

机器人的抓取「简史」
具身抓取(Embodied Grasping)作为机器人领域的核心技术之一,旨在真实或模拟环境里,借助感知、规划与执行能力,构建起机器人抓取物体的闭环流程。其目标就是让机器人如人类一般,灵活适配复杂场景并高效完成抓取任务。
要实现具身抓取,究竟需要掌握哪些关键知识点呢?
本文将从具身硬件平台、具身感知、策略学习、智能体执行、技术难点和发展未来这几个维度展开,涵盖19篇近2年的优秀论文成果,拆解技术实现的核心脉络。

硬件根基
具身平台是技术落地的载体
要让机器人进行抓取任务,首先得有个"好身体"。现在的具身平台大致可以分为四大类:机械臂、末端执行器、移动复合机器人、人形机器人。
本节将针对这四类具身平台进行介绍。
机械臂
具有典型代表性的有UR5与Franka Emika Panda,在目前的工业与科研领域发挥着重要作用:
UR5¹
UR5是优傲机器人公司推出的6自由度协作机器人,具有结构紧凑、成本低且易于编程的特点,在工业环境中得到了广泛应用。
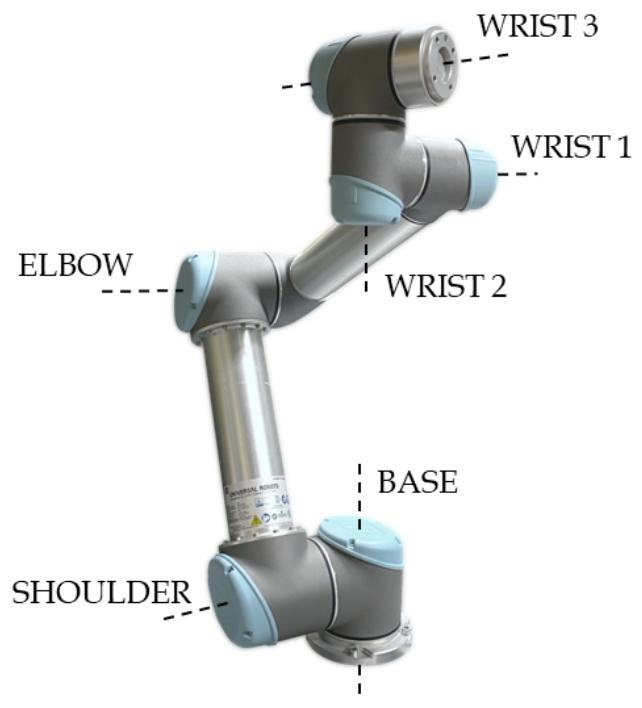
▲UR5机械臂结构及关节示意图
6个关节均配备了光学编码器、磁编码器和电流传感器,从而实现高精度反馈;
驱动系统则采用永磁同步电机搭配谐波减速器,减速器通过平移等效模型描述其内部动力学模型,减速比高达 101:1,具有零背隙、紧凑轻量的特点;
控制逻辑基于PI策略的三嵌套闭环(位置、速度、电流),结合LuGre模型模拟关节摩擦(含静摩擦、粘滞摩擦和 Stribeck 效应)。
Franka²
Franka机械臂(Franka Emika Panda)是首款商业化触觉机器人,具备1kHz实时通信接口,支持高精度关节扭矩控制(精度<0.1Nm)与力反馈,采用7自由度轻量化设计(约18kg)和“三明治”半壳模块化结构,可快速组装拆卸并支持自组装生产模式。

▲使用Franka Emika Panda进行研究的案例
其软件生态丰富,兼容ROS、MATLAB等平台及AI/ML框架,全球超86%顶尖机器人机构使用它进行研究。应用场景覆盖工业自动化(如3C电子装配、检测)、医疗康复、教育教学等,且通过安全认证可直接与人协作,是当前机器人研究与工业应用的标杆平台。
末端执行器
末端执行器是机器人直接执行操作任务的关键部件,安装于机械臂末端。其核心功能是通过抓取、夹持、吸附等方式与环境互动,从而完成各类精密或复杂任务。
根据应用场景不同,末端执行器可分为灵巧手、夹爪、等多种类型,现有的末端执行器可以分为以下4类³:
灵巧手

