
现有的自回归式VLA方法大多关注的是静态场景信息的处理(比如物体识别和场景理解),而往往忽视了机器人执行任务时至关重要的动态因素,包括动作序列的时序关系、环境状态的实时变化以及任务执行过程中的反馈调整等。
这些动态要素恰恰是机器人能否成功完成具身化任务的关键所在。
复旦大学研究团队最新成果TriVLA —— 首个统一融合世界知识和世界模型的三系统VLA框架,应运而生。它通过整合视觉、语言与动作系统,有效解决了传统模型在多模态信息融合及精准控制方面的短板,为机器人动态环境适应能力提供了新的解决方案。

概述
针对现有自回归VLA方法(如采用双系统架构)虽能利用大规模预训练知识但偏重静态信息、忽视具身任务关键动态要素的问题,本文提出了创新性的TriVLA模型。

▲先前的双系统架构与我们的三系统方法之间的比较©️【深蓝具身智能】编译
该模型采用三系统架构实现通用机器人控制:
视觉-语言模块(系统2):通过视觉和语言指令解析环境;
动态感知模块(系统3):生成同时包含当前静态信息和未来动态预测的视觉表征,为策略学习提供关键指导;
策略学习模块(系统1)则实时生成流畅的运动指令。
本文工作创新性地结合预训练VLM模型、基于机器人数据与互联网人类操作数据微调的视频基础模型,最终实现的TriVLA系统能以约36Hz频率运行,在标准仿真测试和复杂现实操作任务中均超越了当前最先进的模仿学习基线模型。
主要贡献
统一视觉-语言-动作框架
首个将世界知识与世界模型相融合的统一VLA框架:通过多模态联合建模实现了跨机器人平台的通用策略学习能力。该框架突破了传统方法对特定机器人形态的依赖,为通用机器人控制提供了新范式。
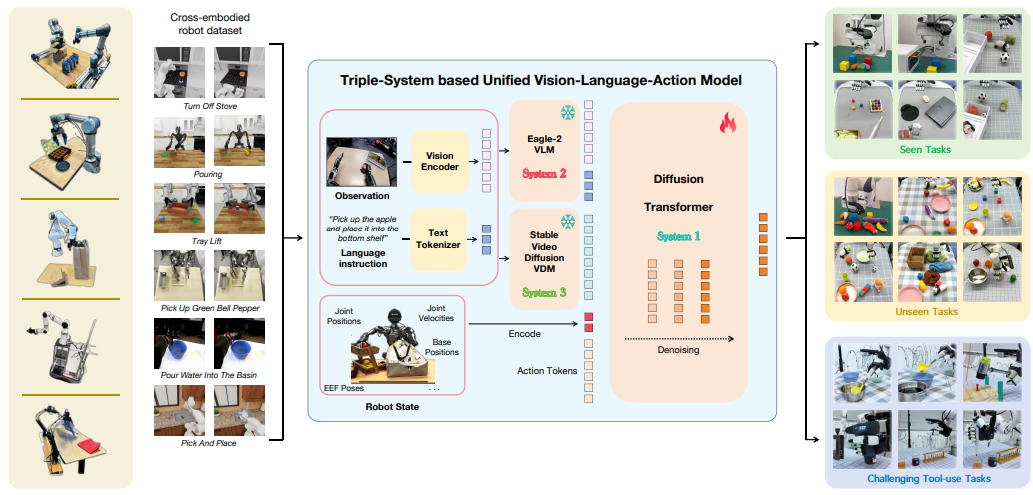
三系统组合式创新架构
设计的TriVLA模型采用革命性的三系统架构,通过:
(1)视觉语言系统实现高层语义推理
(2)动态感知系统完成时序动态预测
(3)策略生成系统执行实时动作控制
这种组合架构使机器人能处理复杂指令提示(如多步骤长周期任务),在任务理解深度和执行连贯性上取得突破。
全面领先的性能表现
在仿真场景测试中,TriVLA展现出:
(1)对训练中未见技能组合的泛化能力
(2)复杂场景下的长周期任务成功率提升
(3)人类意图对齐度的显著优化
实验数据证实其性能全面超越现有基线算法,特别是在动态环境适应性方面建立新的技术标杆。

