
世界模型(World Model),想必你已经在很多场合听过这个术语了。它有时出现在视频生成领域,有时又出现在具身智能领域;它们的含义还有所差别,甚至看起来像是完全不同的概念。
为什么会出现这样的分歧?答案藏在这个词的历史里。
近日,MoE Capital 的 Henry Yin 和 Naomi Xia 撰写了一篇深度博客,系统梳理了「世界模型」这一概念背后两条长达数十年、彼此独立演进的研究脉络:一条是强化学习社区从 1990 年代便开始探索的「让智能体在想象中做梦」,另一条是计算机视觉社区从海量人类视频中学习物理知识的「从观看中学习」。直到 2024 至 2025 年间,这两条线索才真正交汇,孕育出我们今天所说的「视频世界模型」。

文章还深度拆解了世界模型当前的真实能力边界:从已在生产环境落地的自动驾驶仿真,到前景可期的机器人策略评估,再到尚未得到充分验证的直接机器人控制。作者给出了一份难得清醒的技术现状判断,并坦言整个机器人 AI 领域的成熟度远比 100 亿美元的融资规模所呈现的更加早期。
与此同时,文章也深入剖析了这场资本盛宴背后的战略格局:NVIDIA 正通过全栈开源构建物理 AI 时代的「CUDA 护城河」;Yann LeCun 押注完全绕开像素预测的 JEPA 架构;而 Physical Intelligence 的最新旗舰模型,已悄然在内部集成了世界模型组件。两种路线的边界,正在加速模糊。
机器之心编译了这篇文章,以飨读者。

原文标题:The Model That Dreams the World(梦见世界的模型)
博客链接:https://moe-capital.com/blog-home/the-model-that-dreams-the-world
1. AI 领域最被滥用的词
让我们先看看世界模型能做什么。
一个机器人从未见过鞋带,也从没有人远程操控着它完成解开鞋带的动作。但这个机器人俯下身去,抓住鞋带,将其抽出。它成功了 —— 因为它经过了一个模型的训练,这个模型观看了数千小时人类双手操作各种物品的视频,学会了物体在被拉、被扭、被推时的运动规律,并在动手之前就能预判接下来会发生什么。这个机器人在自己的想象中反复练习,然后才触碰现实。
这就是世界模型的承诺:一个对物理世界的理解深入到足以预测下一步会发生什么、并据此采取行动的模型。不是用文字描述世界的语言模型,亦非生成画面的视频生成器,而是一个真正理解事物运作方式的模型。
过去 18 个月,超过 100 亿美元涌入了这一概念。Yann LeCun 离开 Meta 去构建这样的模型;Danijar Hafner(其 Dreamer 系列是基于模型的强化学习领域最具影响力的工作)也离开了 DeepMind,转而将其商业化;NVIDIA 开源了一整套相关系统;OpenAI 关闭了 Sora,将此次关闭定性为向「机器人世界仿真」的转型,而就在三周后,这个团队的负责人也离开了公司。

这些都被叫做世界模型,但并不是一回事
然而,大多数被冠以「世界模型」之名的东西根本不是真正的世界模型。这个术语如今涵盖了视频生成器、强化学习的梦境机器、抽象表示学习器以及动作预测基础模型。两条独立的研究脉络近期汇聚,共同孕育了我们今日所称的「视频世界模型」。这次汇聚是如何发生的,其结果是否真正奏效 —— 这正是本文要探讨的问题。
为何偏偏是现在?两件事同时发生。
第一,交互式视频模型自 2024 年起便已存在(如 Genie、GameNGen),但彼时仅是狭窄的原型。到了 2025 年,两项突破(AR-DiT 与 Self Forcing)使得将通用的高质量视频基础模型改造成既具交互性又能实时运行成为可能。这让视频世界模型从研究蜕变为潜在的实用基础设施。
第二,机器人领域历来面临数据匮乏的困境,而随着行业开始训练基础模型,这种饥渴感比以往放大了几个数量级。当前最优秀的机器人基础模型在约 1 万小时的远程操控数据上训练,但远程操控成本高、采集缓慢、多样性有限。世界模型提供了另一条路:先在已有的数百万小时人类视频上做预训练,再用少量机器人数据做微调。
不过,有必要保持清醒。整个机器人 AI 领域的成熟度远比融资规模所呈现的要低得多。当前大多数生产部署依赖的是视觉-语言-动作模型(VLA),而非纯粹的世界模型,不过连领先的 VLA,Physical Intelligence 的 Pi-0.7,也已开始整合一个小型世界模型用于子目标规划。
世界模型在特定场景下展现了强劲的成果 ——DreamDojo 实现了近乎完美的策略评估,DreamGen 实现了从极少数据到泛化的跨越;但对所有方法来说,通用操作任务仍是一道尚未攻克的难题。
2. 两条线索的交汇
我们今日所称的「视频世界模型」,脱胎于两条平行发展了数十年、最终在 2024 至 2025 年间交汇的独立研究脉络。
