
点击蓝字 关注我们


论文标题页
Project Page:https://y-research-sbu.github.io/JET/
Article Source:ICML 2026
1 成果简介
高质量脑电生成,对于缓解大规模神经建模中的数据稀缺与隐私约束至关重要。然而,现有方法大多以离散去噪的目标来表述 EEG 生成,难以契合神经活动本身连续的时间动态与频谱结构,导致生成信号常常无法保持长程时间依赖,并在频谱、时间结构上与真实数据错位。
本文主张:有效的脑电生成,应当直接作用于神经信号的连续演化过程。为此,作者提出 Just EEG Transformer(JET),一个基于条件流匹配(Conditional Flow Matching)的生成框架,把多通道 EEG 看作沿连续轨迹演化的原始序列,通过学习一个把噪声“运输”到真实脑电分布的平滑向量场,在不依赖离散去噪、也不依赖特定领域表征的前提下,捕捉脑电的时间连续性与瞬态动态。为使学到的动力学与脑电关键性质保持一致,作者进一步引入三条结构保持约束,分别约束频谱结构、时间平稳性与信号统计量。在 TUAB、TUEV、TUSZ 三个大规模基准上,JET 将衡量频谱-时间保真度的TS-FID 相比强基线降低 40% 以上;大量分析表明,JET真正捕捉到了神经动力学的关键结构,为现实数据约束下的脑电生成提供了一条可扩展且原则化的路径。
2 主要工作
本文围绕「把脑电生成重新建模为连续动力学」这一核心思想展开,主要贡献如下:
•重新表述生成范式。 把 EEG 生成形式化为一个连续动力学过程,提出流匹配框架 JET,摆脱了主流的离散去噪范式。
•用标准 Transformer 直接建模原始脑电序列。证明在原始多通道 EEG 上使用 Transformer,能够有效捕捉长程时间依赖与动态的通道间结构,而无需手工特征或预设连接先验。
•导出结构保持约束。 从脑电的统计性质出发,推导出一组“重建 / 统计 / 时空”三位一体的约束,使生成的流尊重脑电的频谱、时间与统计性质,而非随意的正则项。
•刷新三大基准并给出可信分析。 在三个大规模基准上取得最优性能,TS-FID 降低 40% 以上;更重要的是,合成数据真正带来了正向的下游分类增益,这正是以往生成方法普遍做不到的一点。
3 方法概述
JET 的设计哲学是「少即是多」:尽量去掉为脑电手工设计的归纳偏置,让标准Transformer 在数据与约束的共同引导下,端到端地学习神经状态空间。其整体流程如图 1 所示,以病理状态(如癫痫发作)为条件,通过流匹配学习连续向量场 v(xₜ, t),再由结构保持约束进行正则化,最终生成多通道脑电。
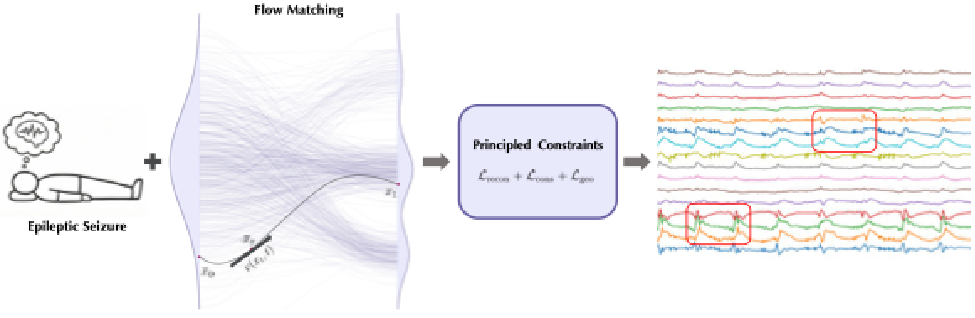
图 1:JET 流程示意。模型以病理状态为条件,通过流匹配学习把高斯噪声运输到真实脑电分布的连续向量场,并由编码了频谱、时间与统计性质的结构保持约束进行正则,最终生成多通道 EEG。
在表述上,给定标准高斯先验样本 x₀ 与真实脑电样本 x₁,JET 在二者间定义线性插值路径 xₜ = t·x₁ + (1−t)·x₀,并训练网络去预测目标向量场 x₁ − x₀;推理时只需从噪声出发求解常微分方程即可采样。框架的关键模块包括:
•原始脑电 Tokenization。将多通道片段 X ∈ ℝ{C×T}沿时间轴切分为非重叠 patch 并线性投影到 D 维嵌入;与展平空间维度的标准 ViT 不同,JET 在初始嵌入阶段保留通道身份,以维持空间结构。
•Transformer 骨干 + AdaLN 条件注入。 沿用 DiT 与 JiT 的做法,将时间步 t 与类别标签 c 通过自适应层归一化注入,使整个生成过程在流轨迹上始终可控;自注意力的全局感受野让模型能够同时刻画远距离时间点与跨通道的依赖。
•自适应类别均衡采样。 针对临床脑电严重的类别不平衡(正常背景远多于癫痫等罕见事件),为样本赋予正比于 1/Nα的采样概率,构造类别期望频率近似均匀的训练分布,避免对主导类别的过拟合。
•三条结构保持约束。 标准流匹配的欧氏回归损失对重尾、非平稳、有结构频谱的脑电并不适用,作者据此引入:① 对应拉普拉斯先验的 L₁ 重建约束,抑制冲激式伪迹、保留尖锐神经事件;② 统计一致性约束,对齐生成信号与真实数据的一阶、二阶矩,防止幅度漂移;③ 时空结构约束,以时间总变差(TV)保持谱平滑,并用皮尔逊相关对齐波形形态。三者与流匹配目标共同构成总目标L_total = L_recon + L_cons + L_geo。
4 结果
作者在 TUH Corpus 的 TUAB(异常)、TUEV(事件)、TUSZ(癫痫)三个大规模数据集(合计超过 1 万次临床会话)上评测 JET,采用三维协议:衡量频谱保真度的 TS-FID(越低越好)、用以排除模式塌缩的 Silhouette 分数(越高越好),以及用合成数据增强 CBraMod 分类器后的下游准确率增益 ΔAcc(越高越好)。
(1)流匹配真的比离散去噪更适合脑电吗?
如图 2 的玩具实验所示,在螺旋、8-高斯、双月三种数据流形上,GAN 把噪声直接映射到数据空间、容易丢失结构,扩散模型依赖随机去噪路径、边界弥散,而流匹配学到的平滑向量场最贴近真实分布,这正是 JET 选择流匹配作为骨架的直观依据。

