> 作者:李剑锋
简介
随着 Agent 概念的普及,以 Coze、Dify 为代表的低代码 / 无代码平台迅速兴起。这类平台通过可视化配置和模块化编排,大幅降低了智能体应用的使用门槛,使非技术用户也能快速构建 AI 应用,在原型验证和轻量场景中具有明显优势。
但当开发者开始将 Agent 系统真正用于业务落地时,低代码平台的局限也逐渐显现。在私有化部署、复杂流程控制、工具调用灵活性以及调试与扩展能力等方面,开发者往往需要受限于平台本身,而难以完全按照业务逻辑自由设计。尤其是在多阶段任务、条件分支、循环处理,以及“确定性逻辑与大模型推理混合执行”的场景中,流程很容易变得臃肿且难以维护。
在这样的背景下,LangGraph 提供了一种更偏向工程视角的解决方案。它不试图用图形界面替代代码,而是通过“图(Graph)”的形式,将 Agent 的执行流程、状态流转和控制逻辑显式建模,让开发者在保留大模型智能性的同时,重新掌握系统的控制权。
简而言之,低代码平台关注的是“如何快速用起来”,而 LangGraph 更关注“如何把系统长期跑好”。因此,下面我们将从 LangGraph 最基础的 workflow 入手,看看如何以工程化的方式构建一个可控、可维护的 Agent 流程。
准备阶段
环境准备
在正式开始之前,我们需要先安装一些必要的库:
pip install langchain langgraph langchain-community dashscope
密钥准备
然后我们还需要准备一个百炼大模型平台的密钥,并写入 DASHSCOPE_API_KEY 中:
DASHSCOPE_API_KEY = "你的 api key"
LangGraph 基础
简介
在没有 LangGraph 之前,你通常会遇到这些问题:
-
链式(Chain)只能线性执行,不适合分支、循环 -
Agent 行为不可控,很难约束“下一步一定做什么” -
多轮调用中: -
状态怎么保存? -
什么时候结束? -
什么时候回退 / 重试? -
调试困难,看不清一次调用内部发生了什么
LangGraph 正是为了解决这些问题而出现的,它把 LLM 应用的执行过程显式建模成一个“状态机 / 流程图”。
核心概念
在正式讲授课程内容之前,这里我要先铺垫几个重要的概念,包括:
-
State(状态) -
Node(节点) -
Edge(边) -
Graph(图)
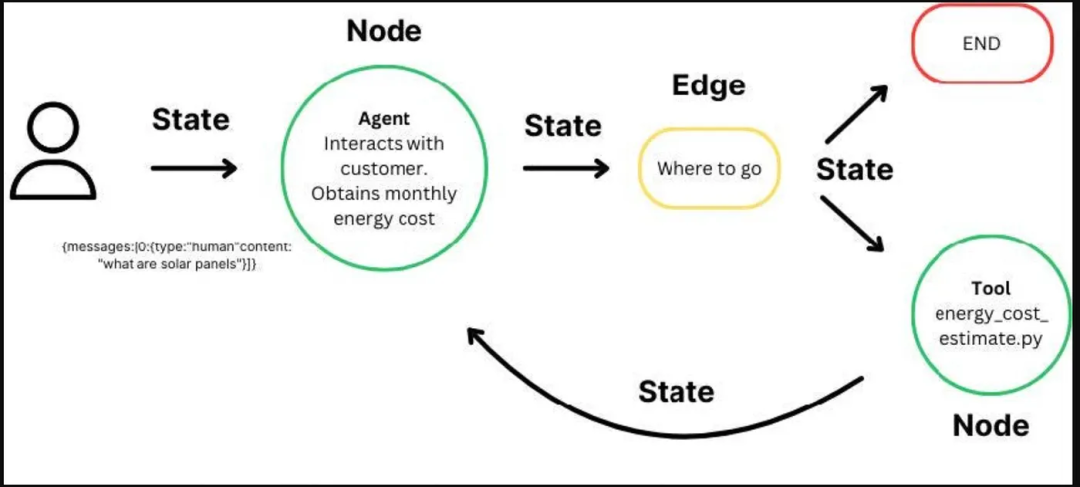
State(状态)
State(状态)是整个 LangGraph 能够顺利运行的核心。它本质上是一个 Python dict / TypedDict / Pydantic 模型,代表「当前执行到这一步时,系统所拥有的全部信息」。比如说下面这样一个用于 RAG 系统的 state:
{
"question": "...", # 用户问题
"docs": [...], # RAG 检索结果
"answer": "...", # 当前生成的答案
}
那我们随着任务的进行,可能会不断得往这个 State 里去添加、替换里面的内容。但是这个 State 其实本质上就是整个流程图里所有需要被保存的信息了。所以在任何工作之前,我们都需要先设计一个 State,然后去思考每一步我们需要如何更新这个 state。
Node(节点)
那前面说了关于 State 的内容,那谁去更新这些 State 呢?其实就是基于一个个节点去进行更新,也就是流程图中每一个子任务。那这些任务其实并不抽象,本质上每个 Node 都代表着一个函数,其输入的内容一般就是 State 里的内容。
比如一个 RAG 的流程中,我们一般会先检索完加载到提示词里传给模型进行回复。那这里吗就会存在着四个节点,核心其实就是检索和模型两个节点:
-
问题传入:question(START) -
检索:根据传入的问题进行检索 -
模型:将检索内容整合后并给出最终答案 -
结果输出:answer(END)