线索 A:学会做梦(强化学习世界模型,1990—2025)
「智能体应该构建一个内部环境模型」这一理念,早于深度学习本身。Kenneth Craik 在 1943 年便在《解释的本质》中提出,人类在脑海中携带着现实的「小型模型」,以此预见即将发生的事。1990 年,Jürgen Schmidhuber 发表了《让世界可微》,将这一概念形式化用于神经网络:智能体应学习一个可微的环境模型,并以此规划行动。这一想法此后沉寂了近三十年。
2018 年,David Ha 和 Schmidhuber 以一篇题为《World Models》的论文和一个交互式网站 worldmodels.github.io 将其重新唤醒,让你能亲眼看到 AI 智能体在做梦。

左侧:真实的赛车环境。右侧:智能体对其的梦境。模糊之处正是关键 —— 那是世界模型所想象的画面。

Ha & Schmidhuber 的 V+M+C 架构(2018 年)。在梦境模式(右图)中,环境处于断开状态。智能体完全在其自身想象中进行实践。
该架构分为三个模块:一个 VAE(变分自编码器)将像素压缩为潜在向量;一个 MDN-RNN 在该潜在空间中以概率分布的形式预测动态;以及一个完全在想象中的展开过程中训练出来的微型控制器。这个智能体在自己的梦境中训练,然后被部署到现实中,而且成功了 —— 在 Car Racing 和 VizDoom 上得到了验证,概念已被证实。
Danijar Hafner 随后用六年时间在相同理念的基础上,以不同的架构持续深耕。他的 RSSM 架构(PlaNet,2019)将确定性记忆与随机不确定性相结合,解决了一个根本性的表示问题。Dreamer 系列从简单的连续控制(V1,2020)扩展到人类水平的 Atari(V2,2021),再到以单一超参数集涵盖 150 余个基准测试,包括在 Minecraft 中从零开始挖取钻石(V3,发表于 2025 年的《Nature》)。Dreamer 4(2025 年底)用 Transformer 替换了循环骨干,速度提升了 25 倍。DayDreamer(2022)将其落地到真实机器人上:一个四足机器人仅用一小时便从零学会了行走。
值得一提的是,DeepMind 的 MuZero(2020)另辟蹊径:它学习的世界模型只预测奖励和价值,从不重建观测结果。它仅对决策相关的内容建模,在从未生成单帧像素的情况下,征服了围棋、国际象棋和 Atari。这与 Dreamer 将观测重建作为训练信号的哲学截然不同,但核心理念如出一辙:想象可能的未来,选择最优行动。

DreamerV3 从零开始在《我的世界》里收集钻石 —— 无任何示范,无需奖励塑造。

DayDreamer 的四足机器人在一小时的现实世界互动中学习行走。
这条脉络的正确之处:核心理念。学习动力学,想象未来,从想象中训练策略而非依赖昂贵的真实世界交互,动作条件化,样本效率。这些概念基础已被今日每一个视频世界模型继承。
它做不到的事:跨环境泛化。Dreamer 智能体可以在单个 Atari 游戏上达到人类水平,但学习下一个游戏则需要从零开始。这些模型体量很小(百万参数量级),它们做的梦是人类无法解读的抽象向量,还需要数千个特定任务的训练轮次。理念是对的,规模是错的。
线索 B:从观看中学习(2016—2025)
与此同时,另一条脉络在默默地从视频中汲取知识。它分阶段演进,每一阶段都让视频对机器人学习更有价值。
第一阶段:用视频预测来规划(2016—2018)
Oh 等人(2015)展示了 Atari 中的动作条件视频预测。Finn 等人(2016)在伯克利将其应用于真实机器人:训练一个模型预测采取某动作后摄像头将看到什么,然后通过选择预测未来最接近目标的动作来进行规划。这对简单的推物任务有效,但预测在几帧之后便会退化 —— 太模糊,时间跨度太短,无法应对复杂的操作。
第二阶段:从人类视频中学习表示(2020—2022)
一个关键的认知转变出现了。与其直接预测视频,不如用人类视频来学习可迁移到机器人任务的视觉表示。R3M(Nair 等,2022)是这一阶段的突破:一个在 Ego4D 上预训练的视觉编码器,Ego4D 包含数千小时以第一人称拍摄的烹饪、清洁和物体操作视频。该编码器学会了将摄像头图像压缩为紧凑向量,捕捉物体身份、空间关系和抓取相关特征,同时滤去墙壁颜色和阴影等无关细节。使用 R3M 特征的 Franka 机械臂仅凭 20 次演示就学会了操作任务,远少于不做预训练时所需的数量。
大约同期,OpenAI 的 VPT(2022)表明互联网规模的视频预训练对学习行动同样有效:一个在 7 万小时 Minecraft YouTube 游戏视频上预训练的模型,仅需少量演示便能微调成能干的智能体。这是首个证明海量无标签视频能够引导出复杂序列任务中有能力行为的系统。
