大家好,今儿介绍监督学习和无监督学习!
面试过的同学,你们的第一个问题是什么,我当年校招问的第一个问题就是这个!
咱们今天详细信息的总结一下有监督和无监督算法的区别和联系!!
监督学习和无监督学习是机器学习中两种基本的学习范式,它们之间的主要区别在于训练数据的标签信息是否提供。
监督学习(Supervised Learning):
标签信息: 监督学习使用带有标签的训练数据。这意味着每个训练样本都有一个相关联的标签,即对应的输出或目标值。 任务类型: 监督学习用于解决分类和回归等任务。在分类任务中,模型预测输入数据属于哪个类别;而在回归任务中,模型预测一个连续值。 学习过程: 模型通过学习输入与相应标签之间的关系来进行训练。算法通过最小化预测值与实际标签之间的差距来优化模型。 例子: 支持向量机(SVM)、决策树、神经网络等都是监督学习的例子。
无监督学习(Unsupervised Learning)
标签信息: 无监督学习使用没有标签的训练数据。训练样本不包含对应的输出或目标值。
任务类型: 无监督学习用于聚类、降维和关联规则挖掘等任务。在聚类任务中,算法试图将数据集中的样本分为不同的组;在降维任务中,算法试图减少数据的维度;在关联规则挖掘中,算法试图找到数据中的关联性。
学习过程: 模型在没有明确目标的情况下,自动发现数据中的结构和模式。它不需要事先知道正确的输出。
例子: K均值聚类、主成分分析(PCA)、Apriori算法等都是无监督学习的例子。
区别
数据标签: 监督学习使用带有标签的数据,而无监督学习使用没有标签的数据。
任务类型: 监督学习用于分类和回归等有标签任务,而无监督学习用于聚类、降维和关联规则挖掘等无标签任务。
学习过程: 监督学习侧重于模型预测与真实标签的关系,而无监督学习侧重于发现数据中的模式和结构,不依赖事先提供的输出信息。
监督学习算法示例
支持向量机(Support Vector Machine,SVM) 支持向量机是一种用于分类和回归分析的监督学习算法。其基本思想是找到一个超平面,该超平面能够将数据集划分为两个类别,并且使得两个类别之间的间隔最大。支持向量机在高维空间中通过数据点之间的最优超平面进行划分,从而在低维空间中实现非线性分类。
给定一个训练样本集 ,其中 是特征, 是类别标签(+1 或 -1),SVM 的目标是找到一个超平面 ,使得对于所有的 ,有 。
此外,要最大化间隔 。
完整代码
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 生成示例数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只使用前两个特征,便于可视化
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM模型
svm_model = SVC(kernel='linear', C=1)
svm_model.fit(X_train, y_train)
# 绘制决策边界和支持向量
def plot_decision_boundary(model, X, y):
h = .02 # 步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('SVM Decision Boundary')
plt.show()
# 绘制决策边界和支持向量
plot_decision_boundary(svm_model, X_test, y_test)
使用了Iris数据集的前两个特征,创建了一个线性核的支持向量机模型,并绘制了决策边界以及支持向量。图形展示了SVM是如何找到一个最大间隔的超平面来分割不同类别的数据点的。

无监督学习算法
K均值聚类(K-Means Clustering)
K均值聚类是一种迭代优化的聚类算法,其目标是将数据集划分为K个簇,每个簇内的数据点相似度较高,而不同簇之间的相似度较低。算法的基本思想是通过迭代更新数据点与簇中心之间的距离,将数据点分配到距离最近的簇,然后更新每个簇的中心。
完整代码
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 生成示例数据集
X, y = make_blobs(n_samples=300, centers=4, random_state=42, cluster_std=1.0)
# 可视化原始数据
plt.scatter(X[:, 0], X[:, 1], c='gray', s=50, alpha=0.8)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Original Data')
plt.show()
# 创建K均值聚类模型
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
# 获取簇中心
centers = kmeans.cluster_centers_
# 预测每个数据点的簇标签
labels = kmeans.predict(X)
# 可视化K均值聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.8)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200, label='Cluster Centers')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-Means Clustering')
plt.legend()
plt.show()
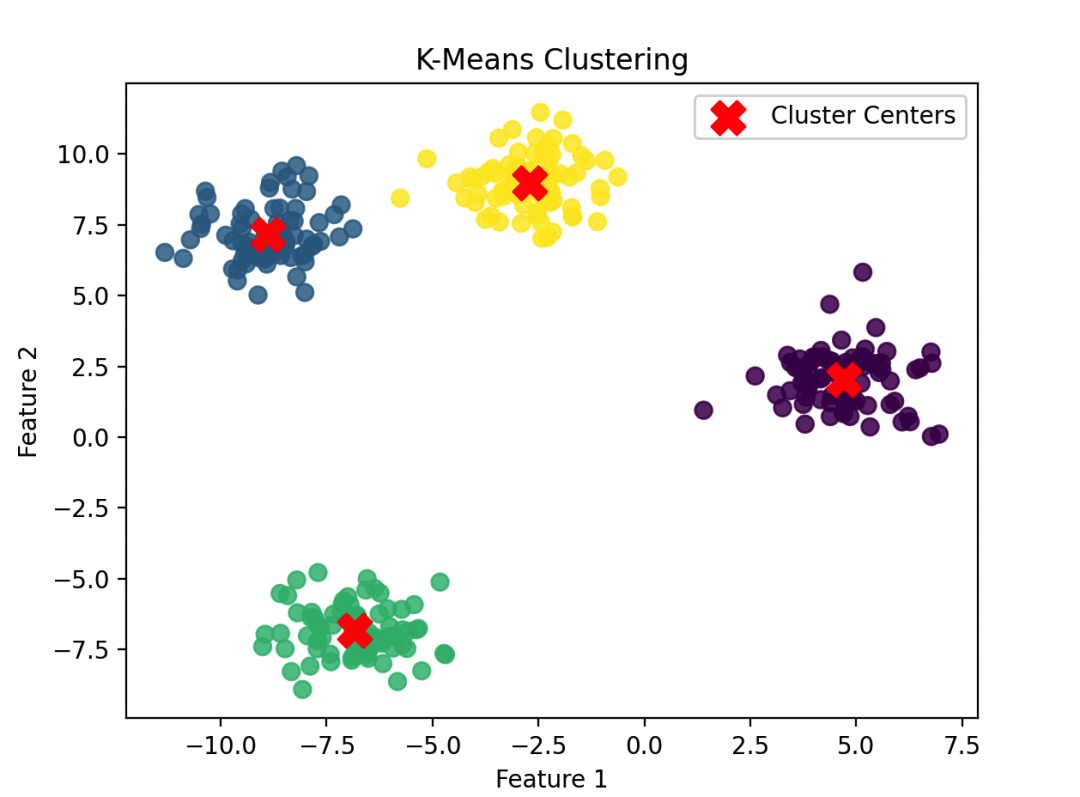
我们使用make_blobs生成一个包含4个簇的合成数据集。
然后,使用K均值聚类算法将数据点分为4个簇,并绘制了原始数据和K均值聚类的结果。
图形清晰地展示了K均值聚类是如何将数据点分组为具有相似特征的簇的。
最后


