智东西4月24日报道,今日,DeepSeek正式发布并开源DeepSeek-V4系列预览版本,这是其继V3.2之后的新一代旗舰模型体系,智东西第一时间上手实测。
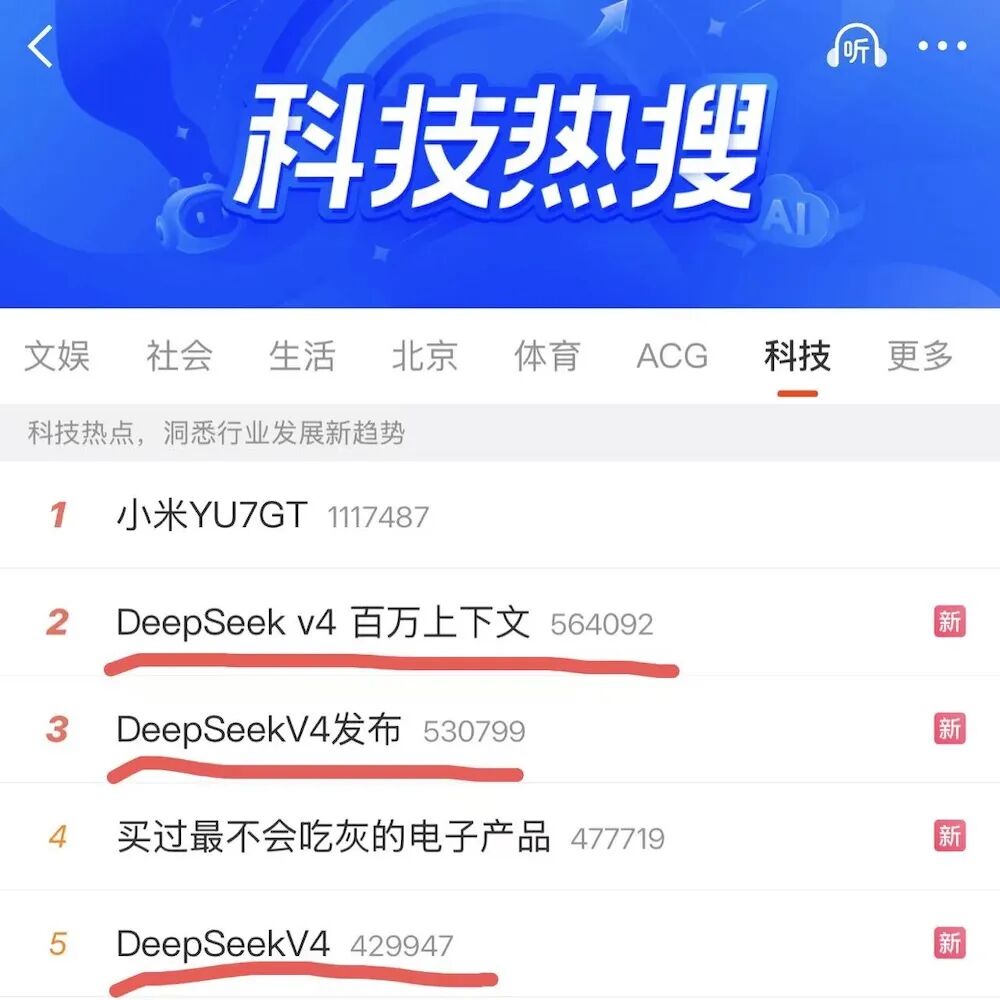
DeepSeek V4“源神”回归影响力果然不同凡响,几乎瞬间刷屏,在微博热搜榜前五占三,仅次于小米YU7GT。
本次发布包含两款模型:DeepSeek-V4-Pro与DeepSeek-V4-Flash,分别采用MoE架构,总参数规模达到1.6T(激活49B)与284B(激活13B),并统一支持最长100万token上下文。
DeepSeek官方同时说明,受限于高端算力,目前DeepSeek-V4-Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,其价格会大幅下调。此外,DeepSeek-V4已获得寒武纪Day 0适配支持,相关适配代码已开源至GitHub社区。
DeepSeek-V4-Pro主打性能上限,对标闭源旗舰模型;而DeepSeek-V4-Flash则在参数规模与激活规模上大幅缩小,换取更低延迟与更低成本。
相比上一代模型,其在Agent能力、世界知识与复杂推理任务上进一步抬升,并首次将“百万上下文”作为默认能力开放。
在Agent能力方面,DeepSeek-V4-Pro的Agent能力显著增强。其在Agentic Coding等评测中进入开源第一梯队,内部评测显示交付质量已接近Claude Opus 4.6非思考模式,但与其思考模式仍存在差距。
DeepSeek-V4-Pro在数学、STEM及竞赛型代码等高难度任务中已超过当前已公开评测的开源模型,整体表现接近甚至比肩GPT-5.4、Claude Opus 4.6-Max等顶级闭源模型。
与此同时,DeepSeek-V4在长上下文效率上给出了一组更激进的优化:在100万token场景下,其单token推理计算量仅为V3.2的27%,KV Cache占用降至约10%,显著降低长链路任务的算力与显存成本。
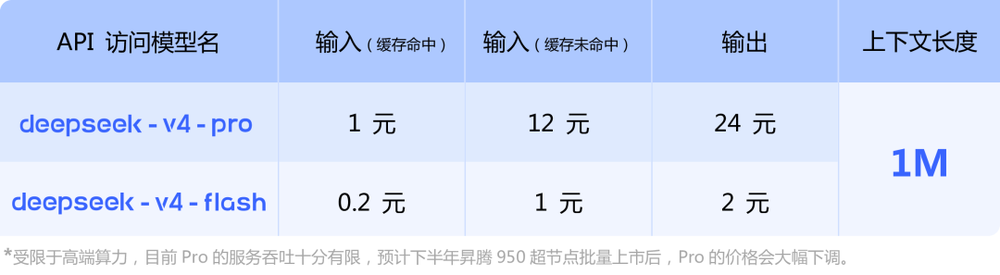
同时,官方公布了DeepSeek-V4系列的API定价:DeepSeek-V4-Pro在输入命中缓存的情况下为1元/百万tokens,输入未命中缓存则为12元/百万tokens,输出为24元/百万tokens;DeepSeek-V4-Flash在输入命中缓存仅0.2元/百万tokens,未命中输入1元/百万tokens,输出2元/百万tokens。
目前,DeepSeek-V4系列已上线官网与App,并同步开放API与模型权重。
chat.deepseek.com或DeepSeek官方APP
https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
我们初步感受了下DeepSeek-V4的变化,主要测试的模型是DeepSeek-V4-Pro。
在前端网页one-shot案例中,DeepSeek-V4-Pro展现出很高的执行效率。由于我们的需求不复杂,模型仅用了5秒钟进行思考,之后迅速进行开发,这与之前DeepSeek模型在思考上浪费很多token的模式明显不同。
进入到实际生成过程后,DeepSeek-V4-Pro的输出长度要明显长于其他DeepSeek模型。其生成速度较快,基本能做到以5行代码为单位输出。
最终,DeepSeek-V4-Pro的生成结果如下,可以看到其网页的完成度要比DeepSeek-V3.2高一些,设计更为丰富。
▲DeepSeek-V4-Pro打造的网站
https://mcp.edgeone.site/share/9pD1cRzY1QA8bmmBLDZ8S
不过,这样简单的编程题目已经难不住DeepSeek-V4-Pro,我们试着让它完成一个结合Agent能力与编程的任务:规划一次去上海的旅行,然后把所有相关信息整合为一个旅行网站,附上对应的景点定位。
执行过程中,可以看到DeepSeek-V4-Pro可以进行复杂多轮工具调用,联网搜索的条目数量也和之前模型的数量相比有增加,信息收集得更为全面了。
最终,DeepSeek-V4-Pro收集到了完整的行程信息,规划合理,并且配上了每个景点的定位,点开后就可以直接在导航App里使用,十分便捷。在Agent任务中,可以观察到它的行动十分果断,工具调用、思考都在几秒钟内解决,token效率不错。
▲DeepSeek使用Agent能力和编程能力规划的旅行方案旅行方案
https://mcp.edgeone.site/share/4TxFYOy24bgaEwxFoxisj
我们的下一个案例与长文本有关,DeepSeek-V4系列模型常常挂在嘴边的就是它能一口气吃下《三体》三部曲,而我们如它所愿上传了完整的《三体》。
上传这样的超长文件后,DeepSeek能够迅速定位我们指定的内容,成功实现大海捞针。不过,这种超长上下文能力是有代价的,仅仅输出这一点内容就烧掉了54万个token。
我们还用“OpenAI更新到了哪一个模型”这一问题,试了试模型的知识截至日期,可以看到,DeepSeek-V4-Pro的知识截止日期目前仍然停在2025年。
此外,这一模型应该暂时还不支持视觉能力,上传图像后还是会进行文字提取,没有文字的图像会显示无法处理。
这一代V4最直接的变化,是把“长上下文”变成默认能力。
不同于传统通过简单扩展窗口的方式,DeepSeek-V4-Pro引入了全新的混合注意力架构,将Compressed Sparse Attention与高压缩注意力(HCA)结合,同时配合DSA稀疏注意力,在token维度进行压缩。
此外,模型引入了流形约束超连接(mHC)增强传统残差连接,并使用Muon优化器提升收敛速度和训练稳定性。这一系列设计,使得模型在“记得更长”的同时,有效控制计算成本。
从官方给出的数据来看,在100万token上下文下,DeepSeek-V4-Pro单token推理TFLOPs相比DeepSeek-V3.2下降约3.7倍至9.8倍区间,KV Cache占用下降9.5倍至13.7倍。
这意味着,过去难以实际运行的超长链路任务(如多轮Agent规划、长文档处理),开始进入可执行范围。
从能力结构来看,DeepSeek-V4-Pro的提升是推理、知识与Agent能力的同步抬升。
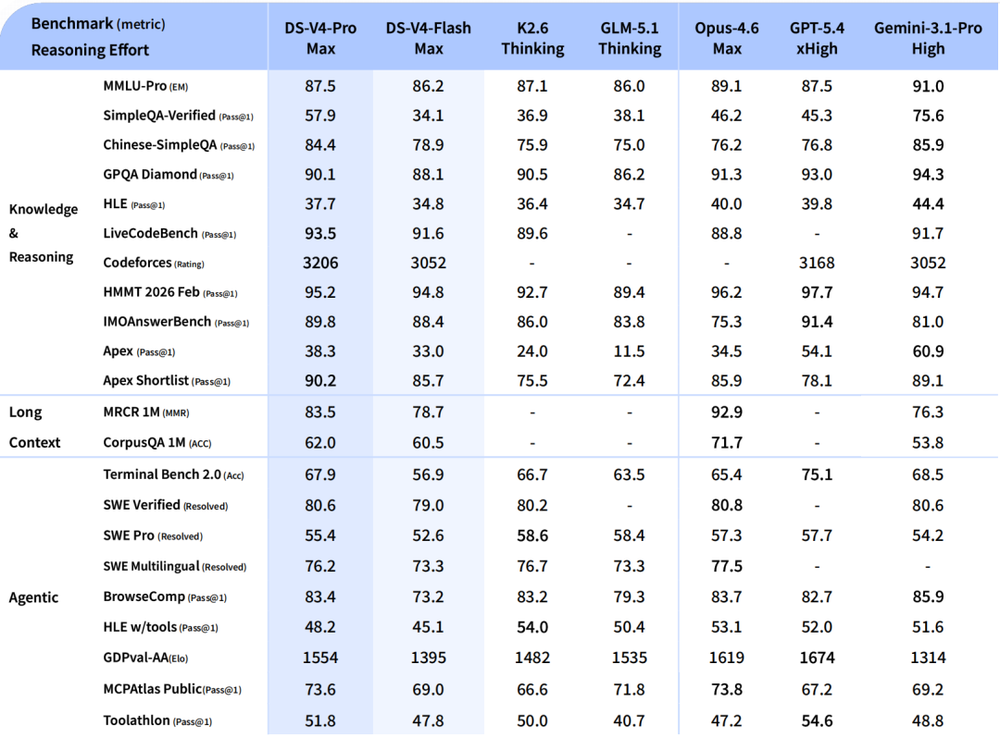
在知识与推理类任务中,其在SimpleQA、Apex、Codeforces等评测中均超过当前主流开源模型,并在多项任务上接近GPT-5.4与Gemini 3.1 Pro。例如在Apex Shortlist中达到90.2分,已经超越顶级闭源模型;在Codeforces等竞赛类任务中,也维持在第一梯队水平。
在Agent能力相关任务中,DeepSeek-V4-Pro在SWE Verified、Terminal Bench等指标上表现稳定,SWE Verified达到80.6,接近Claude Opus 4.6,明显高于多数开源模型。在Terminal Bench 2.0中,其表现同样超过GLM-5.1 Thinking、Kimi K2.6 Thinking等模型。
整体来看,DeepSeek-V4-Pro已是目前开源模型的“天花板”。
这一代DeepSeek-V4明显强化了对Agent场景的适配。其针对Claude Code、OpenClaw、CodeBuddy等主流Agent框架进行了专项优化,在代码生成、文档生成等多步骤任务中表现更稳定。下图为DeepSeek-V4-Pro在某Agent框架下生成的PPT内页示例:
从实际定位来看,DeepSeek-V4-Pro已经被DeepSeek内部作为Agentic Coding模型使用,侧重点在于“完成任务”。在简单任务上,V4-Flash已可与Pro版本接近,而在复杂任务中仍存在明显差距。
本质上是在为Agent应用提供两种“算力档位”。DeepSeek-V4-Flash在简单Agent任务中已经能够与DeepSeek-V4-Pro“旗鼓相当”,但在复杂任务中仍有差距。这种差异,本质上是推理深度与上下文利用能力的差别。
DeepSeek-V4的发布不仅展现了团队在技术和架构上的积淀,也标志着开源大模型在国产算力生态下的实际落地能力。
经过对华为昇腾、寒武纪等国产芯片的适配优化,DeepSeek-V4系列实现了百万token上下文的稳定支持和高效推理,使长链路任务与多步Agent执行成为可能。
这一版本将Pro与Flash的不同定位落到实处,在性能上逼近闭源旗舰模型,在成本上保持高性价比,为国内开发者提供了前所未有的开放选项。
更重要的是,这次发布显示出开源模型不仅能在全球竞争中站稳脚跟,也能够借助国产算力和优化架构,将技术潜力转化为实际可用的生产力。
DeepSeek-V4或许是中国开源力量在高性能AI赛道上迈出的关键一步,也为国内AI生态的创新和落地提供了明确指引。