EgoMimic(Kareer 等,ICRA 2025)将这一思路推向更远:它不再只用人类视频来学习表示,而是将第一人称人类视频作为真实的演示数据,同时在人类和机器人数据上联合训练统一策略。人类姿态数据将任务性能提升了 34% 到 228%,并实现了对新物体和新场景的泛化。
但这些方法也有天花板。更好的表示和更多的演示数据都有帮助,但人类视频始终只是策略的训练数据,而非一个你可以在其中反复练习的仿真器。
第三阶段:大规模视频生成(2022—2024)
质量的飞跃来自扩散模型在视频上的应用:Meta 的 Make-A-Video(2022)、谷歌的 Imagen Video(2022)及其后继者。扩散 Transformer 能够大规模生成高质量、时间连贯的视频。
Sora(OpenAI,2024 年 2 月)是那个转折点。在海量互联网视频上训练后,它生成了看起来遵循物理规律的画面:物体落下,光线散射,摄像机追踪得栩栩如生。谷歌的 Veo 随后以旗鼓相当的质量跟进。OpenAI 将 Sora 定义为「世界仿真器」。
但 Sora 不具有交互性。它使用双向注意力:所有帧同时看到所有其他帧。你无法在生成过程中注入动作。它是一部电影,不是一个游戏。
这整条脉络的贡献:证明了人类视频包含可迁移的物理知识(R3M、VPT),实现了大规模逼真生成(Sora、Veo),以及互联网规模数据带来的视觉多样性。
它在融合之前做不到的事:实时响应动作。支持机器人所需的闭环:行动、看到结果、做出反应。生成以特定动作为条件的视频,而不仅仅是看起来合理的视频。
融合(2024—2025)
两个社区各自拥有对方所缺失的东西。强化学习有动作条件化,但缺乏泛化能力;视频领域有规模和真实感,但没有交互性。2024 年至 2026 年间,一系列工作弥合了这道鸿沟:
Genie(DeepMind,2024—2025)引入了潜在动作模型:一种从无标签视频中学习交互式环境的方法。模型观察两个连续帧,将「发生了什么变化」压缩成一个小向量,并在无需任何人标注动作的情况下发现动作空间。Genie 1(2024 年 2 月)是一个 160×90 分辨率、1 帧每秒的概念验证。Genie 2(2024 年 12 月)扩展到逼真的 720p,连贯性可维持 10 到 60 秒。Genie 3(2025 年 8 月)达到 720p 下 24 帧每秒,连贯性持续数分钟,但它生成的是 2D 帧而非 3D 几何体,运行成本约为每小时 100 美元。
UniSim(Sherry Yang 等,ICLR 2024 杰出论文奖)走了相反的路:它在视频世界模型内部完整训练了一个强化学习策略,然后以 81% 的成功率迁移到真实机器人上。更早的工作(SimPLe,2020)已在 Atari 的学习视频模型内训练过强化学习,但 UniSim 是首个使用高质量视频扩散模型并证明其能零样本迁移到现实机器人的系统。
Xun Huang 团队的两项技术突破扫除了剩余障碍。AR-DiT / CausVid(CVPR 2025)将视频扩散模型改造为自回归和因果的形式 —— 这是实现交互性的前提:不再同时生成所有帧,而是以当前动作和过去帧为条件,逐帧依次生成。Self Forcing(NeurIPS 2025)随后解决了速度问题,将 35 步去噪压缩到 4 步,首次为通用视频模型实现了实时交互生成。
DreamGen(NVIDIA,2025 年 5 月)证明视频世界模型可以用极少的真实数据解锁机器人的泛化能力。该方法是:在少量真实机器人视频(包括腕部摄像头拍摄的画面)上微调视频生成模型,再用语言指令提示它生成机器人执行从未做过的任务的合成视频。逆动力学模型从这些合成视频中提取电机指令,无需远程操控便能生成训练数据。一台仿人机器人仅凭一次抓放演示,便在未见过的环境中完成了 22 种新行为。这是融合能产生切实机器人价值的首个有力证据。
最终集大成者:DreamDojo 与 DreamZero(NVIDIA,2026 年 2 月)。
DreamDojo:一个在 44,711 小时人类第一视角视频上预训练的视频基础模型,通过学习到的潜在动作空间实现动作条件化,经 Self Forcing 蒸馏后达到实时运行,能够以与真实世界结果 r=0.995 的皮尔逊相关系数评估机器人策略。
DreamZero 更进一步,在单次前向传播中联合预测未来视频和机器人电机动作。

自 1990 年代和 2010 年代起并行发展的两条研究传统,于 2024-2025 年左右开始融合。强化学习传统(蓝色)带来了行动条件化与梦境机制,视频生成传统(紫色)则贡献了照片级生成能力与互联网规模的数据支持。
强化学习社区带来了动作条件化和「做梦」的概念;视频社区带来了逼真生成和互联网规模的数据。这个结果在架构上师承于视频生成,在精神上则传承自强化学习世界模型。
那么,一个世界模型究竟需要什么?
