点击下方卡片,关注“具身智能之心”公众号
近日,位于中关村的深度机智全球首次使用全新范式-人类学习,在多个国际Benchmark上取得SOTA,史无前例的使用全新架构(仅第一视角人类数据、零真机数据)击败Physical Intelligence和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。而这一全新架构的诞生,得益于团队在人类学习路线上一年多的全力积累。无独有偶,近期英伟达也发布了人类学习的初步尝试。
近半年,具身领域最大的突破,莫过于Physics AI和世界模型。短短几个月,具身领域不再是VLA方案一家独大,大家正在把目光投向一个新的领域。
先是physical intelligence宣称利用人类视频数据在VLA微调上出现涌现特性。
不久,1x发布人类视频数据预训练的世界模型1xWM。
紧接着,英伟达提出了大规模第一人称人类数据的世界模型数据集DreamDojo-HV和世界动作模型Dreamzero,和VLA模型EgoScale。
再到前段时间Generalist AI提出了「物理常识」是机器人学习的「暗物质」,是探索具身智能必须回归的第一性原理。
这个观点很有意思,虽然难以用语言描述和捕捉,但却是具身智能学习的本质:机器在物理世界的自主交互能力,必须围绕物理世界的本质规律展开,单纯模仿轨迹无法让机器人真正理解物理世界。
当国外大厂纷纷布局人类视频学习路线,聚焦物理常识时,国内许多企业还在争论仿真与真机数据的高下,辩论VLA与世界模型用于轨迹拟合的优劣。
然而,我们也发现,有一家由北京中关村学院、中关村人工智能研究院孵化的中国具身大脑公司“深度机智”,早已经布局了和英伟达等海外具身大厂和独角兽类似的第一视角人类数据方案。
陈凯博士,作为这家公司的创始人,这位前微软亚洲首席研究员(现任中关村学院导师、中关村人工智能研究院研究员),坚持的路线被行业逐渐认可。
不是做 “通用具身智能”,而是打造 “具身通用智能”。这也是深度机智一直坚持的,在大模型通用能力的基础上,赋予其对物理世界的认知和理解,从而拥有跨任务、跨场景、跨环境的泛化能力,能像人一样处理开放物理世界的多样任务。
它重塑了整个行业对物理AI的认知,让大规模第一视角人类数据的学习路线前景变得更加清晰。

(一)物理AI正在重塑具身技术格局
在具身的发展路径上,我们始终绕不开一个核心问题:为什么人类能轻松在物理世界完成各种精细、灵活的交互,而机器即便能完成高精度的预编程动作,在面对非结构化的现实场景时,却极易陷入失效的困境?
