点击下方卡片,关注“具身智能之心”公众号
作者丨x
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
提出背景与核心问题
视觉-语言-动作模型凭借其强大的语义理解和跨模态泛化能力,已成为通用型机器人代理研发的核心驱动力。这类模型依托预训练的视觉-语言backbone网络,能够解读抽象指令并在多种任务中展现出优异的泛化性能。然而,现有VLA模型在接触密集型场景中存在显著短板——难以将决策精准扎根于物理现实,尤其在需要精细力控制的交互任务中表现乏力。
造成这一局限的关键原因在于触觉感知的缺失。与视觉和语言提供的高层语义信息不同,触觉感知能传递物理交互中丰富、局部且动态的反馈,如摩擦、柔顺性和材料特性等,这些信息对涉及接触的操作任务至关重要。尽管已有研究尝试将触觉纳入机器人系统,但多将其视为补充性感知模态,未能真正实现与决策过程的深度融合。
针对这一问题,Tactile-VLA旨在通过深度融合视觉、语言、动作与触觉感知,激活VLA模型中隐含的物理知识,实现接触密集型任务中的精准力控制与泛化能力。

更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

核心创新与研究目标
1)关键发现
研究团队的核心发现是:视觉-语言模型(VLM)的先验知识中已包含对物理交互的语义理解。通过少量演示将这种知识与机器人的触觉传感器连接,即可激活该先验知识,使机器人在接触密集型任务中实现零样本泛化。这一发现打破了传统认知中“VLM仅能处理抽象语义”的局限,为物理交互场景的语义接地提供了新思路。
2)主要创新点
Tactile-VLA框架:首次将触觉感知作为原生模态引入VLA模型,构建视觉、语言、动作与触觉的深度融合架构,实现从抽象语义到物理力控制的直接映射。 混合位置-力控制器:创新性地将力目标转化为位置调整指令,在保证运动精度的同时实现对接触力的精细控制,解决了位置与力控制的协同难题。 Tactile-VLA-CoT变体:引入思维链(CoT)推理机制,使机器人能基于触觉反馈分析失败原因并自主调整策略,显著提升复杂场景中的稳健性。
3)主要解决的问题
旨在实现三大能力:
触觉感知的指令遵循:让机器人理解“轻柔地”“用力地”等与力相关的语言修饰词,弥合抽象意图与物理执行的差距。 触觉相关常识的运用:使机器人能基于物体属性(如重量、易碎性)自主调整交互力,无需显式指令。 触觉参与的自适应推理:通过分析触觉反馈诊断任务失败,自主制定纠正策略,实现复杂场景的稳健操作。
Tactile-VLA框架
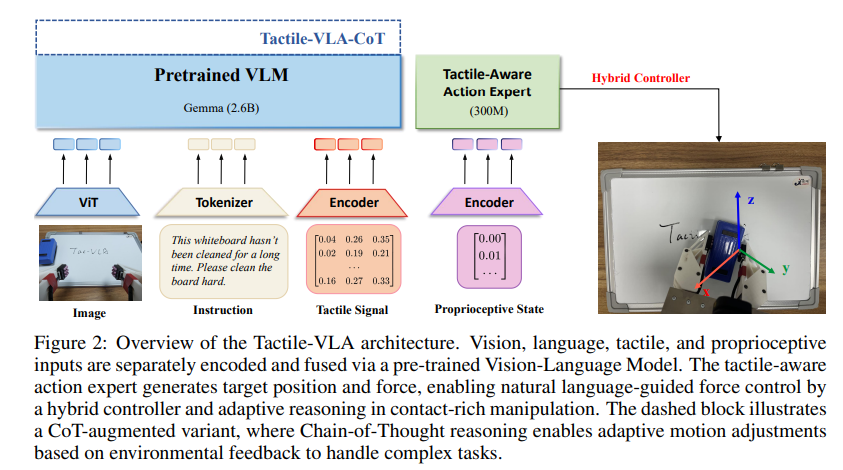
1)整体架构
Tactile-VLA的核心设计理念是多模态深度融合,其架构包含四个关键模块:
多模态编码器:分别处理视觉、语言、触觉和本体感觉输入,将其转化为统一的token表示。其中,视觉信息通过预训练的视觉Transformer(ViT)编码,触觉信号通过MLP编码器处理时间序列特征,语言则由通用tokenizer转换。 Transformer backbone网络:对融合后的多模态token进行跨注意力计算,构建包含视觉场景、语言指令和触觉反馈的上下文表征。 触觉感知动作专家:基于上下文表征生成包含目标位置和目标力的动作向量,直接指导物理交互。 混合位置-力控制器:将动作向量转化为机器人可执行的控制指令,平衡位置精度与力控制需求。
这一架构的关键在于token级融合——通过非因果注意力机制使视觉、语言和触觉token自由交互,形成真正扎根于物理现实的语义表征。
2)混合位置-力控制机制
为解决位置与力控制的协同问题,Tactile-VLA设计了创新的混合控制策略:
控制逻辑:以位置控制为主,仅在力误差超过阈值时引入力反馈调整,公式如下:

其中ΔF为目标力与实测力的差值,K为增益矩阵,τ为触发阈值。
双通道分离:将外部净力(通过机械臂笛卡尔位置控制)与内部抓取力(通过夹爪宽度控制)分离,实现力的精细化调节。
这种设计既保证了操作任务所需的位置精度,又能在接触阶段实现柔顺的力控制,特别适合USB插拔、物体抓取等接触密集型场景。
3)思维链推理机制(Tactile-VLA-CoT)
为提升机器人在复杂场景中的自适应能力,Tactile-VLA-CoT引入了基于语言的推理过程:
触发机制:按固定间隔评估任务进展,当检测到失败时启动推理。 推理流程:
判定任务成功与否(如“黑板未擦干净”); 分析失败原因(如“法向力不足”); 生成纠正指令(如“增加下压力度”)。
这一机制使机器人的适应过程从“黑箱式调整”转变为“可解释的推理”,显著提升了复杂任务中的鲁棒性。
4)数据收集方法
为获取高质量的触觉-语言对齐数据,研究团队构建了专用数据采集系统:
硬件平台:基于通用操作接口(UMI),配备双高分辨率触觉传感器,可同时采集法向力和剪切力。 同步机制:将100Hz触觉信号与20Hz视觉数据时间对齐,确保多模态数据的时空一致性。 标注方式:由人类操作员结合触觉反馈提供演示,同时记录与力相关的语言指令(如“轻柔插入”),构建VLA-T训练数据集。
这种数据采集方式解决了传统遥操作中“力反馈缺失”的问题,为模型学习语言与力的映射关系提供了关键支撑。
实验验证与结果分析
研究团队设计了三组实验,分别验证Tactile-VLA在指令遵循、常识运用和自适应推理三方面的能力,对比模型包括π₀-base、π₀-fast(两种VLA基线模型)以及Tactile-VLA-CoT(带推理机制的变体)。
1)触觉感知的指令遵循实验
任务设计:
任务A(USB插拔):训练机器人理解“轻柔地”“用力地”等指令,学习力与语言的映射关系。 任务B(充电器插拔):仅训练基本动作,不提供力相关指令,测试模型的零样本泛化能力。
结果分析:
成功率:Tactile-VLA在USB任务中达到35%,充电器任务中达90%,显著高于基线模型(最高40%)。 力控制精度:在USB任务中,模型对“轻柔地”施加0.51N力,对“用力地”施加2.57N力;在零样本的充电器任务中,仍能保持力的区分度(“轻柔地”4.68N vs “用力地”9.13N),而基线模型的力输出与指令无关。
这表明Tactile-VLA真正学习到了与力相关语言的语义内涵,并能跨任务泛化。

2)触觉相关常识的运用实验
任务设计:
训练:让机器人学习对三类物体(坚硬沉重、坚硬轻便、易碎轻便)施加适当抓取力。 测试:评估模型在域内物体(训练见过)和域外物体(训练未见过)上的表现。
结果分析:
成功率:Tactile-VLA在域内物体抓取中成功率达90%-100%,域外物体中达80%-100%,显著高于基线模型(尤其在易碎物体上,基线成功率接近0)。 力调节策略:模型能根据物体属性自主调整力度——对坚硬沉重物体用大力,对易碎物体用轻力,即使是未见过的物体(如火龙果、蓝莓)也能正确判断。
这验证了模型能将VLM中的常识知识(如“易碎物体需要轻拿”)与触觉感知结合,实现跨物体泛化。

3)触觉参与的自适应推理实验
任务设计:
训练:在白板上学习擦拭动作,包含成功案例和因力不足导致的失败案例。 测试:零样本迁移到黑板擦拭任务(需要更大力度),评估模型的失败诊断与纠正能力。
结果分析:
成功率:Tactile-VLA-CoT在黑板任务中成功率达80%,而基线模型和Tactile-VLA(无推理)分别为0和15%。 推理过程:模型首次尝试用3.5N力擦拭失败后,通过推理得出“需要更大剪切力”,自主将力增加到6.7N并成功完成任务,展现出类似人类的问题解决能力。
这证明思维链推理机制能有效激活模型对物理交互的理解,使其在新场景中突破训练数据限制。


参考
[1] TACTILE-VLA: UNLOCKING VISION-LANGUAGEACTION MODEL’S PHYSICAL KNOWLEDGE FOR TACTILE GENERALIZATION.