并非所有视频模型都是世界模型。曾共同创作了多个此类系统所用自回归扩散架构的 Xun Huang,提出了五条将世界模型与视频生成器区分开来的属性:
因果性:时间只向前流动。双向视频生成违反了这一点,这是硬性约束。
交互性:实时响应动作。没有这一点,它只是一部电影,而非仿真。这是硬性约束。
持久性:在较长时间内保持连贯。当前大多数模型能维持数秒;Genie 3 能达到数分钟;能稳定维持数小时的系统尚不存在。
实时性:速度快到足以满足应用需求。当前最先进水平:10—30 帧每秒。
物理准确性:遵守真实世界的物理规律。这是最难实现、也最具争议的属性。

视频生成(左图)一次性生成所有帧 —— 精美但无交互性。而视频世界模型(右图)则逐帧生成,每帧都基于动作条件。前者如同一部电影,后者则是一个游戏。
因果性和交互性是二元的。没有这两者,你就没有世界模型。其余三条则是连续谱系。

各大系统在五大属性上的对比:因果关系和交互性是硬性约束,其余三个属性则属于频谱范畴。
3. 世界模型究竟能做什么?
各类用例(从最成熟到最具推测性)
自动驾驶仿真是最成熟的应用。Wayve(GAIA 世界模型,12 亿美元 D 轮融资)和 Waymo 等公司一直在用学习型世界模型生成驾驶场景用于测试。评判标准是:你能合成多样、逼真的驾驶场景来压力测试你的自动驾驶策略吗?无需完整的物理精度,但要有足够的视觉和行为真实感来发现边缘案例。这一应用已在生产环境中落地。
娱乐与游戏紧随其后,或许也是目前演示最为直观的领域。Decart 的 Oasis 是一款完全由世界模型以 20 帧每秒实时生成的类 Minecraft 可玩游戏,已可试玩。Genie 3 以 24 帧每秒、720p 生成可探索的环境。GameNGen 以 20 帧每秒在神经网络上运行 DOOM。马斯克的 xAI 已宣布计划在 2026 年底前推出基于世界模型的电子游戏(尚无演示)。游戏对物理精度的要求较低:只要体验足够吸引人,玩家能容忍一定程度的不真实。但服务成本依然高昂:Genie 3 的运行成本约为每小时 100 美元。

完全运行在神经网络上的《毁灭战士》,帧率超过 20 FPS(GameNGen)。

Genie 3 环境以 24 FPS、720p 分辨率实时导航。
策略评估是机器人领域近期最清晰的价值所在。DreamDojo 实现了其预测与真实世界策略成功率之间 r=0.995 的皮尔逊相关系数。在实际操作中,这意味着你可以在世界模型内部对 20 个候选策略进行排名,而不是进行 20 次昂贵的真实世界试验,且排名结果与现实几乎完全吻合。这将世界模型变成了一个测试环境 —— 机器人行为的单元测试。
合成训练数据生成前景可期,但边际价值尚不明朗。DreamGen(NVIDIA,2025)展示了一台仿人机器人仅凭一次远程操控演示,在视频世界模型生成的合成数据帮助下,便在未见过的环境中完成了 22 种新行为。但即便是构建这些系统的研究人员也承认,这种改进并不显著:有所提升,但远未达到该领域所期望的飞跃。问题在于,合成视频数据所提供的信号,是否真的超越了更多远程操控数据或更好的数据增强所能带来的收益。
样本高效学习在受控环境中得到了验证。DayDreamer(2022)展示了一个四足机器人在一小时的真实世界交互中从零学会行走,因为 Dreamer 世界模型能够在每次真实尝试之间想象出数千次练习。但这一点尚未在生产环境中大规模验证。
直接机器人控制是最大胆的主张,也是最缺乏验证的领域。DreamZero 在单次前向传播中联合预测未来视频和电机动作,并报告称比 VLA 基准有 2 倍的泛化提升。但这只是一篇论文,来自构建该系统的团队本身,尚无独立复现。与此同时,VLA 在快速迭代:Pi-0.5(2025 年 9 月)泛化到未见过的家庭环境,Pi-0.6(2025 年 11 月)加入了基于强化学习的自我改进,Pi-0.7(2026 年 4 月)通过组合所学技能来解决新任务。几乎每几个月就有一个新版本,能力持续提升。纯 VLA 方法更简洁,目前也更经过实战检验,但正如我们将看到的,「VLA」和「世界模型」之间的界限正在开始模糊。