那在一开始,当用户把问题传入的时候 ,那就会从 START 开始,问题会直接被更新到 state 的 question 变量中。然后在检索的节点,那就会从这个 state 里将 question 的内容提取出来以后,进行检索。并且在检索完成以后,将找到的片段内容存放到 docs 中。然后再到下一个节点也是一样的,模型会先从 state 中找到检索到的 docs 以及最开始用户问题的问题 question,然后将这两部分内容进行解析整合,并且最终获取到输出,最后将这部分内容更新到 state 的 answer 变量中。最后这个 answer 会传出来到 END,最终整个流程就此完结。
那此时我们基于这个流程图就可以设置以下两个节点:
.add_node("retrieve", retrieve)
.add_node("llm", call_llm)
所以可以看到,其实这个 Node 就是每一部分的处理逻辑,然后其也对应着一个函数,传入的内容就是 state 的内容,传出的内容则是对 state 内容的更新。这也是为什么我们要对 state 进行妥善设置的核心原因,假如 State 无法正确的承接对于的变量信息的话,那么很容造成整体的混乱。
Edge(边)
那有了一个个的节点了以后,对于流程图而言,还有一个很重要的工作就是将他们连接起来。对于一般的流程图而言,其实就是将节点一一进行连接,比如有 ABC 三个节点并且其连接方式如下所示:
A → B → C
这种场景其实是比较简单的,也是在 LangGraph 里最常见的,我们只需要写成下面这样即可(START 和 END 都是内置的):
from langgraph.graph import START, END
.add_edge(START, "A")
.add_edge("A", "B")
.add_edge("B", "C")
.add_edge("C", END)
但是有些时候并不是直接线形连接的,比如有一些通过判断决定的情况:
def route(state):
if state["need_search"]:
return "search"
else:
return "answer"
那这个时候我们可能就需要用到的是 .add_conditional_edges 进行实现了,当然这里只是演示而已,后续会更深入进行讲解:
graph.add_conditional_edges(
"decide",
route,
{
"search": "retrieve",
"answer": "generate"
}
)
所以可以看到,这个 edge 本质上就是将节点和节点连接起来,对于一些特殊的情况也可以通过 conditional_edges 的方法进行传递。
Graph(图)
最后就是 Graph 部分的内容了,这个其实主要做的事情就是:
-
创建状态机(StateGraph) -
注册所有 Node -
定义 Edge(流程结构) -
指定: -
起点(START) -
终点(END) -
将所有的内容进行编译(.compile()),后续就可以对该图进行调用了
比如下面要演示的 RAG 例子中整体的 Graph 就是如下所示:
workflow = (
StateGraph(State)
.add_node("rewrite", rewrite_query)
.add_node("retrieve", retrieve)
.add_node("agent", call_agent)
.add_edge(START, "rewrite")
.add_edge("rewrite", "retrieve")
.add_edge("retrieve", "agent")
.add_edge("agent", END)
.compile()
)
以上就是学习 LangGraph 构建流程图前必须了解的核心概念了,下面我们那将基于一个简单的代码示例来演示一下这部分是如何实现的吧!