▲灵巧手代表产品
平行夹爪

▲平行夹爪代表产品
开闭型夹爪

▲开闭型夹爪代表产品
柔性夹爪

▲柔性夹爪代表产品
移动复合机器人
什么是移动复合机器人?
简单来说,它就像"长了腿的智能机械臂",能跑能抓、会看会想;通过将各种异构平台进行组合的形式。
其中较经典的案例,如波士顿动力的Spot Arm和斯坦福的Mobile ALOHA。
(1)波士顿动力Spot Arm
作为基于波士顿动力 Spot Arm 机器人开发的重要技术框架:Track2Act⁴,由卡内基梅隆大学与Meta的FAIR实验室合作开展。该框架用广泛可用的网络视频数据来学习与具体机器人形态无关的交互计划,并通过少量的机器人特定数据进行微调,从而实现对未见任务和物体的泛化。
首先利用基于扩散模型的网络预测图像中点的未来运动轨迹,这些轨迹表示了物体为实现目标应如何移动;
然后,将这些2D轨迹与初始场景的深度图像结合,推断出物体的3D刚体变换序列,从而获得机器人的末端执行器姿态,实现开环控制;
最后,通过少量特定机器人的交互数据,训练一个残差策略来修正开环计划中的误差,从而实现闭环控制。
Track2Act基于波士顿动力Spot Arm机器人,在办公室、厨房等真实场景中验证了对关微波炉、拉抽屉、倒液体等多样化任务的泛化能力,成功率达40-70%(远超传统行为克隆的0-20%)。

▲Track2Act基于波士顿动力Spot机器人的真实场景操作测试©️【深蓝具身智能】编译
(2)斯坦福 Mobile ALOHA⁵
Mobile ALOHA是斯坦福开源的一款低成本双臂移动操作机器人系统,它支持全身遥操作,并能够通过模仿学习执行复杂的移动操作任务。
Mobile ALOHA在ALOHA系统的基础上增加一个移动底座和全身遥操作界面,实现了在真实世界中执行复杂任务(如从冰箱取食物、烹饪虾以及清理溢出的酒等)。
该系统成本仅为32,000美元,且仅需50个演示数据就可以将成功率提高至90%,使Mobile ALOHA能够自主完成复杂的移动操作任务。此外,该系统还兼容多种先进的模仿学习方法,如ACT、Diffusion Policy和VINN。
Mobile ALOHA不仅展示了其在复杂任务上的操作能力,还提高了遥操作的易用性和学习效率。

▲Mobile ALOHA效果展示©️【深蓝具身智能】编译
人形机器人
人形机器人的核心优势并非"模仿人类外形",而是通过形态仿生实现"环境兼容性 + 认知通用性 + 协作自然性"的三位一体,这种特质使其成为连接数字世界与物理世界的最佳载体之一。
目前,主流的人形机器人平台包括:特斯拉的Optimus、宇树的H1/H2等。
(1)特斯拉Optimus⁶
Optimus是特斯拉开发的人形机器人,重57公斤、高1.73米、20公斤的负载能力和每小时8公里的行走速度,能够执行复杂的任务并与人类进行自然交互。具备40个电机,其中12个位于手臂,2个位于颈部和躯干,12个位于腿部,12个位于手部,高自由度使得Optimus能够执行复杂的任务。
Optimus还配备了特斯拉的全自动驾驶计算机、自动驾驶摄像头、全套人工智能工具、神经网络规划、自动标记物体、模拟能力等专有技术,使其能够进行认知自动化并适应不同的工作环境。

(2)宇树H1
基于Unitree H1(国内第一台能跑的全尺寸通用人形机器人),Expressive Whole-Body Control⁷提出了一种ExBody控制方法:
通过上半身模仿人类动作:跟踪9自由度关节角度与肩肘手等18维关键点位置,以表达式奖励实现精细动作模仿;
下半身松弛控制:仅稳健跟随线性速度、姿态角等;
利用CMU MoCap数据集(780个动作片段)经运动重定向技术映射至H1硬件结构
在Isaac Gym中进行大规模并行仿真训练。