更宏观的图景:机器人 AI 比表象上更早期
诚实的框架并非「VLA 有效,世界模型无效」,而是整个机器人 AI 领域比 100 亿美元的融资规模所呈现的更加早期。导航和受限的仓库拣选任务可以可靠运行。烹饪演示在受控实验室中有效,需要数十次特定任务的演示(ALOHA/Sunday 以 50 次演示在炒虾任务上达到 90% 成功率),但每道新菜都需要新的演示。无论采用何种方法,通用家庭操作、家具组装以及需要丰富接触感的灵巧操作任务对所有人来说都仍是未解难题。
更深层的问题横亘于 VLA 和世界模型之间。迁移几乎从未被系统验证,永远不应被想当然地假设。两种方法都只依赖视觉,缺失了触觉、力反馈和本体感觉,而这些对操作至关重要。标准训练数据集(如 Open X-Embodiment)存在严重的质量和多样性问题。仿真基准接近饱和,而真实世界的零样本性能则远远落后。
与此同时,VLA 方法并未停步。Physical Intelligence 的 Pi-0.7(2026 年 4 月)展示了组合泛化能力,将不同任务的技能组合起来解决新问题,它能操作一个从未见过的空气炸锅,方法是融合相关训练经验的碎片。值得注意的是,Pi-0.7 本身也是混合体:它依赖一个轻量级世界模型(基于 BAGEL 图像生成骨干)生成子目标图像,以规划多阶段任务。即便是当今领先的 VLA,也整合了一个世界模型组件。两种方法并非真正在竞争 —— 它们正在融合。
问题不是哪种方法在赢。而是任何一种方法是否已经足够接近通用操作,使得扩大规模就能完成剩下的路程。世界模型社区的具体押注是:对于最难的剩余任务,理解动力学(通过视频预测)将至关重要,因为单靠从演示中模式匹配是不够的。这个押注看起来有理,只是回报的时间线尚不确定。
4. 百亿美元的赌注
过去 18 个月,超过 100 亿美元流入了世界模型和机器人 AI 公司。资本的走向告诉你行业真正所处的位置,而非论文所描绘的应有位置。
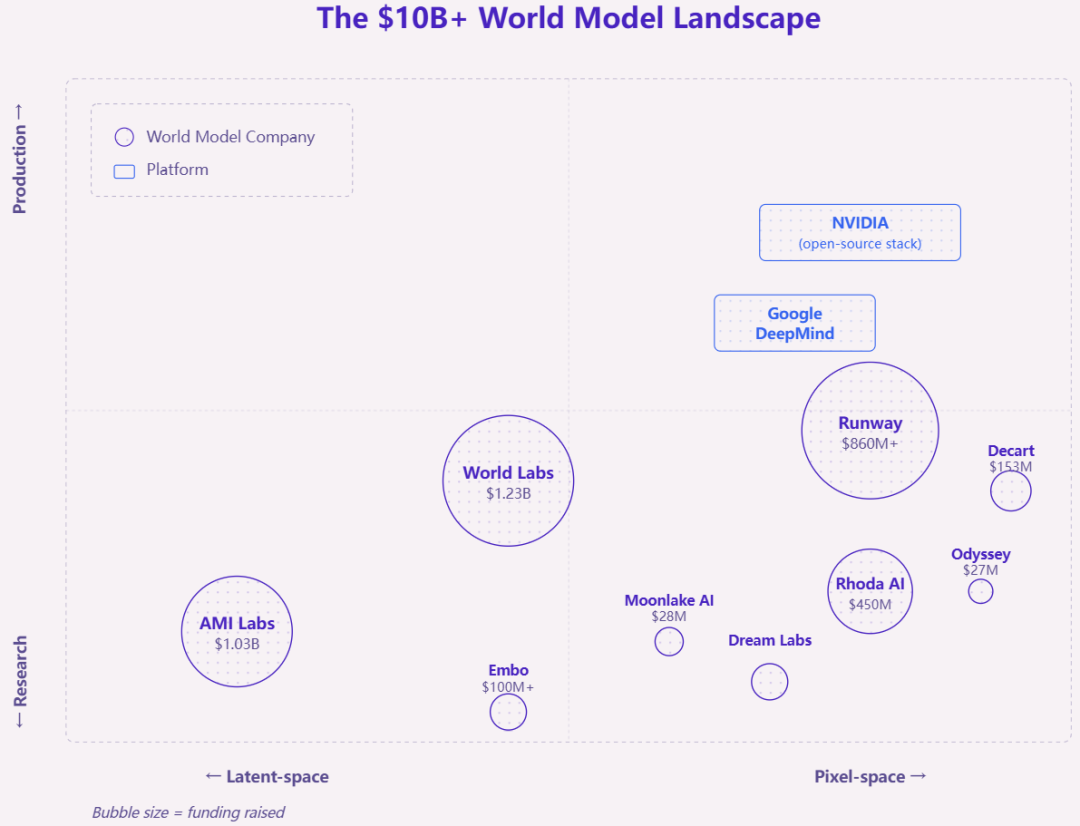
超百亿美元的世界模型格局。气泡大小代表总融资额。紫色:世界模型公司。蓝色框线:平台类企业。
资金分布在四个层次。
纯世界模型公司,构建仿真器本身(AMI Labs 10.3 亿美元、World Labs 12.3 亿美元、Runway 8.6 亿美元以上、Rhoda 4.5 亿美元、Decart 1.53 亿美元、Embo 1 亿美元以上);
将世界模型作为组件的机器人基础模型公司(Skild 18.3 亿美元、Physical Intelligence 11 亿美元以上、Figure 20 亿美元以上、Mind Robotics 6.15 亿美元);
构建并开源基础设施的平台(NVIDIA、Google DeepMind);
大型科技公司的转型(OpenAI 后 Sora 时代的机器人业务、特斯拉、xAI)。
一个值得关注的规律:使用世界模型的公司比构建世界模型的公司融资更多。这要么意味着世界模型层相对于其重要性被低估了,要么意味着最大的机器人公司将在内部自建这一能力。1X Technologies 已经这么做了。
NVIDIA:那头 800 磅的大猩猩
这一领域最重要的战略动向并非来自某家初创公司,而是 NVIDIA—— 它正在构建完整的物理 AI 技术栈,并将其全部开源。
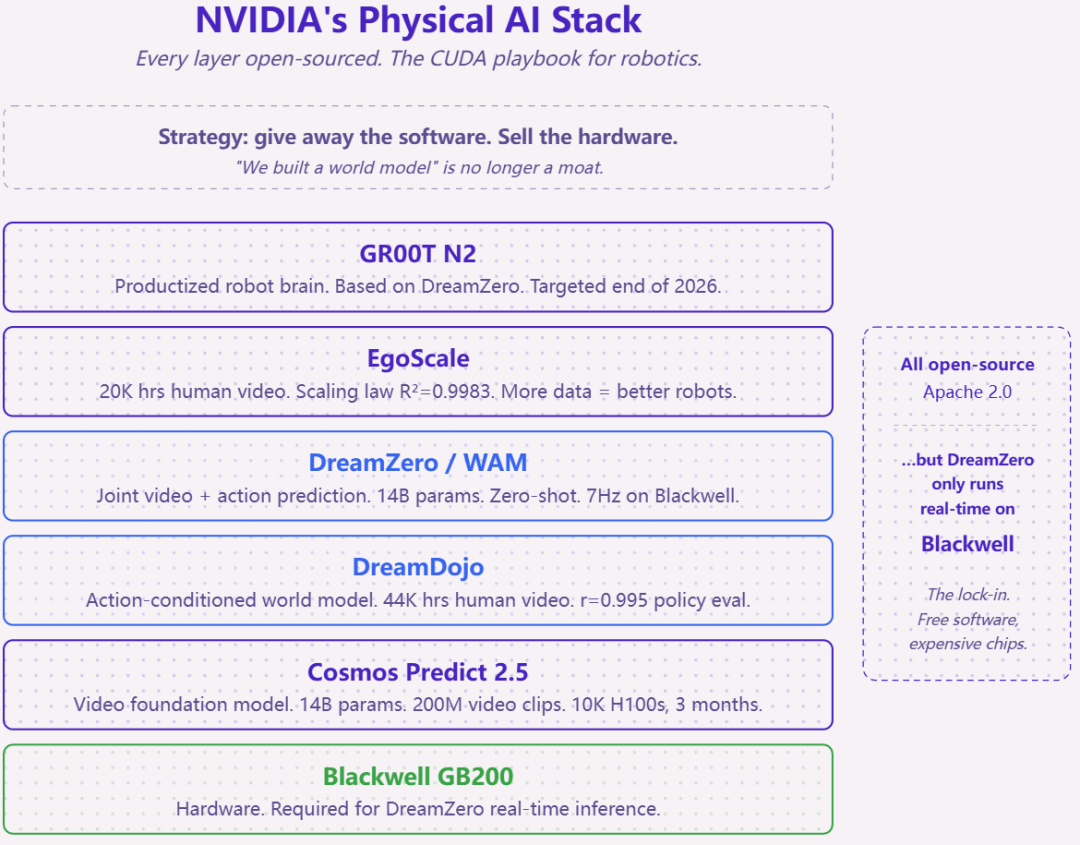
英伟达的物理 AI 技术栈:每个层级均以 Apache 2.0 协议开源。但 DreamZero 仅能在 Blackwell GB200 硬件上实现实时运行。CUDA 开发范式被应用于机器人领域。
这个技术栈从 Cosmos Predict 2.5(视频基础模型,140 亿参数,2 亿视频片段)开始,经由 DreamDojo(动作条件世界模型,4.4 万小时人类视频,策略评估 r=0.995),再到 DreamZero(视频与动作联合预测,在未见任务上零样本泛化),经过 EgoScale(缩放定律:人类视频时长与机器人性能之间 R²=0.9983),直至 GR00T N2(产品化的机器人大脑,计划于 2026 年底推出)。每一层均以 Apache 2.0 许可证开源。