代码实战
任务简介
首先这里我简单介绍一下这个任务。这个任务是模拟一个真实的 RAG 调用场景,然后通过用户提出的问题获取智能体的回复:
START
↓
rewrite (把用户问题改写成更适合检索的 query)
↓
retrieve (用改写后的 query 去向量库检索 documents)
↓
agent (把 documents + 原问题一起喂给 agent 生成答案)
↓
END
具体实现的流程图如下:

在开始运行前需要载入以下的库,并且设置大模型:
from typing import TypedDict
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.chat_models import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
import os
model = ChatTongyi(api_key=os.environ.get("DASHSCOPE_API_KEY"), model="qwen-max")
状态构建
就像前面介绍 LangGraph 的一样,在我们了解完整体的任务需求后,我们就可以开始去设计内部需要的状态内容:
class State(TypedDict):
question: str
rewritten_query: str
documents: list[str]
answer: str
这里我们总共设置了四个状态内容,其具体完成的内容包括:
-
question:对应的是最开始用户传入的问题 -
rewritten_query:基于传入的 question 内容后改写的搜索语句(对应 rewrite 模块) -
documents:基于传入的 rewritten_query 搜索到的内容(对应 retrieve 模块) -
answer:基于最开始的 question 和搜索到的 documents 给到 agent 并进行回复(对应 agent 模块)
所以我们可以看到,state 的设置完全是为了整体流程而服务的。每一个 state 的目的都是为了接收其中一个流程输出的内容。
重写节点构建
在设置完 state 了以后,其实我们也已经对其中的流程节点有了更进一步的认识。下面我们就来看看第一个关键节点—rewrite 是如何进行设置的。
首先我们要明确的是这部分的输入和输出格式和内容是什么。很显然这里没有很复杂的数据类型,输入的就是 question 的内容,这个我们可以从 state 中获取到。然后最终模型的输出我们要的是一个字符串的回复内容。基于这个基本思路我们就可以开始写代码了。
那这里 rewrite 的话我们并不是通过别的 nlp 的方法实现,而还是使用大模型来对其进行改写。假如用大模型来改写的话,我们必须说清楚其需要完成的内容是什么,所以就要完成系统提示词的撰写。
这里的我们的系统提示词主要就是介绍了一下任务是什么,然后要去检索的信息是什么领域的,还有重点关注的内容等信息。用户提示词就只是在 state 里传入的 question。
但是直接调用大模型返回的内容是 LangChain 格式的 AIMessage ,并不是我们多希望的字符串信息。所以这里我们使用了一个结构化输出的方法 .with_structured_output。这个方法可以绑定一个 Pydantic 定义的类,然后按类里定义的内容进行结构化的输出。这里我们创建的就是 RewrittenQuery,里面就只有一个元素 query,并且设定其格式为我们所需要的字符串。那此时通过model.with_structured_output(RewrittenQuery) 调用返回的结果就不再是 AIMesaage 了,而是一个格式化的 pydanfic 类了,我们只需要通过 .query 就可以将其中字符串的内容进行获取。
最后我们返回的内容就是要更新 state 里的 rewritten_query 信息的,因此我们就返回了一个对应的字典进去,并且把对应的字符串内容也放进去。那么当调用这个节点的时候就会自动进行更新了。
class RewrittenQuery(BaseModel):
query: str
def rewrite_query(state: State) -> dict:
"""Rewrite the user query for better retrieval."""
system_prompt = """Rewrite this query to retrieve relevant WNBA information.
The knowledge base contains: team rosters, game results with scores, and player statistics (PPG, RPG, APG).
Focus on specific player names, team names, or stat categories mentioned."""
