允中 发自 凹非寺
量子位 | 公众号 QbitAI
大模型会写论文,但它真的懂科研吗?
很多时候,AI只是在“扮演”科学家——引文献、列逻辑、排格式,看起来有模有样。但只要深究,会发现全是破绽:逻辑靠编,推导靠蒙,结论是否正确全看运气。
就在最近,此前发布过BabyVision多模态评测基准的UniPat AI,甩出了一个硬核的开源项目:
UniScientist。
这个模型参数只有30B,却可以实现“提出假设-收集证据-执行可复现的推导-迭代验证直至结论成立”这一环路的闭合。
在FrontierScience-Research和ResearchRubrics等权威科学研究榜单上,它匹敌甚至超越了参数量大一个数量级的顶尖闭源模型。

一个30B的模型,凭什么跑通复杂的科研闭环?
它的核心突破在于:将AI建模为一个动态系统。通过自主构建的数据引擎,UniPat AI成功将开放式的科研难题转化为了可验证的“单元测试”。
接下来,我们速速拆解一下UniScientist背后的逻辑。
“会写报告”不等于“会做研究”:实现流程闭环才是能力
今天很多模型做“研究任务”,只是看起来像在做科研:引用一堆资料、写一堆逻辑、格式也像论文。
但问题是:它们经常停在“叙事推理”、从“结论”出发的逻辑陷阱中,也就是说得很像,但是验证很少、推导不稳、可复现性弱。
UniPat AI在UniScientist中直接回应了这一技术缺口:仅有30B参数的UniScientist具备了“自主科学研究”的能力。
它能在开放问题里不断提出科学假设、证伪错误推论、修正研究路径,直到证据状态稳定,再把全过程沉淀为标准化的结构化科研成果。
这背后的潜台词很直白:
真正的科研,不只是把报告写漂亮,更是把“假设-证据-验证”的循环跑通。
数据瓶颈:人写得太慢,纯合成不够“真”
UniScientist首先把矛头指向了数据:如何构建高质量的科研训练数据,一直是硬瓶颈。
然而现有方案几乎只有两种极端:
-
纯人工:生态真实、判断精准,但又贵又慢,还受限于单一专家的学科边界;
-
纯合成:规模巨大、成本低,但常缺少可判别的精度和学科落地的真实性。
UniScientist的关键洞察,源于一个被广泛忽视的不对称性。
-
大语言模型更擅长生成:能跨学科大规模地提出候选研究问题和解法草案;
-
人类专家更擅长验证:鉴别研究的真伪和质量,其成本和难度远低于从零创造,且能提供高精度的专业深度校验。
这种不对称性指向了一种更高效的分工方式:模型负责规模与多样性,人类专家负责质量与可验证性。
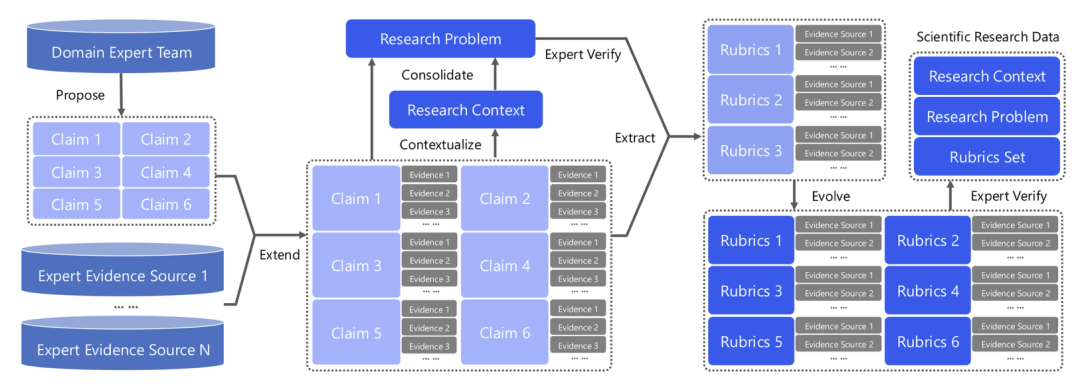
这正是UniScientist数据引擎的核心原则,即产出的训练实例既有广泛的专业覆盖面,又有严格的验证保障。
形式化科学研究:证据状态与溯因假设的动态系统
许多关于“科研智能”的讨论,都聚焦在更好的工具调用或更精准的检索上。
UniScientist则在更本质的层面展开工作,该团队将开放式科研过程建模为基于两个基本操作的动态系统:
-
主动证据整合(Active Evidence Integration)
-
模型溯因(Model Abduction)
系统的核心是一个不断演化的“证据状态”,其中证据被分为两类:
-
Evidence-Grounded(可独立核验的证据):来自外部权威来源,或内部产出但经过明确检查验证;
-
Formally-Derivable(可形式化推导/复现的证据):通过符号推导、数值计算、仿真实验等可复现程序得到。
然后系统循环执行三个动作:
-
产生假说;
-
获取外部权威信息证据、计算和推导证据;
-
做溯因更新:让假说更好解释当前证据状态。
直到证据足够完整稳定,再把整个研究过程转化成一份严谨的科学成果。
这一形式化过程具有重要意义:它能把“科研智能”从一个远大的理想,变成可训练、可评估、可迭代的对象。
把开放的科学研究问题变成“可验证的单元测试”
UniScientist提出了Evolving Polymathic Synthesis(进化式多学科合成),这是一个承担两项功能的数据引擎。
-
其首要功能是从专家验证的科学命题(Claim)出发,将其扩展为研究级课题——通过构建多个相互依赖的子问题,实现实验设计与逻辑推导的深度协同;
-
同步合成评测Rubrics。这些Rubrics不评估文风或格式等表面质量,而是评估具体的科学发现是否已被达成。
这一设计中,最具辨识度的特征是:
一份开放式科研成果被分解为N个封闭的、可独立验证的Rubric检查项。
每个Rubric item都尽量做到:原子化、客观、可证据落地或可形式化推导,并额外强调以下三点:
-
一致性(对相同科研成果,重复评测应稳定);
-
区分度(能拉开不同完整度的差异);
-
原子性(单条rubric只校验一个知识点)。
当前数据集仍在持续扩展中,已包含超过4700个研究级实例,每个实例附有20+条Rubric项,覆盖50+学科和400+研究方向。专家标注平均每条样本投入1-2小时。学科覆盖从量子物理和有机化学、到社会文化人类学和计算语言学均有涉及。

