如今,大语言模型已经彻底改变了自然语言处理领域,成为从对话助手到代码辅助等应用的核心引擎。然而,随着用户交互内容日益丰富,涵盖图像、视频、音频等多种模态,AI领域正经历一场深刻的范式转变。
ChatGPT、Gemini和Copilot等平台已广泛采用多模态大语言模型,它们不仅能处理文本,还能进行图像推理、视频摘要和音频字幕生成等复杂任务。
然而,与传统仅处理文本的LLMs不同,MLLMs引入了额外的推理阶段。如图1所示,多模态输入在到达LLM后端之前,需要经过视觉预处理和编码。这些额外步骤显著增加了推理的延迟和内存占用。

从架构上看,MLLM内部包含一个传统LLM,负责处理这些嵌入表示。推理过程分为两个阶段:Prefill阶段一次性或分块处理整个输入提示,而Decode阶段则以自回归方式逐个生成输出令牌。
Decode阶段虽然计算强度不如Prefill,但由于使用KV缓存来存储初始提示和已生成令牌以避免重复计算,因此对内存要求极高。KV缓存的大小可能急剧增长,甚至触及GPU内存的上限。
02 资源需求的“数量级”鸿沟
为了深入理解服务多模态LLM面临的独特挑战,来自西班牙马德里 IMDEA 软件研究所的研究人员对代表性的开源模型和多种工作负载进行了详细表征,重点关注它们在资源需求和性能方面与传统纯文本LLM推理的差异。

论文标题:Rocks, Pebbles and Sand: Modality-aware Scheduling for Multimodal Large Language Model Inference
论文链接:https://arxiv.org/pdf/2603.26498
研究团队从多个数据集中随机选取了数千个请求,在无竞争条件下顺序执行,分别测量了KV缓存内存占用和首令牌时间等关键指标。
内存占用方面,图2a显示,不同模态之间的内存占用存在数个数量级的差异。纯文本请求虽然高度多样化,但在所有模型中始终保持在较轻水平。
相比之下,图像请求通常需要10²到10³个令牌,而视频请求可能超过10⁵个令牌,特别是对于Qwen-7B模型。图像请求的近乎垂直线反映了视觉编码器使用的固定分词(fixed tokenization)策略。

延迟方面,图2b显示TTFT延迟在不同模态间也存在数量级差异。纯文本请求最快,通常在0.01秒左右,在所有模型中始终低于1秒。