图 2:三种生成范式在不同流形上的对比。从左到右依次为真实分布、GAN、扩散模型与流匹配。流匹配(最右列)在三种流形上都最贴合真实分布(最左列)。
落到脑电基准上,结论同样成立。如表 1,JET 在所有指标、所有数据集上均取得最优:TS-FID 大幅领先,说明其真正捕捉到了标准扩散与 GAN 难以建模的复杂频谱-时间动态;Silhouette 分数稳定逼近满分(基线仅在 0.66–0.89 间徘徊),表明生成样本严格遵循条件标签、未出现模式塌缩;而在最能体现实用价值的 ΔAcc 上,基线带来的提升微乎其微甚至为负,JET 却一致带来正向增益,证明其合成数据在分布上与真实数据对齐。在效率上,生成一个批次(32 条 10 秒样本)JET 仅需 4.78 秒,扩散模型为 7.01 秒,取得了最优的「保真度—延迟」权衡。
表 1:TUAB、TUEV、TUSZ 上的定量对比(加粗为最优)。
方法 | TUAB TS-FID↓ | Sil.↑ | ΔAcc↑ | TUEV TS-FID↓ | Sil.↑ | ΔAcc↑ | TUSZ TS-FID↓ | Sil.↑ | ΔAcc↑ |
EEG-GAN | 324.18 | 0.786 | +0.000 | 448.65 | 0.667 | −0.004 | 274.37 | 0.891 | +0.001 |
Vanilla Diffusion | 342.91 | 0.710 | −0.002 | 415.82 | 0.703 | −0.000 | 300.47 | 0.746 | +0.000 |
JET | 188.27 | 0.995 | +0.029 | 235.86 | 0.983 | +0.032 | 151.27 | 0.987 | +0.017 |
(2)JET 能否克服谱偏置、还原真实的频谱结构?
如图 3,在 0–5 Hz 的 δ 频段(承载高幅病理慢波与基础节律),生成谱与真实谱几乎完全重合;在 8–13 Hz 的 α 频段,JET 复现出清晰的节律峰,而非塌缩为一条平滑的 1/f 曲线,说明它学到的是具体的振荡特征而非边缘统计;在 15 Hz 以上则呈现轻微衰减,反映出模型对无结构高频噪声(如肌电、传感器噪声)的选择性抑制,优先保留有生理意义的神经活动。