具身行业尝试给出以数据为中心的模型升级路线,在这个过程中,数据质量、规模和场景不断地增加,但训练得到的VLA模型仍然“只会模仿、不会推理” —— 能执行训练过的动作,却无法应对未见过的任务与环境。
这一点,Generalist AI给出的解释是:遥操采集的数据,会因延迟、触觉反馈缺失等问题,让操作者从“本能反应”变成“刻意思考”,记录的动作轨迹僵硬且脱离物理现实,用这类数据训练的具身机器人,天然存在动作生硬、无法应对突发状况的问题。
回到问题的本质上,说到底还是因为数据没有保留真实物理交互的线索。物理常识,对人类而言是刻在肌肉记忆里的默会知识,是在终身的感知运动体验中,形成的对力、摩擦力、柔度和不确定性的本能直觉。
伸手拿紧挨着的盒子时会先轻推腾空间,重物滑落时会下意识调整握姿,倒水时会根据容器重量变化控制力度……这些无需思考的微调整、快恢复,构成了我们操控物理世界的核心能力。
但对机器来说,这种存在于“感知-动作”闭环中的能力,既难以用语言描述,更无法通过编程实现——而这,恰恰是具身智能机器人要走向现实世界的第一道门槛。
不难发现,基于轨迹拟合的VLA 模型缺乏对物理世界的真正理解,这样直接的映射合理吗?答案当然是否定的,机器人真正需要的是 “理解场景-预测结果-规划动作” 的完整逻辑链。
也正是这个原因,物理AI的重要性日益凸显,逐渐成为了具身领域重要的技术突破方向。
近一年,具身领域的龙头英伟达在物理世界的理解上下了很大功夫,一是推出了世界-动作框架DreamZero,二是基于人类第一视角构建更大规模的数据基准DreamDojo-HV和通用训练框架DreamDojo,三是直接利用人类第一视角数据构建VLA基座的EgoScale。
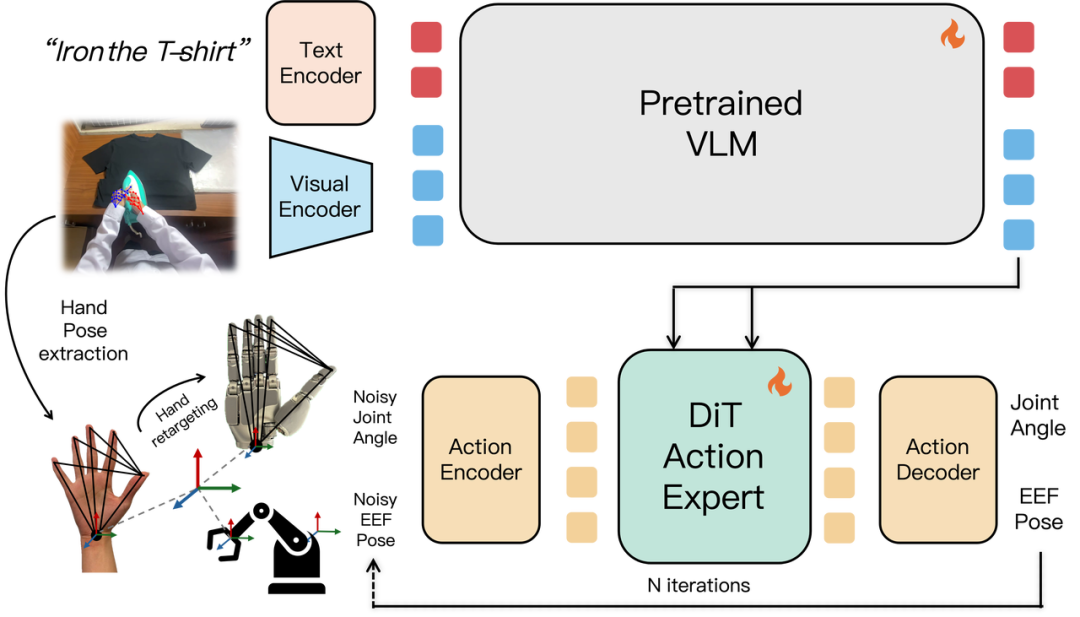
EgoScale构建了包含超过2万小时带动作标签的人类第一视角视频数据集,规模是此前同类研究的20倍以上。并以VLM为主干、DiT为动作专家,通过统一的手腕级动作表示,将人类数据与机器人数据对齐,并利用轻量级适配器处理本体感受与手部动作。
Work的原因其实很简单:第一人称的人类数据包含了人类对物理世界丰富的潜在认知,而模型真的学习到了。
在英伟达引爆具身物理AI的赛道之前,这些讨论还没有引起国内足够的重视。这也是为什么,我们在调研国内各家方案之后,关注到了深度机智,这家早在25年第一季度就在践行同款技术路线的公司。

(二)缺失的物理常识,就在人类的“第一视角中”
回归到物理常识的认知上,有一个问题被摆在台前:为什么必须是人类的第一人称视角?
