
一直以来,高性能 Search Agent 都像是 “大厂的专属游戏”。虽然业界涌现了许多开源模型,但真正决定 Agent 能力上限的 “高质量训练数据” 却始终被各大企业严格保密,形成了一道坚固的数据护城河。这种持续的数据稀缺,极大地阻碍了广大研究社区在这一领域的创新与发展。
今天,由上海交通大学研究团队推出的 OpenSeeker 彻底打破这一现状!
作为首个纯学术团队打造,完整开源模型 + 100% 全量训练数据的前沿深度搜索 Agent,OpenSeeker 证明了:不靠堆砌算力资源,依靠极高的数据合成质量,学术界同样能跑出 SOTA!在同等条件下(约 30B 参数量、纯 ReAct 架构),OpenSeeker 仅需 11.7k 合成样本进行单轮 SFT(监督微调),便在多个前沿榜单上取得了 SOTA 成绩。

GitHub: https://github.com/rui-ye/OpenSeeker
全量训练数据: https://huggingface.co/datasets/OpenSeeker/OpenSeeker-v1-Data
模型权重: https://huggingface.co/OpenSeeker/OpenSeeker-v1-30B-SFT
Huggingface Paper: https://huggingface.co/papers/2603.15594
论文直达: https://arxiv.org/pdf/2603.15594
核心亮点速览
纯学术团队打造,打破大厂垄断:完全开源所有训练数据(QA + 轨迹)和模型,为研究人员提供高质量数据基础,无需依赖企业级规模资源,也能探索与构建下一代 Search Agent。
跨榜单 SOTA,越级挑战强化学习模型:在 BrowseComp-ZH 榜单上取得 48.4% 的成绩,直接超越了阿里 Tongyi DeepResearch 通过采用 CPT(持续预训练)、SFT(监督微调)和 RL(强化学习)多轮复杂训练得出的 46.7%。在约 30B 级纯 SFT 模型中,全面斩获第一(BrowseComp 29.5 /xbench 74.0 / WideSearch 59.4)
核心技术揭秘:
突破大厂数据瓶颈的高质量数据合成方案
要有效训练深度搜索 Agent,核心在于解决两个关键问题:首先,必须构建足够高难度的问答任务,以激发模型“推理 → 工具调用 → 工具反馈”的多轮工具调用能力,从而形成包含明确决策节点和长工具调用链的长程交互轨迹;其次,需要通过稳定且可复现的方法生成高质量解题轨迹,确保训练信号学习到的是正确且可泛化的策略,而非依赖随机采样产生的偶然成功。
为此,OpenSeeker 进一步提出基于真实网页结构的事实锚定问答构建与动态去噪轨迹合成方法,以系统性提升多跳推理能力与信息提取能力。
1. 基于事实锚定的问答构建:基于真实网页图谱构造高难度多跳问题

现有的检索任务往往容易被模型通过简单的模式匹配 “走捷径”。为了逼迫模型进行真正的多跳推理,OpenSeeker 直接从海量真实网页的图结构出发进行逆向工程。
从随机种子页面出发进行拓扑图扩展,寻找互联的信息簇并提取出实体子图。
引入实体混淆机制,将具体实体模糊化,把简单的事实转化为复杂的推理谜题。
OpenSeek QA 合成的方法,不仅保证了数据的真实可信,还从结构上强制模型必须进行多步导航与深度推理。
2. 动态去噪轨迹合成:基于非对称上下文构建,强化嘈杂环境下的核心信息提取