数据集中包含了具备真实科研质感的研究问题。下图展示的是一个生态学方向的示例,完整案例库可在https://unipat.ai/blog/UniScientist查阅。
这些问题的共同特征在于:没有任何一道问题,可以通过匹配记忆中的既有答案来直接解决。每一道都要求完整的科研链条——包括文献调研、假设形成、实验或推导设计、分析验证,以及最终成果的收敛。

30B小模型比肩最大规模闭源系统
UniScientist引入了一个额外的训练目标——成果聚合目标:
给定同一问题的N份候选科研成果,模型学会融合各家优点,产出一份更完整、更稳健的最终成果。通过Rubric阈值的rejection sampling来筛选高质量参考答案,聚合能力与科研生成能力一同被训入模型。
这反映了科学研究中的一个现实:对于一个问题,一次尝试并不一定会带来最好的成果。
这实际上是将“集体科研智能”写进了训练过程:模型不仅学会了产出研究,还学会了比较、取舍、整合与自我进化。
评测结果引人注目,尤其考虑到模型的规模。
UniScientist-30B-A3B(一个仅有3B激活参数的小模型),在FrontierScience-Research上达到28.3分,得分超越以下模型:
-
Claude Opus 4.5(17.5)
-
Gemini 3 Pro(12.4)
-
GPT-5.2 xhigh(25.2)
-
DeepSeek V3.2 w/tools(26.7)和Seed 2.0 Pro w/tools(26.7)
在成果聚合模式下,UniScientist得分甚至达到33.3。
而在FrontierScience-Olympiad上,启用工具的UniScientist得分为71.0,匹配Claude Opus 4.5,超越多个其他前沿模型。
更是在多项分布外的基准——DeepResearch Bench、DeepResearch Bench II和ResearchRubrics上,UniScientist的表现与一系列顶级闭源系统实力相当。
一个尤为重要的发现:即使在无工具的评测条件下,性能仍有显著提升。
这表明增益并非单纯来自更频繁的工具使用,模型自身的研究推理能力确实通过训练得到了增强。
以上所有基准上的结果,均指向同一结论:模型学会的不只是更好地检索,而是将检索、推导、验证和写作整合为连贯的研究工作流。

UniScientist的下一步:迈向现实世界实验
科学研究不止于形成一个合理的叙事,许多结论依赖于可执行、可复现的计算与仿真。
UniScientist集成了代码解释器,将研究流程从叙事式推理升级为“测试-修正”的循环:假设不仅被提出,还被实例化为计算实验——其结果可以确认、推翻或细化假设。
系统目前的能力主要集中在可复现推理与仿真计算范围内。
目前,系统尚未实现对真实世界研究资源的编排,包括大规模GPU任务的可靠调度、以及湿实验流程的协调。
在Blog中,UniScientist也将下一步方向阐述得很清晰:
将框架扩展到对真实实验与计算基础设施的受控编排与执行,目标是进一步加速科学发现、推动研究前沿。
以下展示一个UniScientist进行的完整科研推理链条,详细推理内容可以在Blog链接中进行查阅。

开源地址:
https://github.com/UniPat-AI/UniScientist
Blog:
https://unipat.ai/blog/UniScientist







![[人物] 梓瑶:从开源爱好者到 RISC-V SoC Maintainer 的破界之路](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-09/69aeb7482f07f.jpeg)