第三人称视角当然也包含一定的物理常识,但并不满足具身智能的第一性原理。使用第三人称视角的人类数据,相当于给机器人学习又上了一道枷锁 —— 从第三人称到第一人称的隐式变换。且不说学习难度大,本质上是让机器人学习在走弯路。
而早在25年初公司的筹备阶段,深度机智的研究团队就提前预判这一前瞻性的技术路线。并从成立至今,就押注用人类“第一视角”重构具身“大脑”。如今,他们已经在这个赛道上领先不止一个身位。
这种路线选择上的前瞻性,更是深度机智团队「Understanding first, Action next」的具象化表达。

1)别一直让VLA学轨迹了
低维的轨迹学习,对模型来说是“维度灾难” —— 特斯拉AI副总裁Ashok Elluswamy在ICCV上的分享。
当审视具身领域主流的做法时,我们发现:大多数方法都是在做强行映射,大量投喂各类数据,让模型强行拟合“视觉-语言-动作” 。
短期来看,从数千小时,到数万小时,再到数十万小时的真机数据配合各类其它数据,确实取得了一定的效果,但效率和上限太低了。
这就像让一只毫无文明社会常识基础的小猴子去死记硬背复杂的人类家务动作,无论重复多少遍还是无法灵活变通。
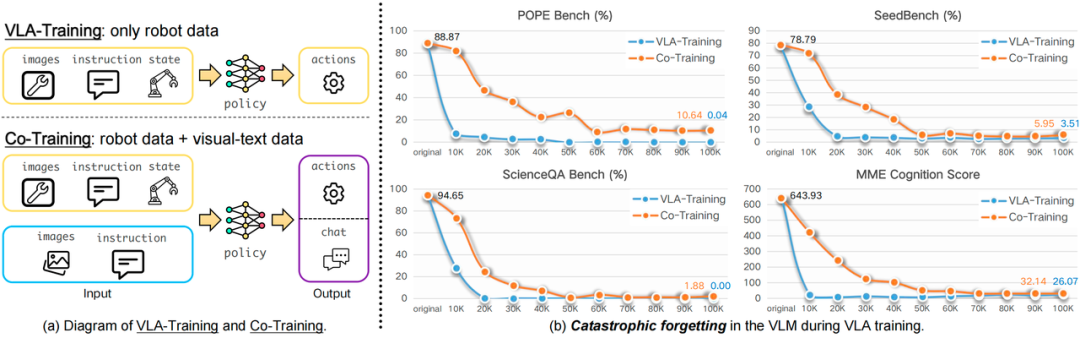
即使配备了几万小时的轨迹资产,泛化能力依然僵化。更棘手的是,单纯的动作拟合不仅无法真正理解物理规律,还会破坏大模型原有强大的通用理解能力,导致严重的灾难性遗忘。
我们也发现,不少基座模型在各类任务微调后,丧失了原有的空间语义感知能力和长程规划的能力。
顾此失彼,买椟还珠,不是具身任务真正要的。不能只抓住表象,却忽略了动作背后的物理逻辑和交互本质。
2)授人以鱼,不如授之以渔
打个比喻,当下培养孩子的方式,无论是学校还是家长,大多都已从“教科书”式的方法转变为“体验式与情境化学习”。
具身领域也一样,真正的泛化模型需要理解各种动作执行的初衷和条件,也因此,物理AI,开始逐渐被业内重视起来。
Physical AI的本质在于为具身大脑搭建起理解物理世界的底层能力,如果说 VLA 是让机器记住 “做什么”,那么物理AI的目的,就是让机器人理解 “为什么这么做”、“该怎么做才合理”。
而这正是 “授之以渔” 的关键,把真正的物理常识教给模型:模型先具备对物理世界的基础认知,再学习具体动作,才能让机器从 “模仿” 走向 “理解”,真正拥有应对未知场景的能力。
「Understanding first, Action next」,更有韵味的表达则是“谋定而后动”,这也是深度机智团队坚持推动的。
相比于其它团队,深度机智跳出轨迹拟合的「舒适圈」的时间更早。虽然痛,但取得的效果也非常惊艳:利用一千多小时的人类数据,就能轻松超越几万小时真机数据带来的模型泛化性。

3)让模型学习每一个能执行的真实动作
物理常识的学习,必须扎根于人类第一视角数据。
在这点上,深度机智和Generalist AI的观点不谋而合:第一人称视角下的人类数据,蕴藏着最丰富、最真实的物理信息,是模型学习物理世界常识的最佳样本。
物理常识,对人类而言是刻在肌肉记忆里的知识。但从第一性原理出发,要让机器人拥有物理常识,解决方案只有一个:回归真实的物理交互,让机器从体验中学习。