图 3:频谱结构评估。JET 准确刻画了 1/f^χ 的谱标度与显著的 α 频段峰值,缓解了以往方法在高频成分上的谱偏置。
(3)JET 能否刻画非平稳的时间动态而不发生漂移?
如图 4,生成信号的中位数在整个时间窗内始终围绕真实信号居中,没有出现长序列生成中常见的基线漂移;分位带与真实数据保持对齐,避免了误差累积导致的方差爆炸或塌缩。作者进一步用通道聚合 RMS 包络的逐段统计量(斜率漂移、首尾矩漂移)与真实数据做1-Wasserstein 距离比较(表 2):JET 的漂移距离稳定在「真实对真实」基线的 2 倍以内,而 EEG-GAN 与扩散模型则相去甚远。
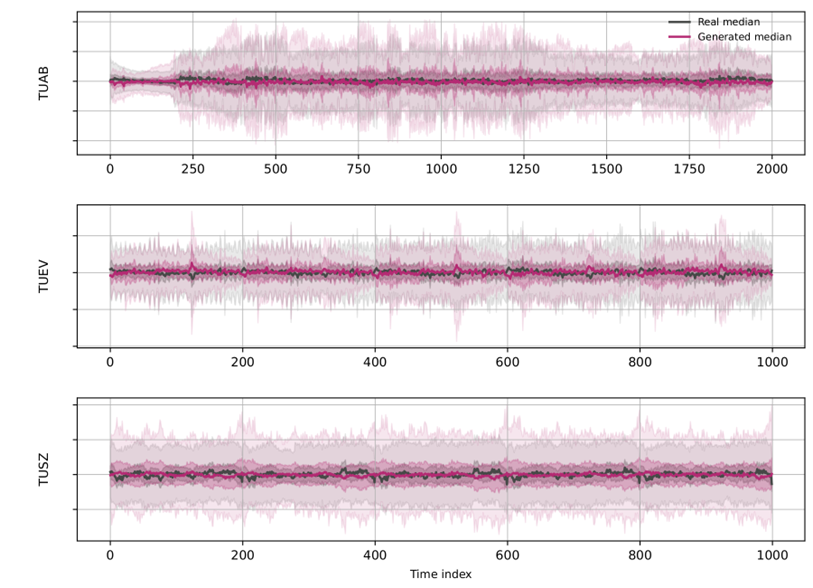
图 4:时间动态评估。JET 在刻画随时间变化的非平稳能量起伏的同时,保持了稳定的幅度统计,避免了基线漂移与方差塌缩。
表 2:TUEV 上的虚假漂移分析(1-Wasserstein 距离,越低越好)。
方法 | W₁(slope)↓ | W₁(Dμ)↓ | W₁(Dσ)↓ |
Real split(基线下界) | 0.008 | 0.012 | 0.010 |
EEG-GAN | 0.065 | 0.078 | 0.071 |
Vanilla Diffusion | 0.051 | 0.063 | 0.058 |
JET(本文) | 0.015 | 0.021 | 0.018 |
(4)JET 能否对齐重尾分布、避免模式塌缩?
如图 5,在有效信号窗内,生成的对数密度与真实分布高度吻合,既复现了尖锐的中心峰,也复现了重尾衰减;同时在群体层面,生成与真实的频谱方差包络大幅重叠,说明模型保留了被试间、状态间的多样性,而非收敛到单一确定性轮廓,从根本上规避了高斯先验常见的模式塌缩。

图 5:幅度分布分析。对数密度直方图证实,JET 准确重建了原始脑电非高斯、重尾的幅度分布,覆盖了病理记录中多样的幅度范围。
(5)噪声空间与各项约束,是否真的缺一不可?
是。其一,把高斯噪声换成确定性的零噪声会带来灾难性退化(TS-FID 从 188 飙升至1615 以上),从连续归一化流的视角看,这等价于强迫模型把单个奇点扩张成高维多峰分布,是一个病态的一对多映射;高斯噪声提供的高熵概率空间在维度上与目标流形匹配,才能让概率流平滑形变到脑电流形之上。其二,如表 3,仅有重建项时表现最差,逐项加入统计、TV 与相关约束后 TS-FID 单调下降,完整目标取得最优,印证了同时约束信号能量、平滑度与形态的设计是合成生理有效脑电的关键。
表 3:结构保持约束的消融(TS-FID↓,✓ 表示启用该约束)。
重建 | 统计 | TV | 相关 | TUAB | TUEV | TUSZ |
✓ | 231.19 | 287.81 | 221.74 | |||
✓ | ✓ | 228.87 | 281.70 | 209.99 | ||
✓ | ✓ | 219.45 | 266.61 | 210.00 | ||
✓ | ✓ | 221.26 | 278.01 | 200.87 | ||
✓ | ✓ | ✓ | ✓ | 188.27 | 235.86 | 151.27 |
5 研究结论
本文把脑电合成重新表述为一个由流匹配与结构保持约束共同支配的连续动力学过程。大量实验表明,这一范式在取得 SOTA 保真度的同时,稳定地捕捉到了脑电的关键统计与动力学性质:功率律谱结构、非平稳时间动态与重尾幅度分布;并让合成数据在下游分类任务上带来一致的正向增益(而这正是以往生成方法普遍难以实现的)。作者认为,JET 为在现实数据约束下推进数据驱动的神经建模,提供了一个可扩展且原则化的基础,也为脑机接口领域长期面临的「数据瓶颈」给出了一条新的解题思路。
更多方法推导、完整实验与可视化分析,详见项目主页:https://y-research-sbu.github.io/JET/
免责声明:原创仅代表原创编译,水平有限,仅供学术交流,如有侵权,请联系删除,文献解读如有疏漏之处,我们深表歉意。



公众号丨智能传感与脑机接口










