
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
然而,相比简单的代码推理或者和代码相关的聊天,coding agent 的 token 消耗也极为显著。在使用这种 coding agent 的过程中,最常听到的抱怨也是:“为什么它解决问题这么啰嗦”,“为什么要这么长篇大论”,以及 “为什么我的 credits 这么快又用完了?”
这些抱怨的背后暴露出当前 coding agent 的几大问题:
1. 不透明: coding agent 消耗 token 的习惯不清晰,行为模式以及不同模型之间的差异不透明;
2. 不保底:在任务执行前难以知道任务成功与否,但不论是否成功,都要支付相应开销;
3. 不可预测:人类估计的问题难度真的和实际的 token 消耗匹配吗?agent 能否自己判断问题会消耗多少 token 呢?
针对这些问题,来自密歇根大学、斯坦福大学等单位的研究者,使用开源的 OpenHands agent 框架,分析了 8 个 frontier 模型在 swe-bench-verified 上的轨迹,第一次给出了一份系统性的解答。

论文标题:HowDoAIAgentsSpendYourMoney? AnalyzingandPre dicting Token Consumption in Agentic Coding Tasks
arXiv 论文:https://arxiv.org/pdf/2604.22750
项目网站:https://longjubai.github.io/agent_token_consumption/
Agentic Coding 有多贵?
论文首先比较了和 coding 相关的 3 种任务:代码推理(和代码相关的单论对话推理任务),代码问答对话(关于代码问题的多轮对话聊天),以及 swe-bench 上的 agentic 代码任务。结果发现,agentic coding 任务在平均输出输入 token 比,平均总 token 消耗,以及平均金钱消耗,均指数级高于其他两种任务。
这源自于 agentic coding 任务的多轮交互和巨大而复杂的上下文管理:巨量的代码查询,文件输出都会被加入到对话历史中,导致消耗持续增加,并且 agent 会不断把历史上下文、工具输出反复喂给模型,导致输入输出比高达 154:1。这意味着 agentic coding 任务的成本结构与我们所熟悉的对话和推理任务有显著的不同。

Agentic Coding 的开销随机性高,
且花的越多不一定做得越好
论文统计了 swe-bench-verified 中 500 个问题的平均 token 消耗,并将消耗从小到大排序。从图中可以发现,最贵的任务可能比最便宜的任务多消耗约 700 万 token,并且越贵的任务 token 消耗的标准差也越大。
对同一任务的重复运行来说,通过计算最贵的一次运行和最便宜的一次运行的差异,结果发现即使是同一任务,最贵的运行仍可能比最便宜的运行贵 2 两倍左右。
进一步分析 token 消耗多少与准确率的关系,论文发现更多的消耗并不能保证更高的准确率。
对于不同任务来说,论文根据平均 token 消耗的数量进行分组,并统计每组任务的准确率,结果发现 token 消耗更多的任务往往准确率较低。
对于同一个任务的不同运行来说,将 4 次运行按照 token 消耗排序,分成四个开销等级,然后统计每一个开销等级的准确率。结果发现:平均所有模型来看,最高的准确率并不出现在开销最高的时候,而是出现在较低开销时。当开销最低时,任务运行的准确率最低,当提高开销稍微提高时,准确率达到最高,继续增加开销,当开销第二高和最高时,准确率不增反减 —— 更多的资源消耗并没有带来更高的任务成功率。
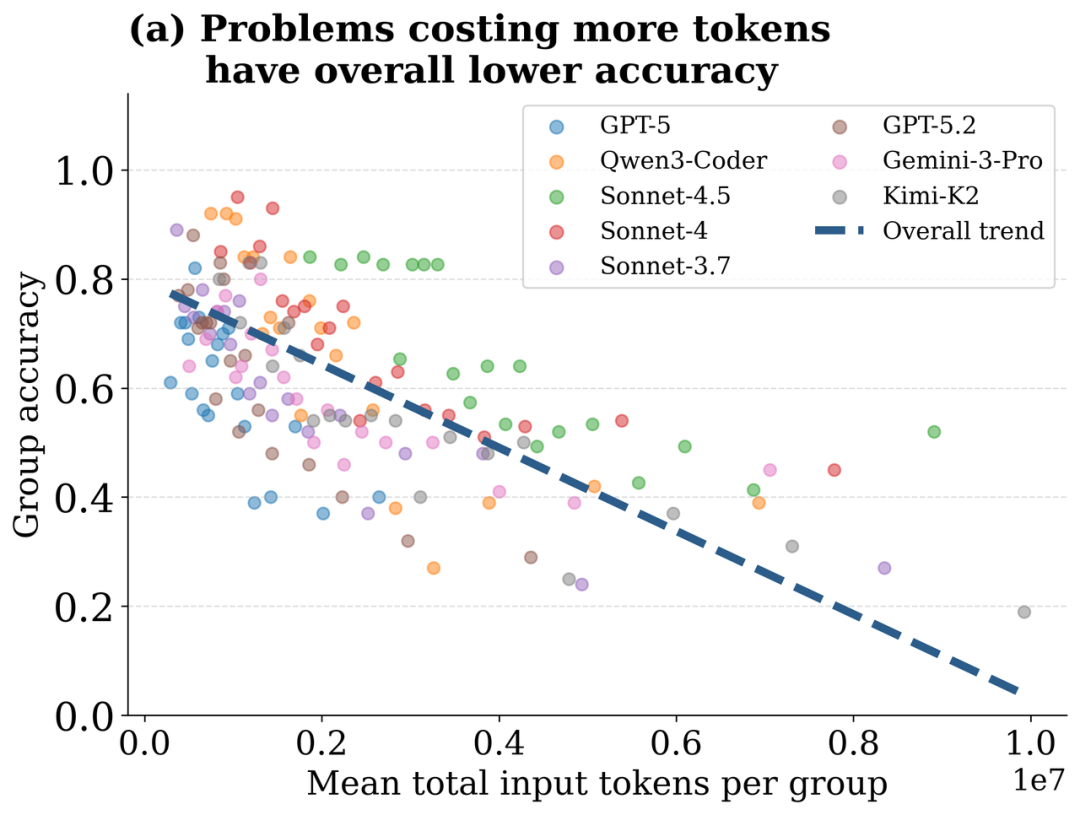