图像请求的延迟略高,一般在1秒内完成,而视频请求最为耗时,范围在1到10秒之间。这些不同的模式揭示了一个清晰的层次结构:视频主导延迟,其次是图像,而纯文本请求则保持极快的速度。
研究发现,包含视觉模态的请求在空间和时间上存在数量级差异:视频需求最高,图像次之,这使得传统的纯文本请求显得极其轻量。这些特征在不同多模态模型之间保持一致。
03 “先来先服务”的失效
在对每个模态进行单独表征后,研究人员进一步考察了它们在现实工作负载下的综合影响。使用先进的方法论,团队评估了传统的纯文本工作负载和新兴的多模态混合工作负载。
研究发现,多模态工作负载彻底改变了推理性能。传统的纯文本工作负载实现了毫秒级的归一化延迟和TTFT,几乎没有SLO违规,这表明当前的推理系统对当今主流的LLM工作负载进行了高度优化。
然而,随着引入视觉模态,整体性能急剧恶化:轻量混合已经增加了延迟并引入了违规,而重量混合则导致显著的减速和超过60%的SLO违规。

文本请求受到的影响最大:尽管它们轻量且对延迟敏感,但归一化延迟增加了数量级,并主导了违规计数,严重程度达到超过15秒,这对于聊天机器人等交互式应用来说是不可接受的延迟。
这种性能下降的原因是资源密集型的图像和视频请求在Prefill阶段垄断了GPU内存和计算资源,造成了严重的队头阻塞,使较小的文本请求陷入停滞。
这些效应直接源于视觉模态在时间和空间上的主导地位,视频和图像比文本需要多几个数量级的内存和时间。尽管有分块Prefill优化,但图像和视频的Prefill时间和内存开销如此之大,以至于迫使轻量文本请求等待时间远远超过其延迟目标。
04 内存压力下的性能雪崩
接下来,研究人员评估了内存约束如何影响多模态推理——当托管更大模型或在重负载下使KV缓存容量紧张时,这种情况就会出现。
为了研究这种效应,团队逐步将可用于KV缓存的内存减半,并测量了在重量混合工作负载下文本、图像和视频请求的推理性能。图4报告了随着内存减少,每种请求类型的归一化延迟、TTFT、SLO违规和严重程度。
减少可用于KV缓存的内存对多模态推理产生了戏剧性影响。随着内存减少,归一化延迟和TTFT急剧上升,SLO违规激增,在最低内存设置下达到90%,表明系统完全饱和。
文本和图像请求受到的影响最大:它们的SLO违规率攀升至70-90%,严重程度超过40秒,这对于聊天机器人等交互式应用来说是不可接受的。在紧张的内存预算下,大型视频请求可能垄断KV缓存,为其他请求留下很少空间,并导致严重的队头阻塞。