▲ExBody在Unitree H1测试效果©️【深蓝具身智能】编译
来自小编的Tips:现代机器人研发离不开“数字孪生”仿真试错。使用Gazebo仿真平台可精确模拟机械臂抓取时的摩擦力矩,PyBullet的物理引擎能复现人形机器人在冰面的滑倒场景,使研发成本降低60%以上。
例如特斯拉在Optimus研发初期,通过仿真测试了10万种步行姿态,才将现实中的跌倒概率控制在0.1%以下。这种「虚拟训练→物理验证」的模式,正成为具身智能发展的核心路径。

关键技能
感知、决策、执行的抓取闭环
具身感知、决策、执行是具身抓取任务的关键技能。
具身感知:智能体通过自身的传感器,如视觉、听觉、触觉等传感器,来获取周围环境信息,感知物体位置、形状、质地等;
具身决策:智能体基于感知到的信息,结合自身目标和知识,做出行动选择的过程。例如在复杂环境中,机器人要决定先执行哪个任务、如何移动等,需综合考虑多种因素;
具身执行:智能体将决策转化为实际动作,通过机械结构,如机器人的关节、手臂等完成任务,依据决策指令,精准控制关节运动,同时传感器实时反馈调整,完成抓取物品、移动到指定位置等动作。
具身感知:机器人的"眼睛"
(1)3D特征融合:
Polarnet⁸
Polarnet利用语言引导机器人进行操作,该模型利用3D点云输入、PointNext编码器以及多模态Transformer,将多视角RGB-D图像生成的点云与语言指令融合,以预测 7自由度动作(包括位置、旋转和夹持器开合状态)。
在RLBench基准测试的单任务、多任务单变体和多任务多变体场景中均优于基于2D特征和3D特征基线方法;在真实机器人实验中,7个任务平均成功率达60%,验证了3D点云在解决多视角对齐、精确 3D定位等问题上的优势,为语言引导机器人操作提供了高效的3D解决方案。

▲Polarnet在真实环境中的任务示例©️【深蓝具身智能】编译
PhyGrasp⁹
PhyGrasp模型旨在将物理常识推理融入机器人抓取任务,以解决传统方法在处理长尾场景(如材料或形状特殊的物体)时泛化能力不足的问题。
PhyGrasp是一个多模态大模型,通过桥接模块整合了自然语言和3D点云输入,其中语言模态用于推理材料的物理属性对抓取的影响力,3D模态则理解物体形状和部件结构,从而准确评估物体部件的物理特性并确定最优抓取姿势,同时PhyGrasp还支持根据人类指令生成符合偏好的抓取方案。
为训练该模型,研究者构建了PhyPartNet数据集,该数据集包含19.5万个具有不同物理属性和人类偏好的物体实例及其语言描述。

▲PhyGrasp在真实环境中的实验©️【深蓝具身智能】编译
(2)3D场景重建:
GaussianGrasper¹⁰
GaussianGrasper核心特点在于利用3D高斯splatting技术显式建模3D场景,并通过高效特征蒸馏模块(EFD)融合SAM分割先验与CLIP语言特征,构建了具备开放性词汇语义的一致特征场,从而解决了多视图语义不一致和隐式场推理低效问题。
结合渲染深度与表面法线生成几何信息,利用基于力闭合理论的法向引导抓取模块来筛选可行抓取姿态,并通过高斯基元与少视图结合微调实现场景快速更新。该方法在真实家居场景中查询速度较基线提升180倍。