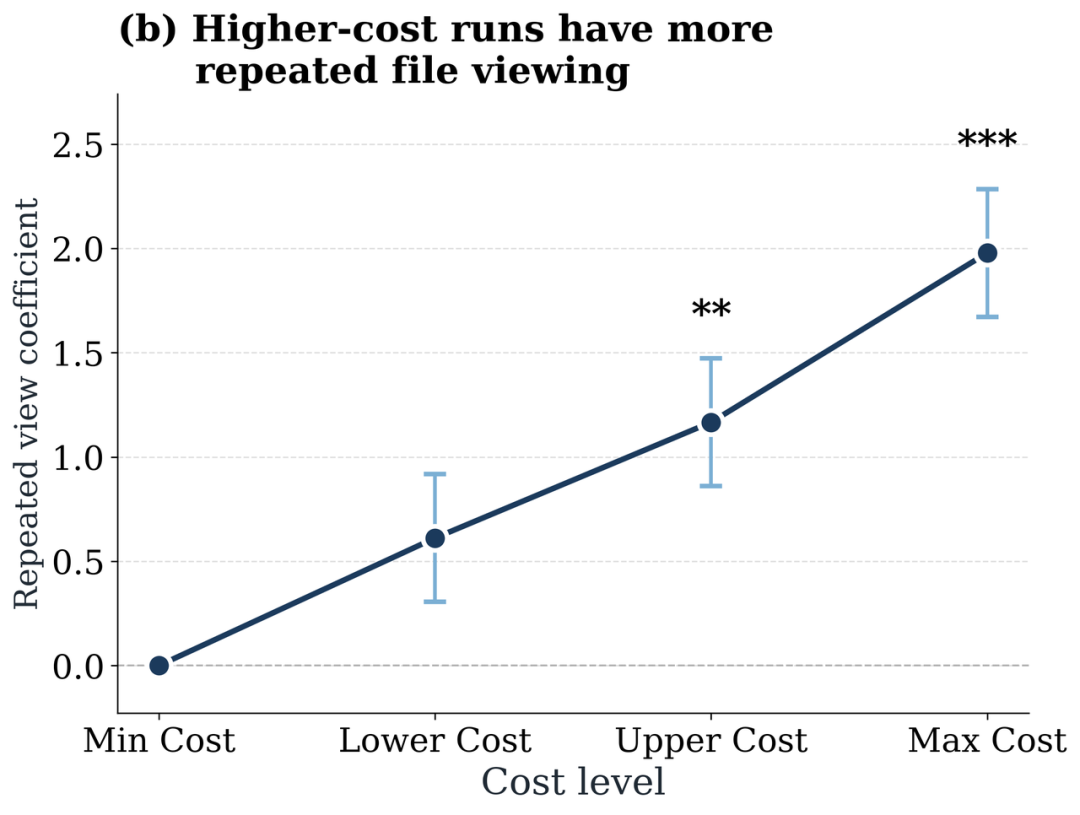
为了探索高开销失败背后的原因,论文检查并分析了 agent 解决问题轨迹中的两类行为:阅读文件以及修改文件。结果发现:开销更大的运行轨迹中,重复修改和重复查看同一文件的次数也明显更多,这表明更多的 token 消耗其实伴随了很多来来回回的 “折腾”,而不是高效的推理,尝试,和检查。简单来说,一味简单地堆 token 并不能显著带来更好的效果。