就像孩子学倒水,不是仅靠文字和图像描述,而是需要容器变轻、水溅到手上的感官反馈形成认知,每一个细节都会决定任务的丝滑度和最终的执行。机器人的物理常识,必须从“动作-观测-修正”的感知运动闭环中诞生。
大语言模型的发展也给了我们一个重要启示:常识能从规模中诞生,语义常识来自大规模文本,那么物理常识,就可能来自大规模、多样化的物理交互数据——但前提是,这些数据必须完整保留感知-动作的闭环,而非被割裂、被刻意规划的僵硬轨迹。
这些条件,人类视频完美地满足了:它规模巨大、成本很低并且最真实,是最理想的模型训练数据。
(三)具身需要更类人化的大脑
丰富的基础常识“锁住”在数据中后,如何把物理认知灌输给模型,就成了最需要解决的问题。算法层面上,深度机智提出了以下几个解决思路:
-
数据范式:针对人形机器人视觉不匹配的问题,需要设计连接的桥梁,把第一人称人类数据「翻译」为模型能理解的内容; -
模型架构:针对传统VLA「灾难性遗忘」和任务相斥的问题,需要设计新的模型架构; -
训练优化:针对模型泛化能力不足的问题,需要深挖训练细节,重新制定训练目标。
沿着这些思路,深度机智的团队在过去搭建出一套全栈矩阵,构成了一整套具身大脑解决方案。
1)Physbrain:具备第一人称意识的大脑
打造具备物理常识的基座模型,支持各类具身智能模型,这一点是我们一直坚持在做的,创始团队说道。
PhysBrain 是深度机智为第一人称视频数据打造的核心模型,也是机器人学习和运用物理常识的核心载体,是深度机智在探索物理AI的大胆尝试。
团队发现,业内多数方法基于第三人称视角数据进行训练,导致人形机器人存在根本性的视角不匹配问题。
为了让机器人能以 “第一人称” 视角感知和理解世界,Physbrain提出了名为Egocentric2Embodiment翻译pipeline,将第一人称人类视频数据转化为多层次、结构化的视觉问答(VQA)监督数据,构建了包含约300万样本的E2E-3M数据集,并训练得到名为PhysBrain的基座模型,并进一步用于下游大脑模型的训练。

这种基于第一人称人类数据训练得到的基座模型,让 Physbrain 能深度挖掘视频数据中海量的物理常识。PhysBrain作为VLA的基座模型,在仿真环境SimplerEnv中,PhysBrain-8B模型的任务成功率高达67.4%,超越Physical Intelligence Pi0.5和Nvidia GR00T N1.6高达10.3%。这证明了从人类第一人称视角学到的物理常识能够有效迁移道下游机器人的控制。
2)TwinBrainVLA:左脑思考,右脑执行
我们一直想解决灾难性遗忘问题,既能保留空间语义感知能力,又能学到执行的细节。
主流的具身 VLA 模型在学习动作轨迹的同时,往往会导致基座VLM模型的“灾难性遗忘”,这违背了以预训练 VLM 为基座来构建 VLA 模型的初衷。
为了在提升机器人策略学习的同时,尽可能保持基座模型的通用语义理解能力。深度机智的团队提出了TwinBrainVLA,双脑架构,非常有意思,直观、简洁并且Work!
