克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
模型发布近3个月后,百度ERNIE 5.0的技术报告终于来了。

其底座采用超级稀疏的Ultra-Sparse MoE架构,参数量高达万亿,但推理时真正激活的参数不到3%,是目前公开模型中首个实现这一规模的统一自回归模型 。
而且架构上拒绝“拼接”,真正做到了四种模态的原生自回归统一,让所有模态从零开始就在同一个Transformer Backbone里跑。
ERNIE 5.0的成绩单也相当漂亮:VBench视频语义评分拿下83.40,语音识别AISHELL-1字错率低至0.31,MATH推理也跑出了73.89,妥妥的六边形战士。

看了这份报告,网友表示ERNIE的模式非常有意思。

MoE路由调度不看模态
为了打破不同模态数据之间的隔阂,ERNIE 5.0在核心架构上采用了一种模态无关的专家路由(Modality-Agnostic Expert Routing)机制。
这和以往那些“分而治之”的传统模型大不相同,拆除了人为设立的模态壁垒,不再预先给数据贴上“视觉”或“语言”的标签。
ERNIE 5.0中,研发团队构建了一个共享专家池(Shared Expert Pool),让所有模态的数据都能在同一个巨大的参数网络中自由流动。

在具体的调度执行上,模型完全基于统一Token表征进行决策。
无论输入数据的原始模态如何,都能被转化为统一格式并精准匹配最合适的专家。
不过与传统模式殊途同归的是,这种开放式的管理策略在训练中引发了涌现式专业化(Emergent Specialization)现象。
也就是说,在没有任何人工指令规定分工的情况下,专家们在海量数据的磨练中自己“悟”出了角色定位——
有的自动变成了视觉专家,有的专攻文本逻辑,还有一部分进化成了负责跨模态对齐的“通才”。
这种隐式协作不仅让多模态理解更加丝滑,也让模型的能力边界得到了自然延展。
弹性预训练,一次产出多个模型
除了新的专家调度方式,ERNIE 5.0还首创了“一次性全能”的弹性训练范式。
以前为了适配不同算力的设备,往往得把模型重做一遍大中小好几个版本,消耗时间和算力资源。
现在,ERNIE 5.0通过构建一个超大的超网络,只需跑一次预训练,就能从中通过权重共享的方式,直接抽取出一整套不同规格的子模型矩阵。
具体到操作上,它引入了弹性深度(Elastic Depth) 机制。
在训练过程中,系统采用了类似层丢弃的策略,不再死板地每次都走完所有计算层,而是随机跳过一部分Transformer层,让模型中的浅层网络也能独立承担计算任务。
同时,它还支持弹性宽度与稀疏度(Elastic Width & Sparsity) 的调节。
这意味着它可以动态裁剪专家池的总容量,以及灵活调整每次推理时具体激活的活跃专家数,从而在全量万亿参数和轻量化部署之间找到最佳平衡点。
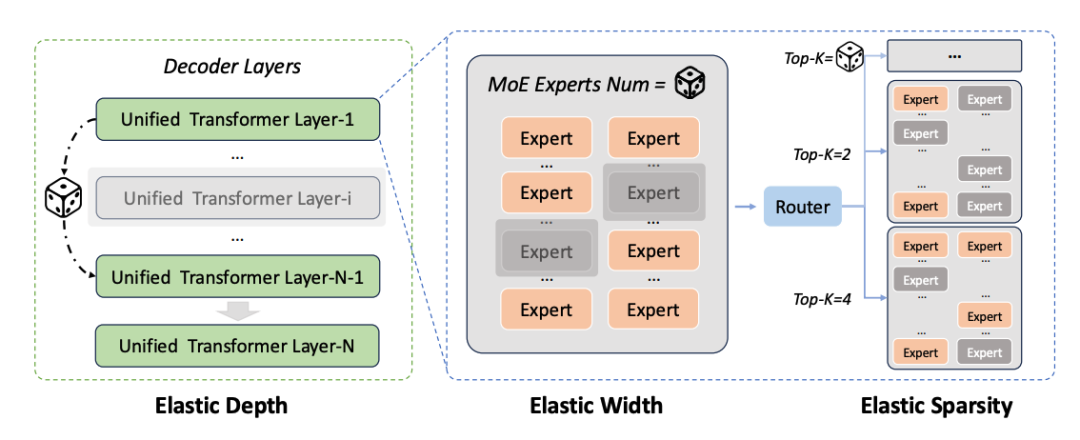
这种练法最大的好处就是零样本抽取。提取出来的子模型不需要重新进行昂贵的微调,也不用搞那些复杂的模型压缩流程,直接就能继承全量模型的能力。
后训练优化
在对齐阶段,ERNIE 5.0实施了统一多模态强化学习(UM-RL)策略,将逻辑推理、指令跟随与多模态生成任务纳入同一RL流水线中进行协同优化,实现了跨模态能力的深度对齐。
针对训练效率问题,模型引入了无偏重放缓存(U-RB)技术,通过严格的数据排序约束,有效解决了不同长度任务带来的计算负载不均问题,从而大幅提升了整体训练吞吐量。
为了保障策略优化的稳定性,ERNIE 5.0应用了多粒度重要性采样剪裁(MISC)与已掌握样本掩码(WPSM)机制。这两项技术专注于抑制训练初期容易出现的熵崩塌现象,确保模型在复杂的优化过程中保持策略更新的稳健性。

此外,面对奖励稀疏的困难任务,模型采用了自适应提示强化学习(AHRL),在训练初期注入“思维骨架”作为引导信号,并随着训练进度的深入逐步退火,最终实现从辅助引导到独立解决复杂问题的平滑过渡。
除了核心架构与训练范式,技术报告中还用大量篇幅拆解了各个模态的具体处理细节,包括文本的位置编码(Positional Encoding)变体、图像与视频的时空Patch化(Spatiotemporal Patching)策略,以及音频信号的离散化编码(Discrete Coding)方案。
此外,报告还披露了底层PaddlePaddle框架在千卡集群上的通信优化策略,以及针对超长上下文的高效注意力机制设计。
想要了解这些细节,可以到原文当中一探究竟。
报告地址:
https://arxiv.org/abs/2602.04705