response = model.with_structured_output(RewrittenQuery).invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": state["question"]}
])
return {"rewritten_query": response.query}
但是这里有个点需要注意,就是with_structured_output 并不是强约束,而是一次“尝试解析”。当模型输出无法正确映射到 schema 时,返回值可能为 None,因此在真实项目中应始终做好兜底处理。
检索节点创建
对于检索节点而言,其实第一步是要创建一个向量数据库才能实现对向量数据库的检索。
向量数据库创建
首先,创建向量数据库需要准备将文本转为向量的 embedding 模型以及将向量内容保存的向量数据库。
这里使用的 embedding 模型就是 dashscope 的 embedding 模型。幸运的是这个和 qwen 模型是共用一个 api_key 的,所以我们可以直接使用。
然后选择好 embedding 模型后,我们就可以选择合适的向量数据库。由于这里只是演示,因此这里选用的就是最简单的,将向量保存在内存的 InMemoryVectorStore (程序跑完就自动释放了)。我们通过传入 embedding 模型即可进行创建。
创建完后,我们就可以往里面写入内容了。这里我们就通过 .add_text 的方法往里面写入了多条数据。这样向量数据库就已经创建好了。
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv('DASHSCOPE_API_KEY'),
model="text-embedding-v1")
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_texts([
# Rosters
"New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot.",
"Las Vegas Aces 2024 roster: A'ja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray.",
"Indiana Fever 2024 roster: Caitlin Clark, Aliyah Boston, Kelsey Mitchell, NaLyssa Smith.",
# Game results
"2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship.",
"June 15, 2024: Indiana Fever 85, Chicago Sky 79. Caitlin Clark had 23 points and 8 assists.",
"August 20, 2024: Las Vegas Aces 92, Phoenix Mercury 84. A'ja Wilson scored 35 points.",
# Player stats
"A'ja Wilson 2024 season stats: 26.9 PPG, 11.9 RPG, 2.6 BPG. Won MVP award.",
"Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year.",
"Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.",
])
检索函数设置
创建完成后,我们就可以基于这个向量数据库来创建一个检索节点了。那首先我们先要定义一个检索器。所谓检索器其实就是输入问题输出找到的文档片段。这里我们就通过 vector_store.as_retriever 方法进行了实现,并且设置了 k=5 这个参数,即找到最相关的 5 个文档片段这样。
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
创建好了检索器后,我们也是可以基于检索器来设置检索节点的内容。那这里我们先将 state 中的 rewritten_query 部分内容取出然后通过 .invoke() 的方法传入检索器中。这样的话就能够找到多个 Document 的文档片段。
但是这些个文档片段不能够直接放入到 State 中,因为还有很多没有用的元数据在这些 Document 类中。因此我们需要先通过 for 语句一个个地将其提取出来,然后通过 doc.page_content 来将里面的文本字符串内容提取出来,最终形成一个包含 5 个长文本字符串的列表,并且传入到 state 的 documents 中进行保存。
def retrieve(state: State) -> dict:
"""Retrieve documents based on the rewritten query."""
docs = retriever.invoke(state["rewritten_query"])
return {"documents": [doc.page_content for doc in docs]}
智能体节点构建
在构建完检索的节点后,下一步就可以着手完成最后一个智能体节点的构建。那对于智能体而言,其实最重要的就两个事,一个是要给智能体一个什么样的大模型作为大脑,这里我们就用前面创建好的 model 进行实现即可。另外一个就是要配套的是什么工具。
工具
那对于工具而言,我们首先要去思考这个 agent 要完成的任务是什么。前面我们已经说了其需要去查询向量数据库当中的 WNBA 内容。所以很明显我们这个智能体要完成的就是搜查和 WNBA 相关内容的工作。那 WNBA 现在还一直有在打,因此这里我们就应该去设置一个获取最近 WNBA 消息的工具才可以。当然这里的工具是假装的而已,但是我们可以换上真实的 API 并进行使用:
@tool
def get_latest_news(query: str) -> str:
"""Get the latest WNBA news and updates."""
# Your news API here
return "Latest: The WNBA announced expanded playoff format for 2025..."
实现 agent 节点
有了工具和模型后,我们就可以将两者进行组合形成一个 agent。
agent = create_agent(
model=model,
tools=[get_latest_news],
)
那对于检索节点而言,前面其实已经说了我们就是把原问题和找到的文档内容组合成提示词然后给到智能体,所以这里我们就先从 state 中将 documents 和 question 都给提取出来。然后通过 f-string 的方式将其拼装起来形成 prompt。当然 documents 是一个列表要先进行 .join() 处理将其进行整合。
def call_agent(state: State) -> dict:
"""Generate answer using retrieved context."""