这个策略是为物理 AI 打造的「CUDA」:免费提供软件,销售硬件。DreamZero 以 7Hz 运行,但只能在 Blackwell GB200 上实现,在 H100 上无法达到实时。如果每家机器人公司都在这个技术栈上构建,它们就都需要 Blackwell。
对于那些构建纯粹世界模型的初创公司而言,这是生死攸关的威胁。DreamDojo 免费,且在 4.4 万小时视频上完成训练。「我们构建了一个世界模型」不再是护城河。差异化必须来自 NVIDIA 所没有的领域专属数据、更快的推理速度,或者垂直整合到一个超越单纯模型的产品中。
JEPA 的逆向押注
并非所有人都在构建视频世界模型。Yann LeCun 和谢赛宁正通过 AMI Labs(10.3 亿美元,欧洲有史以来最大的种子轮融资)押注一个反向逻辑。他们的论点是:预测像素在根本上是一种浪费 —— 大多数像素级细节与理解动力学无关。JEPA(联合嵌入预测架构)将观测编码为抽象表示,然后直接预测未来的表示,从不生成视频。与使用像素重建作为训练信号的 Dreamer 不同,JEPA 完全回避了重建。

JEPA 架构示意图:联合嵌入预测架构(JEPA)包含两个编码分支。第一个分支计算 x 的表示 sx,第二个分支计算 y 的表示 sy。两个编码器无需完全相同。一个预测模块借助潜在变量 z,从 sx 预测 sy。能量即为预测误差。JEPA 的简单变体可以:不使用预测器(强制两个表示相等)、使用无潜在变量的固定预测器,或使用如离散变量等简单潜在变量。
V-JEPA 2 在 LeCun 离职之前于 Meta 开发,在超过一百万小时的互联网视频上预训练,然后仅在 62 小时的机器人数据上微调,在无需生成单帧视频的情况下,对抓放任务实现了 80% 的零样本成功率。AMI Labs 现在有 10 亿美元来检验抽象预测是否优于像素预测。反驳的声音是:像素级预测或许能捕捉到抽象表示所遗漏的物理细节,而且你可以观察视频模型认为将会发生什么 ——JEPA 的预测是人类无法解读的抽象向量。
我们看到的机会
NVIDIA 的开源技术栈向这一领域的所有人提出了一个真实的问题:什么是可防御的?我们认为存在几种不同类型的机会,每种都有不同的押注和不同的时间跨度。
前沿横向世界模型。最大胆的押注:构建比 NVIDIA 更好的通用世界模型。AMI Labs 正在用 JEPA 走这条路,在抽象表示空间中进行预测;Embo 则秉持着来自 Dreamer 谱系的不同架构哲学;Dream Labs(由来自 NVIDIA GEAR 实验室的 Joel Jang 创立)在 DreamGen 和 DreamDojo 的工作路线上继续推进。Cosmos 和 DreamDojo 是一个新品类的第一版。架构上的弯道超车是存在空间的,就像 OpenAI 在 DeepMind 多年早期工作之后构建出了 ChatGPT 一样。
垂直专属世界模型。NVIDIA 的技术栈是通用的。一家专门为外科机器人、仓库操作或食品制备构建世界模型的公司,凭借来自实际部署的专有数据,或许能够构筑通用模型无法比拟的护城河。类比:彭博终端 vs.ChatGPT。两者都处理语言,但彭博的行业数据和工作流整合使其对金融专业人士不可替代。这一路径能否成功,取决于领域专属的动力学差异有多大 —— 外科手术的接触力和仓库拣选确实是通用视频模型或许无法精准捕捉的不同物理体系。
基础设施层的工具提供商。推理基础设施、评估平台、仿真到现实的迁移工具、第一视角视频的数据管线。这些比「我们构建了一个世界模型」听起来朴实无华,但解决的是真实的痛点:Genie 3 每小时运行成本约 100 美元,Odyssey 每位用户需要一台完整的 H200,视频模型的服务成本在结构上居高不下。解决这些问题的公司能够在整个生态系统中获取价值。风险在于:NVIDIA 掌控着硬件,而推理优化是一个快速演进的研究领域,很快会被开源吸收。