研究发现,有限的内存可用性使多模态推理变得更加困难。当KV缓存容量受限时,像视频这样的资源密集型请求会垄断内存,导致严重的队头阻塞。这放大了为传统LLM和同质工作负载设计的现有解决方案的局限性。
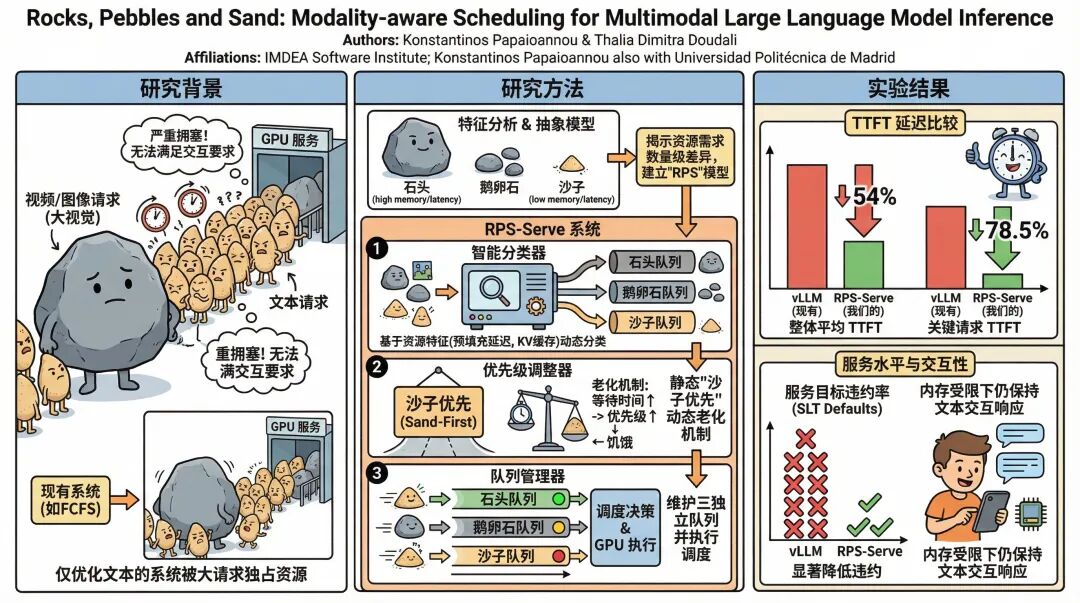
05 “岩石、鹅卵石和沙子”的智慧
为了克服现有系统的局限性,IMDEA软件研究所和西班牙马德里理工大学的研究团队提出了一种模态感知调度框架,明确考虑多模态请求的异构资源需求。
他们引入了RPS-Serve服务系统,通过一个简单而强大的抽象概念来实施这些见解。在多模态工作负载中,不同模态之间的资源需求和时间要求存在数量级差异:视频请求表现得像岩石,主导时间和内存;图像请求是鹅卵石,中等重量;而纯文本请求是沙子,轻量但对延迟敏感。
RPS-Serve利用这种分类来优先处理沙子的响应性,同时减轻鹅卵石和岩石的饥饿问题。
岩石、鹅卵石和沙子的概念源自时间管理实践,这些实践提倡首先优先处理大型任务。团队的关键见解是将这一原则反转用于多模态推理:不是首先调度最大的请求,而是优先处理最小且对延迟最敏感的请求,这些请求通常具有很短的SLO。

较大的请求,如图像和视频,它们主导时间和内存,以受控方式稍后调度。通过将这种既定的优先级概念适应于多模态推理,RPS-Serve让沙子快速流过鹅卵石和岩石。
RPS-Serve的设计遵循两个目标:延迟关键型调度,优先处理对延迟敏感的请求,以最小化推理延迟并在多模态竞争下提供交互式响应;饥饿感知调度,防止资源密集型请求饥饿,同时不损害沙子的优先响应性,在所有模态间提供平衡的推理。
为了实现这些目标,RPS-Serve首先使用元数据和基于性能分析模型来估计每个传入请求的时间和空间影响。基于这些估计,请求被分为三类,并放置到单独的队列中,使每个类别能够进行不同的管理。
06 智能分类与动态调节
RPS-Serve从跨队列的静态优先级顺序开始:沙子优先,其次是鹅卵石,然后是岩石,同时在每个队列内保持先来先服务顺序。为了防止饥饿现象的发生,RPS-Serve加入了老化机制,逐渐增加等待请求的优先级,确保资源密集型请求最终能够取得进展,同时保持沙子的优先响应性。