TwinBrainVLA摒弃了主流的单脑架构,创新性使用两个大脑,引入同构但不训练的 VLM 模型作为通用「左脑」,只训练专精具身任务的「右脑」,语义理解与策略学习互斥的问题不再是僵局。 同时,还提出了全新的非对称混合Transformer(AsyMoT)机制,这种设计将保留强大通用视觉推理能力的「左脑」与专用于具身感知的可训练「右脑」相结合。「右脑」能够动态地从「左脑」获取丰富的语义知识,并将其与机器人本体感知状态融合,从而生成精确的连续控制。
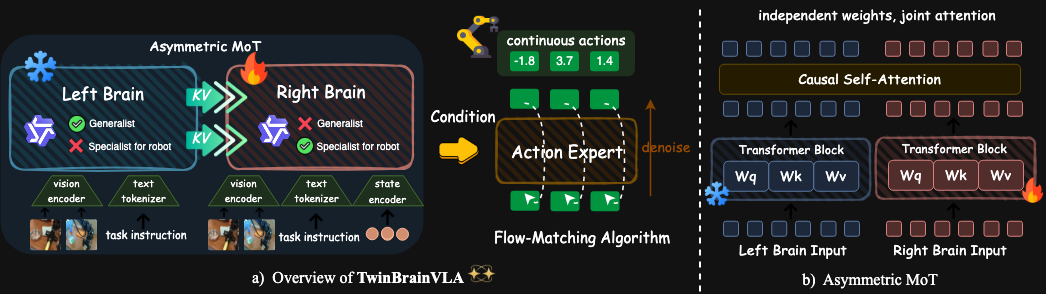
完全没有引入额外训练数据,TwinBrainVLA无痛超越pi0.5。深度机智团队彻底把基座模型的桌子掀翻了,VLA与具身的通用性问题正在被破解。这是对“模型能力聚于单一架构”这一行业惯性的挑战,证明了“分工协作”的结构可以释放更大的性能潜力。最终在SimplerEnv达到62.0%的任务成功率(4B参数规模),超越了pi0.5的57.1%。
3)LangForce:听懂指令再行动
不听指令,也是个很麻烦的事情,VLA这类模型往往会出现”视觉捷径“。
LangForce是深度机智为了解决具身模型指令跟随失效而提出的训练算法,其提出的Latent Action Queries和英伟达之后在DreamDojo提出的Continuous Latent Actions概念不谋而合。
团队发现,主流的VLA模型普遍存在「视觉捷径」的局限性,即直接跳过语言指令输出动作,即语言跟随失效导致。一旦指令稍作改变,机器人任务就会失败。
简单来说,VLA模型也会作弊、偷懒走捷径。
LangForce的提出是为了让机器人真正理解语言指令,提升机器人在OOD测试中的泛化能力,同时最大程度地保留了语言能力。
深度机智的技术团队设计了一种全新的训练框架:通过贝叶斯分解的方法,强迫机器人真正理解语言指令,提出潜在动作查询和双分支训练策略最大程度保留了具身模型对话和理解的能力。
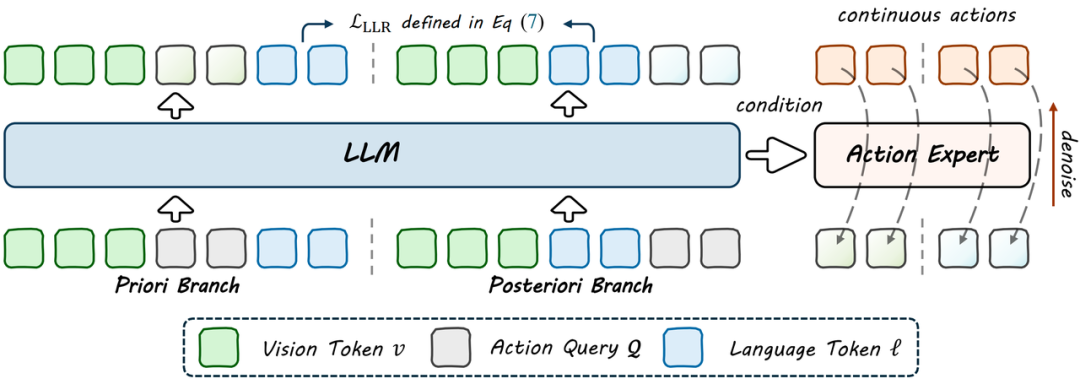
最终LangForce取得了很大突破,SimplerEnv上跨环境的OOD泛化能力大涨8.8%,综合成功率提升至66.5%,相比基线模型QwenGR00T,大幅提升了11.3%。
上述三个技术方向的突破是深度机智的算法团队融合了数据增强、双脑架构和创新微调的最新成果,也是他们践行「先理解,再行动」的最佳证明。此外,我们独家获悉:
-
三个算法融合后的模型在 SimplerEnv、RoboTwin 及 RoboCasa 等主流 Benchmark 上综合表现已超越 pi 0.5 20 多个百分点,成功登顶榜一。
在3月底的中关村论坛上,这些成果将正式开源。届时欢迎大家进一步关注~
(五)深度机智选择了“一条最接近具身通用智能的路”
那些人类具备的判断,是千百万年进化的肌肉记忆,是日复一日的感知记忆。物理常识,是迈向具身通用智能的必经之路。
抛开现象,这场革命如果仅仅是空中楼阁,注定不会牢靠,找到那个隐藏的地基,加固好才能建设的更高。
中国的具身公司,也定将在正确的路线上,越走越远。