「产品内置世界模型」路线。对于这类公司,世界模型是垂直整合机器人产品的一个组件,而非产品本身。最终客户为结果付费(叠好的衣物、分拣好的包裹、冲好的咖啡),而不是为推理付费。模型是手段,机器人做有用的工作才是产品。这是大多数现有机器人公司所走的路(1X 自建了世界模型,Figure 和 Skild 整合了 Cosmos),但新进入者需要同时面对硬件、软件和市场拓展三重挑战。
NVIDIA GEAR 实验室主任 Jim Fan 为正在发生的一切起了个名字:大平行(The Great Parallel)。机器人领域正在逐步复制 LLM 的发展剧本。世界模型是预训练阶段 —— 学习仿真下一个物理状态,就像 GPT 学习预测下一个 token。动作微调将这种仿真折叠到对真实机器人真正重要的那一薄片上。强化学习走完最后一英里。这套三步配方,用了六年时间将 LLM 从 GPT-3 带向了 o1。
如果这个平行成立,那么我们已经拥有的这些系统:能在一小时内学会行走的机器人、可以在其中导航的视频模型、以 r=0.995 匹配真实世界结果的预测;这就是物理 AI 的 GPT-2。这一切三年前都不存在。两条分别发展了数十年的研究脉络已经融合为真正的新事物:能够想象物理未来、实时响应动作、并将人类视频中的知识迁移到机器人上的机器。
这个赌注能否兑现,取决于「梦见世界」对于最难的操作任务是否真的重要 —— 那些光看足够多的例子还不够、需要预测推、拉、扭转时会发生什么的任务。我们认为它会。时间线比 100 亿美元所暗示的更不确定。
但借用 Jim Fan 的话来说:我们这一代人,生得太晚,错过了探索地球的时代;生得太早,又赶不上探索星际的时代。但我们或许恰好赶上了 —— 教会机器将物理世界梦入现实的时代。
参考文献
Schmidhuber, J. (1990). Making the World Differentiable. Technical Report FKI-126-90, TU Munich.
Craik, K. (1943). The Nature of Explanation. Cambridge University Press.
Oh, J. et al. (2015). Action-Conditional Video Prediction using Deep Networks in Atari Games. NeurIPS 2015.
Finn, C., Goodfellow, I. & Levine, S. (2016). Unsupervised Learning for Physical Interaction through Video Prediction. NeurIPS 2016.
Ha, D. & Schmidhuber, J. (2018). World Models. NeurIPS 2018. Interactive demos: worldmodels.github.io.
Hafner, D. et al. (2019). Learning Latent Dynamics for Planning from Pixels. ICML 2019. (PlaNet)
Schrittwieser, J. et al. (2020). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature. (MuZero)
Hafner, D. et al. (2020). Dream to Control: Learning Behaviors by Latent Imagination. ICLR 2020. (Dreamer V1)
Hafner, D. et al. (2021). Mastering Atari with Discrete World Models. ICLR 2021. (DreamerV2)
Nair, S. et al. (2022). R3M: A Universal Visual Representation for Robot Manipulation. CoRL 2022.