在每个调度迭代中,RPS-Serve评估所有队列的状态,并动态调整优先级以选择下一批请求。这个决策可能涉及接纳新请求、重塑批次或在必要时抢占正在进行的请求,因为新请求的Prefill时间可能主导批次延迟。
通过持续重新审视优先级,RPS-Serve使对延迟敏感的沙子请求能够快速执行,同时不牺牲跨模态的整体进展。
RPS-Serve系统的核心组件包括:工作负载分析器,为跨文本、图像和视频的多模态模型构建离线性能配置文件;影响估计器,估计传入请求的时间和空间影响;请求分类器,基于影响估计器提供的延迟和内存估计将请求分类为岩石、鹅卵石或沙子。
队列管理器,为岩石、鹅卵石和沙子维护三个独立的队列,跟踪队列级指标,并随后强制执行优先级调节器确定的顺序;优先级调节器,在每个迭代中评估所有队列并更新优先级以选择下一批。

请求分类器是RPS-Serve的核心,因为它实现了岩石-鹅卵石-沙子抽象,并实现了模态感知调度。为了使这种抽象成为现实,需要识别哪些请求是岩石、鹅卵石和沙子;换句话说,必须将传入的请求分类到这三个类别中。
研究人员首先尝试了一种“朴素”分类,基于模态分配请求:文本是沙子,图像是鹅卵石,视频是岩石。这种方法既不准确也不通用,因为它假设所有文本请求都很小,所有图像或视频都很大。
实际上,长文本提示可能匹配图像的资源需求,而短视频可能类似于图像。此外,它忽略了模型家族之间的差异,限制了对新模态和不断变化的工作负载特征的适应性。
为了克服这些限制,团队设计了一个智能分类器,它依赖于资源感知特征而不是粗糙的模态标签。具体来说,它使用影响估计器估计的Prefill延迟和KV缓存占用作为输入特征。
利用工作负载分析器的性能分析数据,研究人员为每个MLLM训练了一个轻量级聚类模型,根据其资源配置文件将请求划分为三个类别。在运行时,分类器为每个传入请求构建特征向量,并将其分配到最合适的类别,确保分类反映时间和空间影响。
07 性能验证与压倒性优势
为了验证RPS-Serve的有效性,研究团队进行了全面的评估,展示了其满足系统目标的能力:为沙子请求提供延迟关键型调度,为鹅卵石和岩石提供饥饿感知调度。
评估涵盖了以下维度:与其他基线的端到端性能比较,以及对RPS-Serve的深度敏感性研究。这些实验共同提供了对RPS-Serve在加速多模态LLM推理方面有效性的全面评估。
实验环境包括一台配备NVIDIA A100 GPU、两个AMD EPYC 7313 16核处理器和256GB主机DRAM内存的服务器。使用的模型包括LLaVA、Gemma、Qwen和Pixtral等先进多模态模型,参数数量从500M到12B不等。

