【区角快讯】当AI不再仅仅满足于生成几行孤立的代码片段,而是能够独立构建出可交互的完整Web应用时,大模型的竞争维度已然发生质变。5月26日凌晨,由知名第三方盲测平台LMArena推出的Code Arena榜单正式揭晓,这一被视为全球最具公信力的AI编程能力评测之一,迎来了新的格局变动。
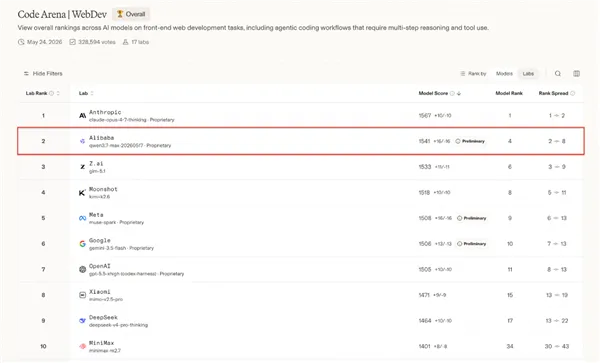
阿里最新旗舰模型Qwen3.7-Max在此次放榜中斩获1541分的高分。这一成绩不仅超越了GPT-5.5、Gemini-3.5-Flash、GLM-5.1以及Kimi-K2.6等一众强劲对手,更使其在大模型厂商排名中稳居全球第二,仅次于长期霸榜的Claude系列。值得注意的是,Qwen3.7-Max成为目前榜单中唯一突破1540分大关的国产大模型,标志着千问3.7在代码理解与生成领域,已成功跻身全球第一梯队。
与传统考核算法题或代码片段的基准测试截然不同,Code Arena要求开发者出题,让模型从零开始生成完整的、具备交互功能的Web应用程序。随后,这些匿名生成的成果交由用户进行两两PK投票,最终综合得出排名。这种基于真实使用体验的盲测机制,极大地提升了评测的含金量。经此严苛考验,千问3.7模型的编程能力位居前四,彻底打破了此前由Claude-Opus-4.7和4.6版本长期统治的前四格局。
作为面向Agent智能体场景深度打造的旗舰产品,Qwen3.7-Max在长程任务处理上展现出惊人的耐力与智慧。它不仅能将专业团队耗时两周的复杂项目压缩至数小时内完成端到端交付,显著提升企业级生产力,更能持续运行长达35小时,累计执行超过1000次工具调用,甚至自主完成芯片内核的编程优化。这种从“辅助编码”向“自主工程化”的跨越,或许正是下一代AI操作系统入口争夺战的关键信号。