Kareer, S. et al. (2025). EgoMimic: Scaling Imitation Learning via Egocentric Video. ICRA 2025.
Baker, B. et al. (2022). Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos. NeurIPS 2022.
Wu, P. et al. (2022). DayDreamer: World Models for Physical Robot Learning. CoRL 2022. Project: danijar.com/project/daydreamer.
LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. OpenReview.
Hafner, D. et al. (2025). Mastering Diverse Domains through World Models. Nature. (DreamerV3)
Bruce, J. et al. (2024). Genie: Generative Interactive Environments. ICML 2024. (Genie 1)
Yang, S. et al. (2024). Learning Interactive Real-World Simulators. ICLR 2024 Outstanding Paper. (UniSim). Project: universal-simulator.github.io/unisim.
Valevski, D. et al. (2024). Diffusion Models Are Real-Time Game Engines. (GameNGen). Project: gamengen.github.io.
Yin, T., Huang, X. et al. (2025). From Slow Bidirectional to Fast Autoregressive Video Diffusion Models. CVPR 2025. (AR-DiT / CausVid)
Huang, X. et al. (2025). Self Forcing. NeurIPS 2025.
Hafner, D. & Yan, W. (2025). Training Agents Inside of Scalable World Models. (Dreamer 4)
Jang, J. et al. (2025). DreamGen: Unlocking Generalization in Robot Learning through Video World Models. CoRL 2025.
Gao, S., Liang, W. et al. (2026). DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos. Project: dreamdojo-world.github.io.
Ye, S., Ge, Y. et al. (2026). DreamZero: World Action Models as Zero-shot Policies. Project: dreamzero0.github.io.
Zheng, K., Niu, D. et al. (2026). EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data.
Physical Intelligence. (2025). Pi-0.5: a Vision-Language-Action Model with Open-World Generalization.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