哪些模型贵,哪些模型省?
不同模型之间的 token 效率差异极大
以上的分析是基于所测试的 8 个模型的整体表现特点,在此基础上,论文对每个模型进行了具体的分析,并比较了他们使用 token 的效率。
文章测试的八个模型包括 OpenAI 的 GPT-5 和 GPT-5.2,Anthropic 的 Claude Sonnet-3.7、Claude Sonnet-4 和 Claude Sonnet-4.5,Google 的 Gemini-3-Pro Preview,Moonshot AI 的 Kimi-K2,以及阿里巴巴的 Qwen3-Coder-480B。这八个模型覆盖了五家不同的公司,同时包含闭源 API 模型(GPT、Claude、Gemini 系列)和开源模型(Kimi-K2、Qwen3-Coder-480B)。其中 Claude Sonnet 有三个版本、GPT 有两个版本,这样既包含了跨公司的横向对比,也有同一家族内不同代际的纵向对比。
通过观察不同模型的 token 消耗与任务准确率的关系,发现不同模型间的差异是系统性的,不是因为任务难度不同, 而是模型自身的行为习惯。例如 GPT-5 以及 GPT-5.2 可以以较低的 token 成本达到不错的准确率,但 Kimi-K2 在成本较高的同时准确率却并没有很高。在同样的 500 个任务下,Kimi-K2 和 Claude Sonnet-4.5 比 GPT-5 多消耗约 150 万 token。


论文进一步选出了两个任务子集:所有模型都成功的任务和左右模型都失败的任务,并再次统计不同模型的 token 消耗。结果发现模型的 token 消耗排序基本不变,并且所有模型在失败任务子集上的 token 消耗都多于成功子集,不同模型从失败子集到成功子集的 token 消耗增量也各不相同。
是否有办法对任务的 token 消耗
进行提前预测?
人类专家对任务难度的判断与 agent 实际 token 消耗并不完全吻合
当了解了 agentic coding 的开销后,下一个问题便是:在执行任务之前,是否有办法根据要执行的任务来预测开销?
文章首先分析人类专家所理解的任务难度是否可以作为预测 agent token 开销的标准。在 swe-bench-verified 中,每一个任务都有人类专家所标记的任务难度,按照人类专家预期的完成时间分为三档:“< 15 min”,“15 min - 1 hr”,“> 1 hr”。如果说人类消耗的时间就相当于 agent 消耗的 token,那么人类所估计的任务难度是否和 agent 的 token 开销是吻合的呢?

论文将不同任务根据 token 开销进行排序,并计算它与人类标注难度的相关性。结果发现 Kendall tau = 0.32,表明人类专家对任务难度的判断和 Agent 实际消耗的 token 之间只有很弱的相关性。
其中 6.7% 的 "简单" 任务比平均 "困难" 任务还贵,11.1% 的 "困难" 任务比平均 "简单" 任务还便宜 —— 更说明了人类程序员和 AI Agent 对任务的 "复杂度认知" 是不同的维度。
Agent 自己是否可以对任务的 token 消耗做出预测?
既然人类预测的任务难度和 agent 的实际任务消耗有所差异,那么是否可以让 agent 自己来预测自己的消耗?
论文紧接着对 agent 的自预测进行了尝试:在这部分实验中 agent 所有的工具和 harness 的架构都得到了保留,只有在系统提示词中将任务从之前的 “解决问题” 变成了 “预估开销”,这样一来,就可以最大程度的表流 agent 本身的特征和功能,并让它得以使用同样的工具对代码库进行多轮探索,测试和推理。

论文中用预测的开销和实际开销的相关性作为衡量预测准确率的指标,并同时统计了做预测所消耗的 token。结果显示,模型作出的预测与实际的相关性最高只有 0.39(Claude Sonnet-4.5 的 output token),大多数模型都在 0.2-0.3 之间,且对 output token 的预测比 input token 更加准确。在成本方面,大部分模型作出预测所需要的成本都小于实际任务执行成本的一半,除了早期的 Claude Sonnet-3.7 和 4,一度超过真正 task 执行成本的两倍。
文章进一步分析发现所有的模型都低估了任务的实际消耗,尤其对 input token 的低估特别严重。


因此,不管是人类专家还是 agent 自己,对 token 消耗预测目前只能作为粗粒度的信号,离精确的事前定价还有很大距离。
总结
文章通过对 coding agent 轨迹的分析,发现 Agent 的 token 消耗以 input token 为主导,且在不同问题之间以及同一问题的不同运行之间都存在很高的随机性。不同模型的 token 效率差异显著,且更多的 token 消耗并不能保证更高的正确率。在执行前成本预测方面,人类理解的任务难度与 Agent 的实际 token 消耗并不吻合,Agent 自身的预估也存在准确率较低和普遍低估的问题。未来潜在的研究方向包括更高效的 Agent 设计,以及更好的开销预测与管理方法。
作者介绍:
本文第一作者 Longju Bai 是密歇根大学一年级博士生,通讯作者 Jiaxin Pei 现为斯坦福大学博士后研究员,即将入职得克萨斯大学奥斯汀分校担任助理教授。合作者包括来自斯坦福大学的 Zhemin Huang 和 Erik Brynjolfsson,来自 All Hands AI 的 Xingyao Wang,来自 Google DeepMind 的 Jiao Sun,来自密歇根大学的 Rada Mihalcea,以及来自斯坦福大学和麻省理工学院的 Alex Pentland。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