▲相比于2D特征和LERF方法,GaussianGrasper的场景重建一致性效果最好©️【深蓝具身智能】编译
GNFactor¹¹
GNFactor是一种用于多任务机器人操作的视觉行为克隆代理,其核心特点利用可泛化神经特征场(GNF)融合3D体素表示和视觉语言基础模型(如Stable Diffusion)提取的语义特征,通过联合优化神经辐射场(NeRF)的RGB渲染与语义特征进行蒸馏,构建了包含几何结构和语言语义的3D体素特征;GNFactor采用Perceiver Transformer决策模块,将语言指令编码为任务嵌入,实现对操作任务的跨场景推理。
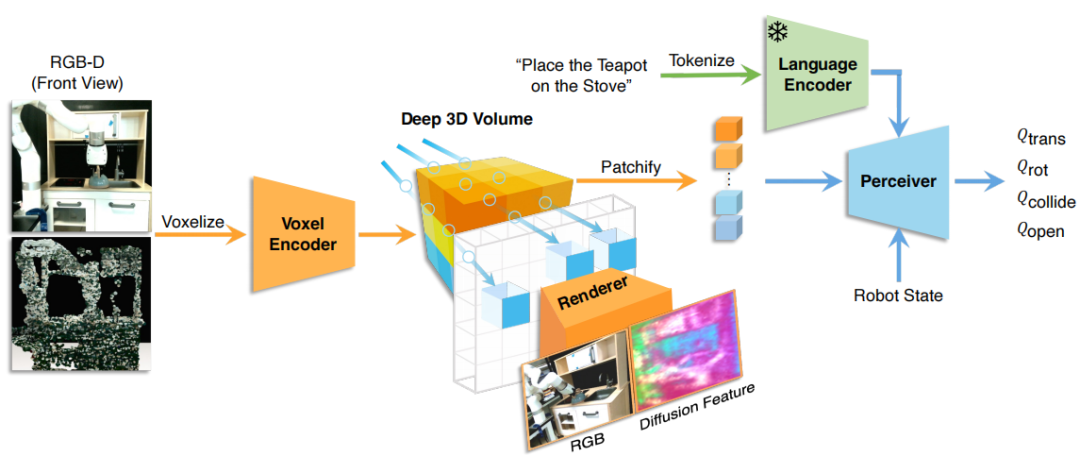
▲GNFactor框架的概要图©️【深蓝具身智能】编译
具身策略:机器人的"动作教练"
(1)模仿学习
GreenAug¹²
GreenAug是一种基于绿幕技术的机器人操作场景泛化数据增强方法,其核心特点在于通过色度键控算法将绿幕背景替换为随机纹理、生成合成背景或掩码背景,使机器人策略聚焦于任务相关目标,提升对未见场景的泛化能力。
该方法通过物理绿幕搭建简化数据采集流程,支持“场景到绿幕”和“绿幕到场景”两种部署方式,适用于多种机器人学习框架(如模仿学习ACT和强化学习)。

▲GreenAug数据采集过程©️【深蓝具身智能】编译
Diffusion Policy¹³
Diffusion Policy是一种通过动作扩散过程来生成机器人行为的视觉运动策略学习方法,其核心特点在于将机器人策略建模为条件去噪扩散过程,通过学习动作分布的分数函数梯度,利用随机朗之万动力学迭代优化动作序列,从而完成对动作的去噪。
Diffusion Policy在15项模拟和真实任务中超越现有方法46.9%,尤其在多阶段任务、含干扰场景以及双手机器人操作(如打蛋、铺毯、叠衣)中表现出强泛化性,且通过位置控制和扩散模型加速技术平衡了实时性与动作精度。

▲Diffusion Policy设计亮点©️【深蓝具身智能】编译
(2)强化学习
Text2Reward¹⁴
TextReward是一个基于LLMs的无数据框架,旨在解决强化学习中奖励函数设计难题。它能依据自然语言描述的目标,生成可用于执行的程序形式的奖励函数,该函数以环境的紧凑表示为基础,具有高度可解释性与自由形式的特点,可覆盖广泛任务。
与逆强化学习和同类LLMs应用不同,TextReward无需数据,生成的奖励代码并非仅在剧集结束时生效,因此能更好适配复杂任务。通过在机器人操作基准测试(如ManiSkill2、MetaWorld)和MuJoCo运动环境中的评估,使用其生成用于奖励代码训练的策略,这些在模拟器训练的策略可以直接迁移至现实世界。同时TextReward允许通过人类反馈迭代优化奖励函数,从而解决任务歧义等问题。