数据集方面,团队使用了三个广泛采用的数据集来捕捉多样化的多模态用例。ShareGPT包含基于文本的常规聊天对话,LLaVA-Instruct专注于图像推理,LLaVA-Video针对视频描述。
工作负载方面,研究人员使用了最近对生产系统中多模态推理流量的表征提供的多模态工作负载。每个请求包含来自其相应数据集的一个输入:文本提示、单个图像或单个视频。请求到达遵循泊松分布,与LLM工作负载建模中的常见做法一致。
团队评估了三种工作负载混合:TO、ML和MH。这种设计允许在控制到达模式和模态组成的同时,隔离增加多模态强度对性能的影响。
基线方面,研究人员评估了端到端推理性能与以下基线的对比:vLLM,使用分块Prefill优化的最先进LLM推理服务系统;EDF,LLM服务系统中旨在最小化端到端延迟的最先进基于优先级的调度方法;RPS-Serve,团队提出的模态感知调度解决方案,构建在vLLM之上。
图10比较了在MH工作负载下,RPS-Serve与具有分块Prefill的vLLM和最早截止时间优先跨最先进多模态模型的平均性能。首先关注沙子请求,RPS-Serve始终实现最低的归一化延迟或与EDF匹配,而vLLM在所有模型中表现最差。

对于TTFT,RPS-Serve在所有模型中始终提供低于1秒的延迟,满足商业平台对聊天机器人等交互式应用的响应性目标。相比之下,vLLM除了Gemma-4B外,对所有模型都未能达到这个目标,而EDF对Pixtral-12B的表现尤其差。这些结果证实了RPS-Serve通过优先处理沙子请求并确保对延迟关键型请求的响应性来实现目标。
对于鹅卵石,与vLLM相比,RPS-Serve也提供了一致较低的延迟,并且与EDF相比延迟较低或相当。岩石,正如预期的那样,受到更重的惩罚;它们有时比其他基线慢,因为RPS-Serve故意牺牲它们的性能来加速沙子。这种权衡是故意的,表明RPS-Serve实现了目标。
为了更深入地了解RPS-Serve如何实现其设计目标,图11显示了跨基线的抢占次数和请求被抢占的总时间。具有分块Prefill的vLLM主要对沙子请求引入抢占,这些请求被饱和内存的鹅卵石和岩石中断。
