,模型被要求生成三个满足严格约束的句子:所有句子必须具有相同的字符数,同时使用完全不同的词汇。模型编写了 Python 脚本来统计字符、检测词汇重叠,并迭代优化候选句子。

3. LLM-in-Sandbox RL:
通过强化学习增强泛化能力
虽然强大的智能体模型能够直接受益于 LLM-in-Sandbox,但较弱的模型(如 Qwen3-4B-Instruct)往往难以有效利用沙盒环境,甚至表现不如纯 LLM 模式。
为此,研究者提出了 LLM-in-Sandbox RL:使用非智能体数据在沙盒环境中训练模型。
3.1 方法设计
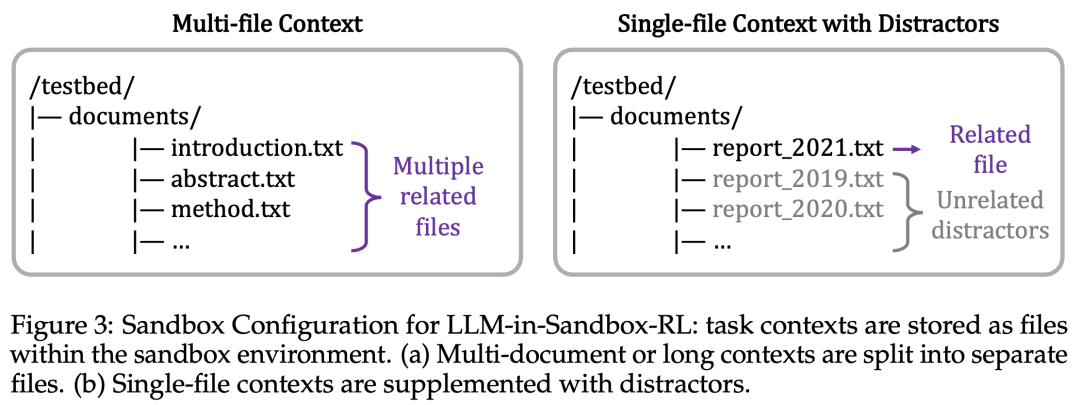
核心思想是采用基于上下文的任务(context-based tasks):每个任务包含背景材料和需要基于这些材料完成的目标。由于完成目标依赖于提供的材料,模型必须主动探索沙盒以找到相关信息,从而自然地学会利用沙盒能力。
3.2 泛化能力

实验在 Qwen3-4B-Instruct 和 Qwen3-Coder-30B-A3B 两个模型上进行。关键发现是 LLM-in-Sandbox RL 展现出强大的泛化能力:
-
跨领域泛化: 训练数据来自通用领域,但模型在数学、物理、化学、长文本、指令遵循等多个下游任务上都获得了一致的提升,甚至在软件工程任务上也有改善。
-
跨推理模式泛化:有趣的是,LLM-in-Sandbox RL 不仅提升了沙盒模式的表现,还同时提升了纯 LLM 模式的表现。这说明在沙盒中学到的探索和推理能力可以迁移到非沙盒场景。
-
跨模型能力泛化: 无论是较弱的通用模型(Qwen3-4B-Instruct)还是较强的代码专用模型(Qwen3-Coder-30B-A3B),LLM-in-Sandbox RL 都能带来一致的提升,表明这一方法具有良好的模型通用性。
4. 效率分析:
LLM-in-Sandbox 的实际部署价值
4.1 Token 消耗
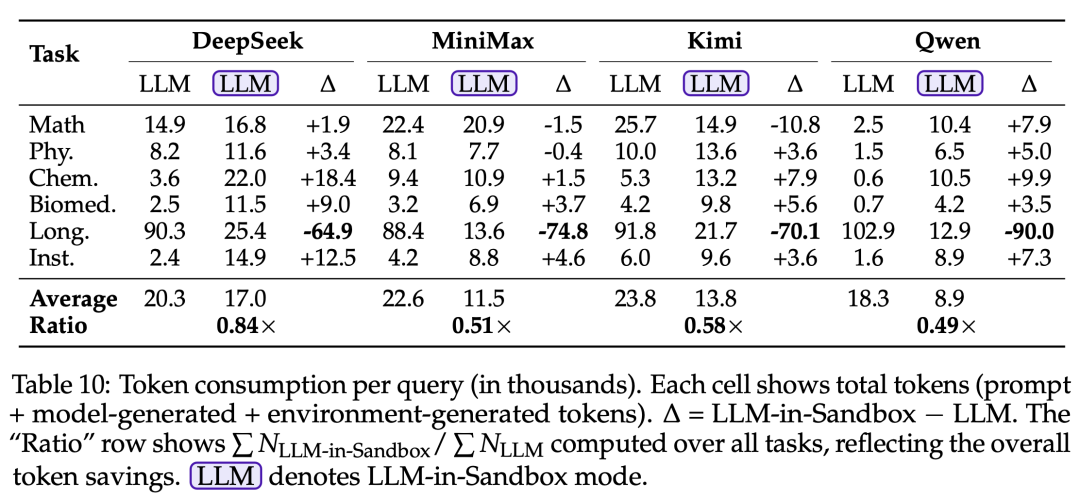
在长文本场景下,LLM-in-Sandbox 将文档存储在沙盒中而非放入 prompt,可将 token 消耗降低最多 8 倍(100K → 13K tokens)。
4.2 推理速度

通过将计算卸载到沙盒,LLM-in-Sandbox 将工作负载从慢速的自回归生成(decode)转移到快速的并行预填充(prefill),在平均情况下保持有竞争力的吞吐量(QPM):MiniMax 可实现 2.2 倍加速。
5. LLM-in-Sandbox 超越文本生成
前面的实验评估的是 LLM 和 LLM-in-Sandbox 都能完成的任务。然而,LLM-in-Sandbox 还能实现纯 LLM 根本无法完成的能力。通过给 LLM 提供虚拟电脑,LLM-in-Sandbox 突破了 text-in-text-out 的范式,解锁了新的可能性:
-
跨模态能力:LLM 局限于文本输入输出,但 LLM-in-Sandbox 可以通过在沙盒中调用专业软件来处理和生成图像、视频、音频和交互式应用
-
文件级操作:不再是描述文件应该包含什么,而是直接生成可用的文件 ——.png、.mp4、.wav、.html
-
自主工具获取:不同于预定义的工具调用,LLM-in-Sandbox 使 LLM 能够自主发现、安装和学习使用任意软件库

这些案例揭示了一个有前景的方向:随着 LLM 能力的增强和沙盒环境的完善,LLM-in-Sandbox 可能演化为真正的通用数字创作系统。
6. 总结与展望
LLM-in-Sandbox 提出了一个简洁而有效的范式:通过给大模型提供一台虚拟电脑,让其自由探索来完成任务。实验表明,这一范式能够显著提升模型在非代码领域的表现,且无需额外训练。
研究者认为,LLM-in-Sandbox 应当成为大模型的默认部署范式,取代纯 LLM 推理。当沙盒可以带来显著的性能提升,并且部署成本几乎可以忽略不计时,为什么还要用纯 LLM?
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com