真实的网页环境充满了冗长且无关的噪音。为了合成高质量的动作轨迹,OpenSeeker 设计了一套非对称的 “动态上下文去噪” 策略:
生成阶段(Teacher):引入回顾性总结机制,将上一步的嘈杂工具返回结果压缩为干净摘要,让 Teacher 模型在无噪的上下文中生成专家级的推理和工具调用。
训练阶段(Student):在训练时撤掉摘要,给模型喂入原始的、未经压缩的嘈杂工具返回结果,倒逼其预测 Teacher 的高质量决策
该方法激发 OpenSeeker 从嘈杂的真实网页环境中学习到了强大的信息提取与去噪能力。
实验结果:11.7k 数据的越级挑战
11.7k 数据单轮 SFT,媲美大厂表现:OpenSeeker 仅使用 11.7k 样本和 SFT 进行单轮训练,便展现出媲美甚至超越大厂资源密集型模型的竞争力。令人瞩目的是,在 BrowseComp-ZH 榜单上,仅采用单轮简单 SFT 训练的 OpenSeeker-v1-30B-SFT 取得了 48.4% 的高分,超越经历了持续预训练 (CPT)、SFT 和强化学习 (RL) 多阶段训练的 Tongyi DeepResearch (46.7%)。
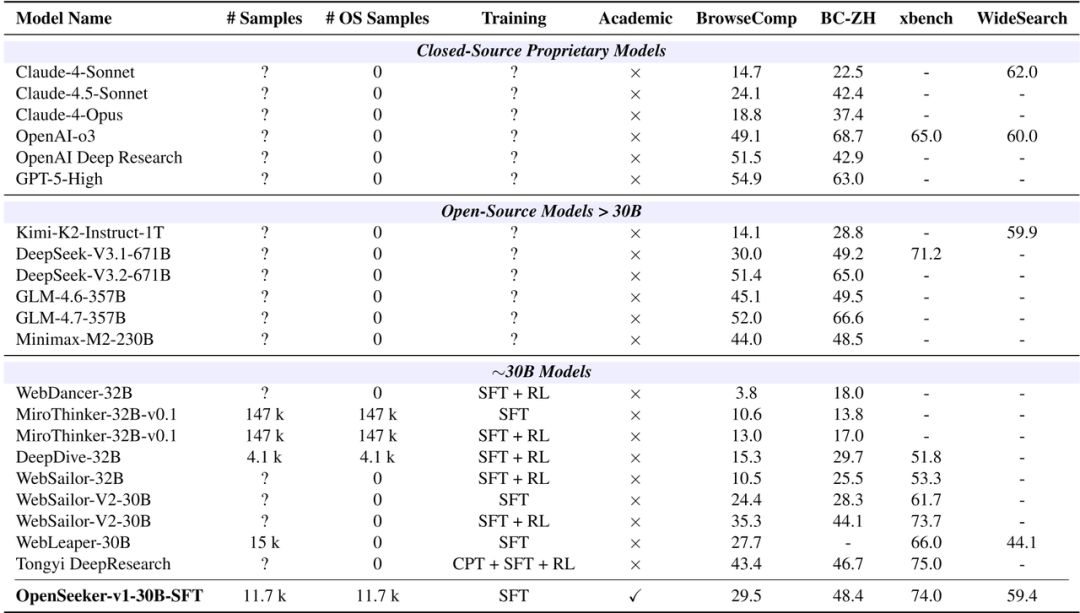
纯 SFT 与 ReAct 架构下的 SOTA 表现:在同为 SFT 训练的 ReAct Agent 竞争中,OpenSeeker 取得 SOTA。仅凭借 11.7k 数据,OpenSeeker 在 BrowseComp (29.5)、BrowseComp-ZH (48.4)、xbench (74.0) 和 WideSearch-EN (59.4) 四大榜单上均取得最优成绩,显著拉开了与阿里巴巴通义实验室提出的 WebSailor-V2、WebLeaper 等同类开源模型的差距。

同等数据规模下的显著优势,凸显极高数据质量:在控制数据量规模可比的情况下(10k-15k 级别),OpenSeeker 的数据质量明显优于阿里巴巴通义实验室的 WebSailer-V2 和 WebLeaper 的各类组合版本,在各项指标上均保持显著优势。