EDF基于截止时间积极抢占请求以优先处理即将到期的请求,几乎同等次数地中断沙子和岩石,岩石花费更多时间被抢占,因为它们不是延迟关键的。相比之下,RPS-Serve完全消除了沙子的抢占,以确保响应性,并减少了整体抢占延迟。

接下来,研究人员在增加负载下比较了RPS-Serve与vLLM和EDF,这是一个重要的压力测试,因为现实世界的服务系统必须在竞争下优雅地扩展。图12报告了随着请求率增长,整体归一化延迟、平均TTFT和P90 TTFT。
vLLM在多模态竞争下扩展性差。其FCFS调度和分块Prefill优化无法处理图像和视频的大资源占用,导致在强烈负载下延迟急剧增加。EDF通过基于截止时间重新排序请求表现更好,但在高负载下其尾部延迟接近vLLM,揭示了其在多模态场景中的局限性。
相比之下,RPS-Serve即使在峰值请求率下也保持低延迟,将TTFT保持在几秒钟内,并显著减少尾部延迟。
这些结果突显了vLLM的分块Prefill无法处理多模态引入的数量级更大的Prefill。EDF虽然是截止时间感知的,但不是模态感知的,错过了进一步加速沙子并确保响应性的机会。相比之下,RPS-Serve提供了与传统LLM服务相当的延迟关键性能,有效地隐藏了多模态,同时确保多模态请求不会饥饿。
08 广泛适用性与未来展望
在建立了RPS-Serve在端到端性能上始终优于最先进基线的基础上,团队接下来在不同条件下进行了更深入的分析。
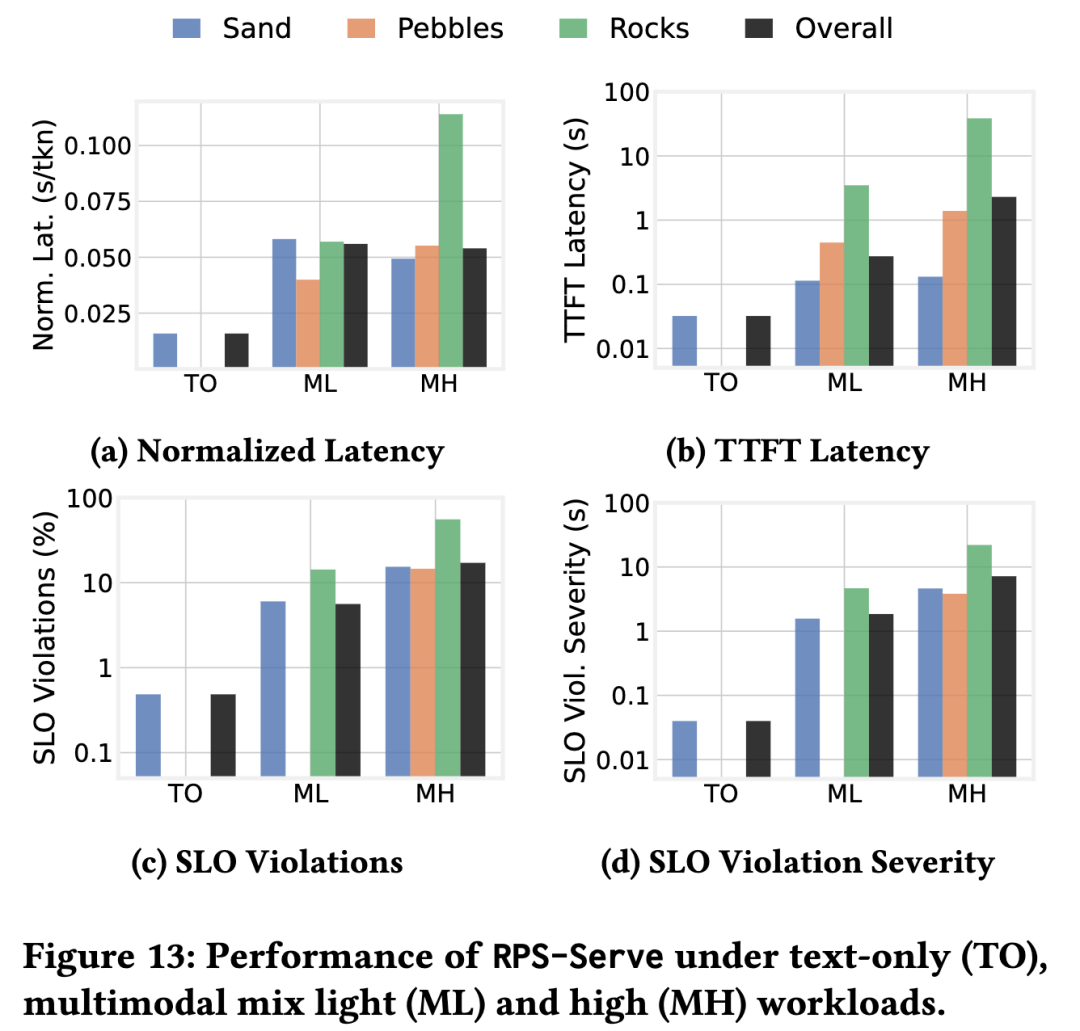
图13显示了RPS-Serve在不同工作负载下的性能。在轻量和重量多模态混合下,系统为延迟关键的沙子请求提供了强大的响应性,实现了高达0.15秒的平均TTFT延迟,并将SLO违规保持在15%以下,违规严重程度限制在仅几秒钟。
这些数字与商业平台对聊天机器人等交互式应用的响应性目标一致。鹅卵石也表现良好,TTFT小于1.5秒,而岩石仍然最慢,正如给定其资源强度和系统设计目标所预期的那样。
最重要的是,RPS-Serve在传统的纯文本工作负载下表现出色,实现了0.05的平均TTFT和小于0.5%的SLO违规。这证实了RPS-Serve不仅是多模态推理的解决方案,也是服务传统LLM工作负载的稳健选择。
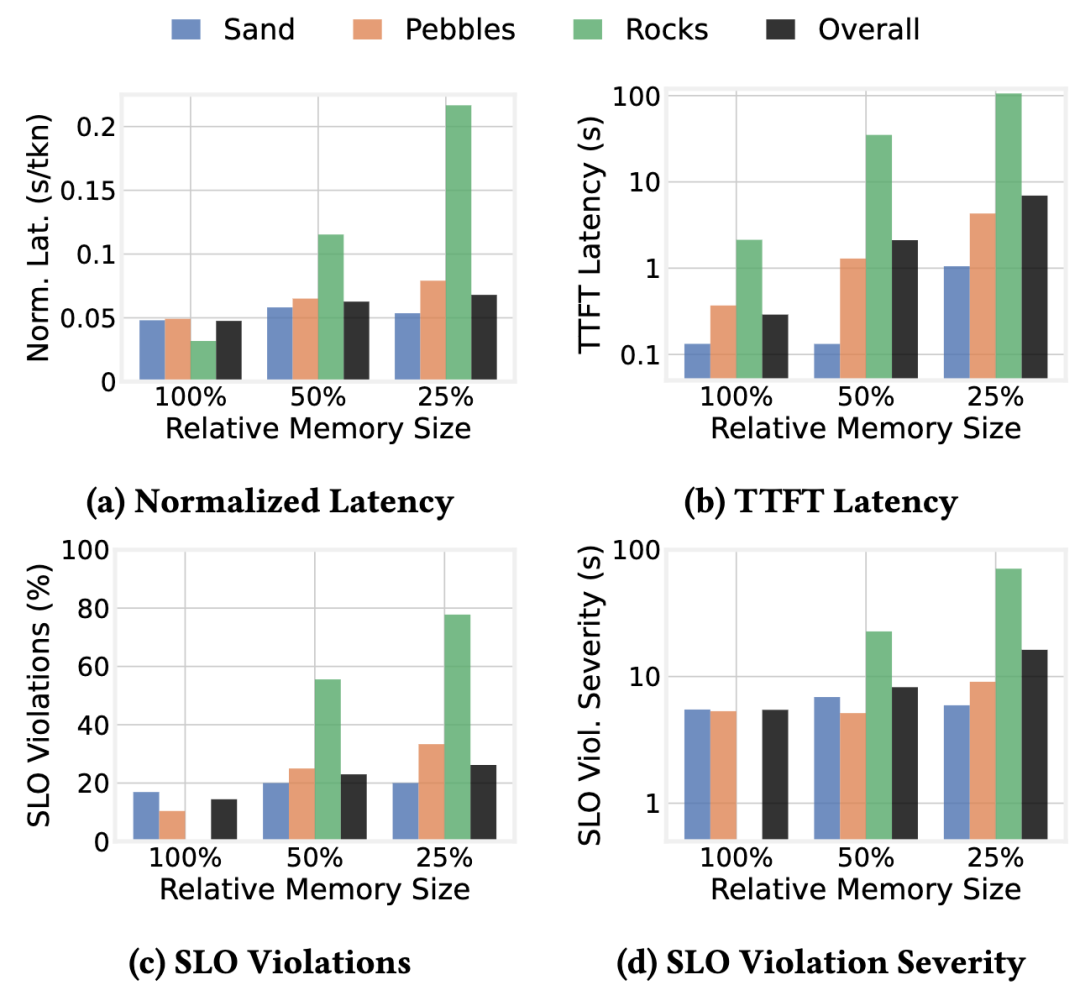
图14报告了在逐步减少KV缓存内存大小下RPS-Serve的性能。在所有配置中,RPS-Serve为沙子请求保持了低延迟和最小的SLO违规,即使当内存减少到其原始大小的25%时,也将平均TTFT保持在1秒以下。