context = "\n\n".join(state["documents"])
prompt = f"Context:\n{context}\n\nQuestion: {state['question']}"
response = agent.invoke({"messages": [{"role": "user", "content": prompt}]})
return {"answer": response["messages"][-1].content}
然后准备好了 pormpt,就可以直接将 prompt 作为用户提示词进行传入即可。最后我们就能够获取到返回 AIMessage 中的 content 作为文本字符串并将其更新到 state 中的 answer 字段中。
整体流程图构建
当每一个节点都构建完成后,我们就可以构建整体 LangGraph 的流程图了。对于这个 workflow 来说,首先第一步就是要先将图进行创建,也就是 StateGraph() 这部分内容。在这个图里面呢我们还需要将 State 也给存进去,从而告诉 LangGraph 全程都要使用该 State 实现。
然后呢我们就可以把刚刚做好的三个函数与三个节点通过 .add_node() 的方式进行创建,并且分别给他们附上 rewrite, retrieve 和 agent 的名称。
节点创建好了以后就可以通过 .add_edge() 去按顺序来进行边的连接了。那这里我们都是线性的连接,所以就是从 START 开始然后到 rewrite,再到 retrieve,再到 agent , 然后就到 END 结束了。那最后整个 workflow 返回的内容其实就是整个 state 的字典,我们可以从中提取我们所需要的内容。
当边都设置完了以后,最后我们还需要对整个 workflow 进行编译,也就是 .compile,这样的话整个 workflow 才能后续进行调用。
workflow = (
StateGraph(State)
.add_node("rewrite", rewrite_query)
.add_node("retrieve", retrieve)
.add_node("agent", call_agent)
.add_edge(START, "rewrite")
.add_edge("rewrite", "retrieve")
.add_edge("retrieve", "agent")
.add_edge("agent", END)
.compile()
)
流程图调用
编译完了以后我们就可以对 workflow 进行 .invoke 的调用了。比如说问一个 2024 年的 WNBA 冠军是谁?
result = workflow.invoke({"question": "Who won the 2024 WNBA Championship?"})
print(result)
此时我们可以把 result 打印出来看看里面具体的内容是什么。那通过下面的代码块其实可以看出来,其实整个返回的 result 就是我们前面设置的 state,只不过是已经加载好所有内容的 state 了。我们可以看到提问的问题、改写的问题、找到的内容片段以及最后的回复信息。
{'question': 'Who won the 2024 WNBA Championship?', 'rewritten_query': '2024 WNBA Championship winner', 'documents': ['2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship.', 'New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot.', "Las Vegas Aces 2024 roster: A'ja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray.", 'Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year.', 'Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.'], 'answer': 'The 2024 WNBA Championship was won by the New York Liberty, as they defeated the Minnesota Lynx 3-2 in the finals.'}
假如我们做的是一个对话类的平台,其实其他信息我们都可以不返回给用户,我们只需要返回最后的 answer 即可:
print(result["answer"])
总结
通过本文的完整示例可以看到,LangGraph 并不是在“重新发明 Agent”,而是从工程视角出发,对 Agent 的执行流程、状态管理与控制逻辑进行了系统化重构。它将原本隐藏在 Agent 内部的推理步骤与执行顺序,显式地建模为一张可阅读、可调试、可扩展的 workflow 图,使开发者能够真正理解并掌控智能体在“每一步究竟做了什么”。
在这个基础示例中,我们从 State 的设计出发,逐步构建了 rewrite、retrieve、agent 等节点,并通过 Edge 明确规定了流程的执行顺序。整个过程中,大模型只在“确实需要智能推理”的节点中参与,其余逻辑则以确定性的代码形式存在,从而在智能性与可控性之间取得了良好的平衡。这种设计方式,正是 LangGraph 相较于低代码 Agent 平台最核心的优势所在。
更重要的是,这种 workflow 思维并不仅仅适用于 RAG 场景。无论是多 Agent 协作、复杂条件路由、循环重试,还是人类介入(HITL)、调试回放与状态追踪,都可以在同一套 Graph 抽象下自然演进。它为 Agent 系统提供的,并不是“更快搭出来”的能力,而是“长期可维护、可演化”的工程基础。
在后续内容中,我们将基于这一基础 workflow,进一步引入条件分支、路由决策、多智能体协作等更复杂的模式,逐步展示 LangGraph 在真实业务与教学场景中的完整威力。希望你在读完这篇文章后,不仅“会用 LangGraph”,更能建立起一种以流程与状态为中心的 Agent 工程思维。
-- 完 --