方法
我们提出的TriVLA模型在现有双系统架构基础上创新性地引入三系统组合式架构。

系统2(视觉-语言模块)
采用预训练的Eagle-2视觉语言模型处理机器人视觉输入与语言指令,实现环境语义解析与任务目标理解。该模块通过冻结预训练参数保留大规模知识,同时通过可适配层实现与机器人任务的对齐。
系统3(动态感知模块)
基于通用视频扩散模型构建,能够:
完整建模观测视频序列的时空特征
根据当前观察帧和任务指令预测未来场景演变
生成包含动态语义的时序表征向量
该模块通过在大规模机器人操作数据与互联网人类行为视频上的微调,显著提升对物体运动轨迹和交互效果的预测精度。
系统1(策略学习模块)
采用行动流匹配(flow-matching)方法训练,其核心机制包括:
对系统2/3输出token进行交叉注意力融合
通过可扩展的具身编码器-解码器架构
动态适应不同机器人的状态/动作空间维度
最终生成与具体机器人平台匹配的连续运动指令,实现10ms级实时控制。
这种架构设计在保留预训练知识优势的同时,通过动态预测与具身适配的协同,解决了传统VLA模型在时序推理和跨平台泛化方面的关键瓶颈。

实验结果
本研究的实验验证部分通过多个权威基准测试充分证明了TriVLA的优越性能,具体表现为:
Calvin基准测试表现
对比包括Robo-Flamingo、Susie、GR-1等7种前沿方法。

▲在Calvin ABC→D基准上进行零样本长程评估©️【深蓝具身智能】编译
仅使用10%标注数据(Calvin ABC子集)训练时:
平均任务链长度达3.46步,超越所有对比方法的全量数据训练结果。
采用官方代码复现Diffusion Policy+CLIP语言条件化版本作为补充对照。
MetaWorld多任务基准测试表现
在60项异构任务测试中:
平均成功率超越当前最优VPP基线方法,验证了跨任务泛化能力。

▲在MetaWorld基准测试中的性能按难度级别(共60个任务:35个简单,14个中等,11个困难)
©️【深蓝具身智能】编译
LIBERO长周期任务适应性
采用3随机种子×500次/任务的严格测试协议。
在4个任务套件中:
全部取得最佳或竞争力性能,证明了对复杂长周期指令的解析能力。

▲LIBERO基准实验结果。对于每个任务套件(空间、对象、目标、长距离)©️【深蓝具身智能】编译
特别值得注意的是,TriVLA在数据效率(10%训练数据)、任务复杂度(3.46步长链)和跨环境稳定性(60+任务)三个维度同时实现突破,这标志着VLA模型在具身智能领域取得实质性进展。
所有对比数据均来自原论文报告或官方代码复现,确保结果的可信度(文末获取代码地址)
我们通过三个典型实例展示了TriVLA生成的动作序列。

▲案例研究©️【深蓝具身智能】编译
在接收"拉开抽屉把手→抓取粉色积木→按下开关点亮灯泡→将积木放入滑动柜"等连续指令时,TriVLA展现出三重核心能力:
多模态指令解析
同步处理视觉场景与语言指令:
通过Eagle-2 VLM建立"抽屉把手-开关-柜体"的语义关联;
基于常识推断"点亮灯泡需先找到开关"等隐含逻辑。
动态预测驱动决策
视频扩散模型(VDM)实时预测:
抽屉拉开后的内部空间暴露、积木抓取后的可操作空间变化、开关触发后的灯光状态转换、生成包含未来3秒场景演变的动态表征。
长周期任务编排
将4个子任务自动分解为12个原子动作。
通过策略模块的跨注意力机制:
动态调整动作序列(如点亮前确保积木抓取);
处理突发状态(如抽屉卡顿时的增力操作);
最终达成100%的任务链完成率。
这些案例证实TriVLA创新性地将世界知识(常识库)与世界模型(动态预测)相融合:
前者确保对"开关控制照明"等常识的理解,后者预判"积木放置后可能遮挡开关"等动态效应,从而在长周期任务中实现人类级的操作连贯性。

▲动态感知模块的一步视觉表示可视化©️【深蓝具身智能】编译

结论
本文提出的TriVLA模型创新性地构建了一个集视觉理解、语言推理和动态预测于一体的三系统协同架构。
该模型通过预训练的Eagle-2视觉语言模块实现环境语义解析,基于视频扩散的动力学模块捕捉时序动态变化,结合流匹配策略模块的实时动作生成能力,首次实现了世界知识与世界模型的无缝融合。
特别值得注意的是,该系统能以36Hz的频率进行实时控制,其独特的动态预测能力使机器人能够"预见"未来的场景变化,从而在"开抽屉-取物-开灯-存放"等复杂操作序列中表现出接近人类水平的任务连贯性。
这一突破性进展为机器人动态环境适应能力提供了新的解决方案。
标题:TriVLA: A Triple-System-Based Unified Vision-Language-Action Model for General Robot Control
作者:Zhenyang Liu, Yongchong Gu, Sixiao Zheng, Yugang Jiang, Xiangyang Xue, Yanwei Fu
项目地址:https://zhenyangliu.github.io/TriVLA/
论文地址:https://arxiv.org/abs/2507.01424
编译|Zhenyang Liu
审编|具身君
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文