▲TextReward框架的流程图©️【深蓝具身智能】编译
VoxPoser¹⁵
VoxPoser是一种结合LLMs和VLMs的机器人操作框架,其核心在于通过LLMs解析自然语言指令,生成Python代码去调用感知API(如OWL-ViT、Segment Anything)来获取物体空间几何信息,并利用NumPy操作构建3D价值图(包含affordance、avoidance、rotation等地图),从而将语言指令转化为机器人可感知的空间目标函数。
通过模型预测控制(MPC)框架,对价值图进行优化,从而生成密集的6自由度末端执行器轨迹。该框架无需额外训练,具备零样本泛化能力,可处理开放集指令和物体,如“打开顶部抽屉并避开花瓶”等复杂任务。

▲VoxPoser在真实场景中执行任务效果©️【深蓝具身智能】编译
具身执行:机器人的"执行中枢"
(1)分层架构
SayCan¹⁶
SayCan是一种将大型语言模型(LLMs)与机器人预训练技能相结合的框架,其核心特点在于通过LLMs(如PaLM)解析自然语言指令,生成任务相关技能的文本描述,并利用强化学习训练的价值函数(Value Functions)计算技能在当前环境中的执行成功概率,两者结合筛选出既符合任务需求又具有执行可行性的技能序列(如“寻找海绵→捡起海绵→带到用户处”)。
该框架支持零样本泛化,能处理长时域指令(如清理洒出的饮料并更换),通过实时环境反馈和闭环规划动态调整动作,同时SayCan还可以扩展技能库(如新增抽屉操作技能)并优化语言模型提升性能。
▲SayCan执行长视距任务©️【深蓝具身智能】编译
(2)统一架构
RT-2¹⁷
不同于SayCan的分层架构,RT-2采用视觉-语言-动作(VLA)架构,即将全部整合到一个统一的端到端模型当中,RT-2的核心特点在于通过联合微调大规模预训练视觉语言模型(如PaLI-X、PaLM-E)与机器人轨迹数据,将机器人动作编码为文本tokens,使其既能处理图像和语言输入,又能直接输出低-level的机械臂控制指令(如 6-DoF位姿、夹爪状态)。
该模型通过互联网级视觉语言数据(如WebLI)与机器人操作数据协同训练,显著提升了对新物体、场景和指令的泛化能力。尽管存在实时性依赖云端计算、新技能拓展受限等局限,但仍为通用机器人学习提供了“数据高效+语义推理”的新范式。

▲RT-2框架的概要图©️【深蓝具身智能】编译

突破方向
抓取任务面临的三大挑战
尽管具身抓取技术已取得显著进展,但其在真实场景中的落地仍面临三大核心挑战,这些挑战如同 “最后一公里” 障碍,阻碍着机器人从实验室走向复杂的现实环境。以下是对挑战与解决方向的深度解析:
(1)数据鸿沟:仿真与现实的割裂
具体的挑战:
感知偏差:仿真环境中物体材质、光影效果与真实世界差异显著(如透明玻璃、反光金属的渲染误差),导致模型在真实场景中无法准确识别物体边缘和抓取点。
数据稀缺:柔性物体(如布料、塑料袋)和异形物体(如耳机线、不规则石块)的高质量标注数据匮乏,现有数据集多集中于刚性规则物体(如 YCB 数据集的杯子、盒子)。
场景局限:家庭、工厂等复杂场景中的动态交互数据(如抓取过程中物体滑落、碰撞干扰)采集成本极高,难以规模化获取。
解决方向:
合成仿真模拟数据:GenSim2¹⁸是一个可扩展的机器人数据生成框架,它借助多模态和推理大语言模型(如GPT-4V、OpenAI o1)自动生成复杂且逼真的模拟任务(包括含关节物体的长周期任务),并通过关键点运动规划器和强化学习求解器规模化生成演示数据,减少人工标注成本。

▲GenSim2生成数据过程©️【深蓝具身智能】编译
低成本真人数据采集:例如通过Open-TeleVision¹⁹ 系统,用户佩戴VR设备进行抓取操作,系统同步记录手部动作与环境交互数据,以近乎游戏化的方式低成本人类抓取策略数据