鹅卵石表现出适度的退化,而岩石在紧张的内存预算下受到的影响最大。在极端情况下,单个岩石可能垄断剩余的缓存,严重影响整体性能。总体而言,这些结果证实了RPS-Serve为延迟关键的沙子请求保留了响应性,即使在严重的内存约束下也提供了与传统LLM服务相当的性能。

图15显示了在不同SLO尺度下RPS-Serve的性能,其中较高的值表示更宽松的SLO。团队报告了三个指标:违规率、违规严重程度和良好吞吐量,即系统在满足指定SLO的同时可以维持的最大请求率。
随着SLO变得更加宽松,所有模态的违规率和严重程度都下降,而良好吞吐量增加,因为更多请求在目标延迟内完成。相对顺序保持一致:沙子由于丰富性和快速执行实现了最高的良好吞吐量,鹅卵石逐渐改善,而岩石由于其资源强度仍然受到最大限制。
总体而言,对于广泛采用的SLO,RPS-Serve为沙子提供了交互式响应性,为鹅卵石和岩石提供了平衡的进展,证实了其优雅适应不同服务级别要求的能力。
虽然RPS-Serve显著改善了多模态推理性能,但它目前仅支持文本、图像和视频模态。团队的沙子-鹅卵石-岩石抽象足够通用,可以包括其他模态,但这样做可能需要重新训练分类器并重新审视优先级调节。
未来工作包括支持多模态输出生成,并将RPS-Serve扩展到任意到任意多模态模型,而不仅仅是MLLMs。最后,RPS-Serve目前在单节点设置中运行;扩展到多GPU或多节点集群可能会引入与模型分区和节点间网络相关的新性能行为。
09 总结
RPS-Serve的推出标志着多模态大模型服务领域的一个重要里程碑。通过将时间管理中的“岩石、鹅卵石和沙子”概念创新性地应用于系统调度,研究团队成功解决了多模态工作负载中的资源竞争和队头阻塞问题。
该系统不仅显著提升了延迟敏感型请求的响应速度,还确保了资源密集型请求不会因饥饿而无法完成,在多模态AI应用日益普及的今天,这种平衡显得尤为重要。
随着AI技术不断向多模态方向发展,类似RPS-Serve这样的系统级优化将变得越来越关键。它不仅为当前的多模态模型提供了更高效的服务方案,也为未来更复杂的“任意到任意”模态转换模型奠定了基础。
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --