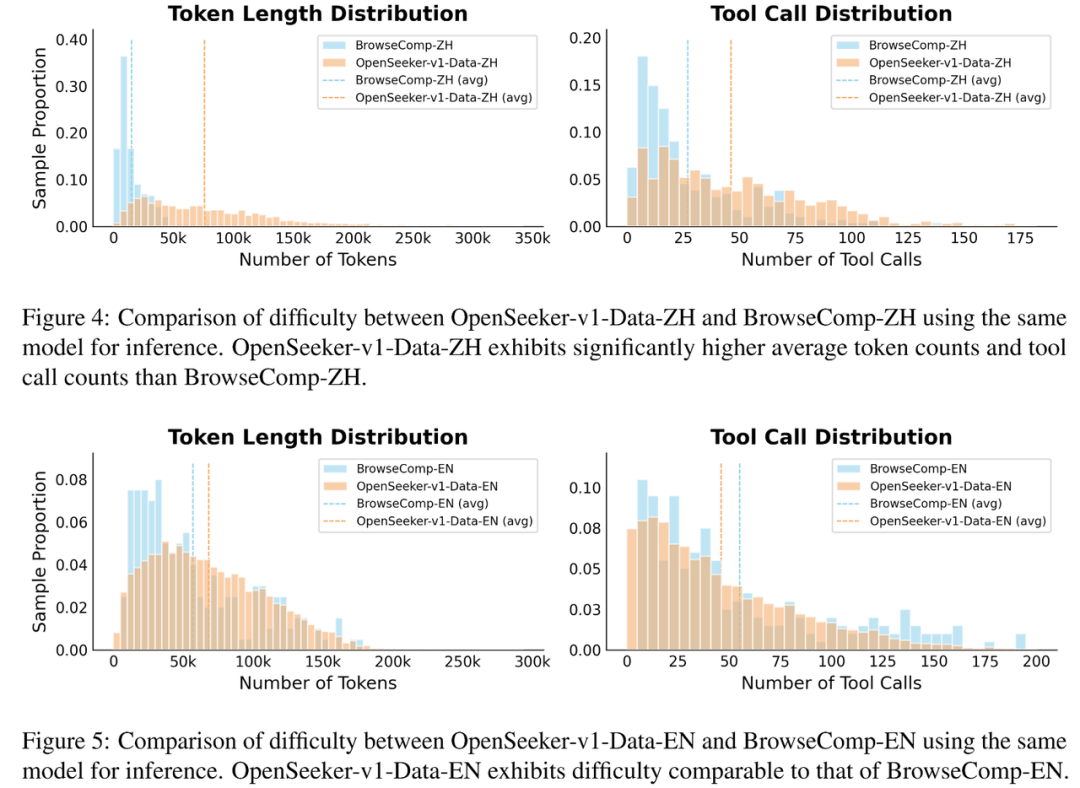
远超 Benchmark 的数据难度:为了量化数据难度,研究团队使用相同的模型对合成数据和标准 Benchmark 进行了推理对比。结果显示:
合成的中文数据难度远超 BrowseComp-ZH:每条轨迹平均需要进行 46.35 次工具调用,平均 token 长度高达 76.1k;而 BrowseComp-ZH 分别仅为 26.98 次和 15.1k tokens。
英文数据的难度也达到了与 BrowseComp-EN 相媲美的水平。
社区反响:真正推动领域发展的底层开源支撑
OpenSeeker 一经发布,便在海外社交平台和开源社区引发了热烈反响。许多研究者与开发者纷纷表示,这正是目前学术界最迫切需要的破局之作:

明确科研与数据的边界:“这才是真正能推动领域发展的开源发布。全量训练数据加上 30B 模型,让研究人员终于能区分出,性能的提升到底是来自真正的方法创新,还是仅仅因为吃了闭源数据的红利。”
打破数据垄断:“现在,大家终于可以在没有‘数据守门人’限制的情况下,自由构建多步智能体了!”
呼唤已久的透明度:“AI Agent 终于迎来了数据透明,太令人振奋了!”、“开源再次胜利!”
这不仅是一个 SOTA 模型,更是赋能整个学术界探索下一代 Search Agent 的坚实基座。
全面开源,即刻体验!
OpenSeeker 作为首个由纯学术团队打造、模型与全量训练数据完全开源的深度搜索 Agent,从根本上打破了长期以来由大厂构筑的数据护城河,真正为科研人员提供了可直接使用、可复现、可扩展的高质量研究数据基础。这一开放不仅降低了前沿 Search Agent 研究的门槛,更让研究者能够专注于方法创新本身,而不再受限于数据。打破闭源垄断,让前沿研究不再遥不可及。也期待更多开发者与研究者加入,共同探索下一代 Agent 的可能性,欢迎 Star 关注并上手体验!
作者介绍:
本文共同第一作者为上海交通大学博士生杜钰文与叶锐,其中叶锐为项目负责人,指导老师为上海交通大学人工智能学院陈思衡教授,主要研究方向为 AI Agents、Agentic Science 等领域。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