▲Open-TeleVision系统的自动化和遥操作2种效果©️【深蓝具身智能】编译
(2)模型轻量化困境:硬件算力的瓶颈
具体的挑战:
计算资源受限:主流大模型参数量达数十亿级,而机器人嵌入式硬件(如 NVIDIA Jetson 系列)的算力仅为云端服务器的千分之一,导致模型推理延迟高,无法满足实时抓取需求。
能效比矛盾:提升模型精度往往依赖更深的网络层数和更大的输入分辨率,但这会导致功耗激增(如ResNet-50模型在嵌入式设备上的功耗是轻量化模型的3-5倍),限制了移动机器人的续航能力。
解决方向:
知识蒸馏:例如Am-radio²⁰是一种多教师蒸馏框架,旨在将CLIP、DINOv2、SAM等不同视觉基础模型(VFM)的特性融合为统一模型,这样将多个大模型的关键参数压缩至单个模型中,可以加大的减小模型参数量,从而提高部署推理性能。
Am-radio的训练效率极高,仅需原始模型2%-5%的数据量即可超越单个教师性能;并且Am-radio提供了高效架构E-RADIO,在保持性能的同时实现至少7倍于教师模型的推理速度,适用于图像分类、分割、视觉问答等多任务场景。
(3)泛化能力短板:未知场景的适应性危机
具体的挑战:
物理常识缺失:现有模型多基于视觉数据训练,缺乏对物体物理属性(如重量、摩擦力、形变阈值)的理解,导致抓取策略单一。例如,抓取鸡蛋时使用与抓取金属块相同的握力,容易造成物体损坏。
解决方向:
引入物理先验:例如前面提到的PhyGrasp框架。

应用图景
具身抓取能做这些事
从工厂流水线到家庭厨房,具身抓取正在改变人类的生活方式:
(1)家庭助手:
乐聚智家“夸父”机器人项目
夸父机器人是海尔与乐聚联合打造的国内首款家庭服务人形机器人,重45kg、26 个自由度,搭载开源鸿蒙系统,能以4.6km/h步速适应多地形行走、完成超20cm连续跳跃及洗衣浇花等家务操作。
目前已进入全面量产阶段,每台售价几十万元,率先在科研教育和特种作业领域商业化落地,未来计划通过降低成本(预估3年后十几万元、5-10年后5 万元)走进家庭,成为家庭助手。

▲夸父机器人©️【深蓝具身智能】编译
海尔洗护机器人项目
海尔研发的洗护机器人,机械臂可上下移动、自由伸展,能与海尔洗衣机联动,自动开关洗衣机门,抓取、投放、分拣衣物,并识别深色或浅色衣物,实现“无人家务”,不过目前该机器人还处于研发阶段。

▲海尔洗护机器人©️【深蓝具身智能】编译
(2)医疗助手:
达芬奇Xi手术系统
2023年11月首台国产达芬奇Xi手术系统在上海进博会上亮相,该机器人系统已成功通过国家药监局批准,并获得国产手术机器人医疗器械生产许可证,应用于泌尿、妇科、普外、胸外及小儿外科。
达芬奇Xi手术机器人具有三维高清视野、可转腕手术器械和直觉式动作控制三大特性,将外科医生手部动作的颤抖等自动滤除并转换成更精准的动作,其弯曲及旋转程度远超人手极限,让机器人辅助手术变成现实。


▲国产达芬奇Xi手术系统©️【深蓝具身智能】编译

结语
从硬件平台的机械灵巧到感知系统的环境解码,从策略学习的智能迭代到执行端的精准落地,具身抓取的每一步突破都在缩短机器人与人类操作能力的差距。当下,动态场景适配、多模态信息融合仍是待解的难题,作为机器人智能落地的“核心枢纽”——具身抓取,其闭环能力的构建绝非一日之功。
本文从硬件平台、感知技术到策略学习与执行优化的核心脉络进行了梳理,也直面了其面临的环境复杂性与泛化挑战。随着大模型与机器人技术的深度耦合,感知精度、决策智能与控制柔性的持续突破,相信具身抓取技术将不断突破现有边界,赋能机器人在更广泛、更真实的场景中自主、高效地完成复杂任务,最终推动机器人智能迈向灵活、可靠的新高度。
你觉得未来机器人还能解锁哪些抓人眼球的抓握技能呢?
编辑|木木伞
审编|具身君
参考资料:
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文