在大语言模型(LLM)浪潮席卷全球的今天,从智能对话到代码生成,再到企业自动化,AI应用正经历着前所未有的范式转移。然而,当我们将这些动辄数百亿甚至上千亿参数的“庞然大物”推向实际生产环境时,挑战才刚刚开始。传统的推理系统在设计之初从未考虑过如此巨大的计算与内存需求,模型规模与可部署性之间的鸿沟,已成为制约AI技术真正赋能产业的关键瓶颈。
想象一个典型的在线服务场景:用户提交一个问题,系统需要在毫秒级内返回首个词元,并保持流畅、持续的生成。这背后涉及模型权重的快速加载、对超长上下文的记忆管理、对海量并发请求的高效调度,以及对异构计算资源的灵活利用。任何一个环节的延迟或低效,都会直接影响用户体验和业务成本。这正是阿里云基础模型推理团队在服务淘宝、天猫、菜鸟等业务,面对超过一亿用户时,每天都需要解决的现实难题。

为了系统性地应对这些挑战,阿里云联合北京大学、浙江大学的研究人员,推出了RTP-LLM——一个为工业级大语言模型部署设计的高性能推理引擎。它并非对现有系统的修修补补,而是从底层架构出发的全栈式重构,旨在打通从模型加载到请求响应的每一个瓶颈。

论文标题:RTP-LLM: High-Performance Alibaba LLM Inference Engine
论文链接:https://arxiv.org/pdf/2605.29639
开源仓库地址:https://github.com/alibaba/rtp-llm
工业级部署的四大核心挑战
在深入RTP-LLM的技术细节之前,我们首先需要理解当前大语言模型推理在生产环境中面临的根本性难题。这些挑战相互交织,构成了一个复杂的系统性问题。
挑战一:动态序列工作负载下的GPU利用率低下。 生产环境的请求模式极具动态性:输入长度从简短查询到超过128K词元的长文档不等,输出长度也千差万别。自回归生成的内存访问密集型特性,使得强大的计算单元常常处于“饥饿”等待状态。而静态的批处理策略无法适应这种请求动态,导致不可预测的延迟和低下的吞吐量。
挑战二:不受控的KV Cache增长导致内存耗尽。 键值缓存(KV Cache)是注意力机制中用于存储中间状态的关键数据结构,其大小随序列长度和批次大小线性增长,并迅速成为内存消耗的“大户”。传统的内存分配器难以处理这种可变大小的内存需求,导致碎片化和低效的内存共享。随着模型支持的上文越来越长,内存管理已成为限制并发和可扩展性的硬约束。
挑战三:面对架构异构性的系统僵化。 现代模型架构日趋复杂。超过6000亿参数的混合专家模型(MoE)需要高效的专家路由和快速的权重加载;而多模态模型则结合了视觉编码器和语言模型,两者具有完全不同的计算特性和执行模式,需要在异构计算组件间进行协调执行。现有系统往往难以高效处理这种多样性。
挑战四:阻碍快速迭代的运营脆弱性。 企业级部署要求能够在分钟级别内加载6000亿以上参数的模型,以实现跨业务单元的持续更新。现有系统加载权重需要数小时,且缺乏生产级的容错、滚动更新机制以及按请求的性能隔离能力,难以在波动负载下满足严格的延迟服务等级目标。
RTP-LLM正是为了系统性地解决这四大挑战而生,其设计哲学在于集成优化与全栈协同,而非孤立地改进单个组件。
系统架构全景:从请求到响应的智能调度
RTP-LLM的系统架构是一个精心设计的分布式系统,其核心思想是将推理过程的不同阶段进行解耦与专业化处理,并通过全局调度器实现资源的最优配置。

图1:RTP-LLM系统架构概览。展示了前端应用、主调度器、预填充节点、解码节点以及多级缓存之间的协同工作流程。
整个系统的工作流程可以概括为:用户请求首先到达前端应用,进行分词和元数据提取后,被同步转发至主节点。主节点作为系统的“大脑”,负责全局的流量调度与协调。它维护着系统状态的全局视图,包括工作节点可用性、KV缓存分布和当前负载情况,从而做出最优的调度决策。
RTP-LLM支持两种部署策略:PD融合与PD解耦。PD融合指预填充和解码阶段在同一节点内执行;而PD解耦(如图1所示)则将这两个计算阶段物理分离到专用节点上。解耦架构允许根据预填充(计算密集型)和解码(内存带宽密集型)的不同特性,进行独立的资源扩展和优化,这是提升大规模部署效率的关键。
多级缓存是RTP-LLM提升内存效率的核心组件。它实现了一个跨越GPU内存、本地CPU内存(通过RDMA访问的)远程CPU内存以及分布式存储的层次化存储系统。这种设计使得KV缓存能够在不同请求间高效复用,同时最小化内存带宽压力。当主节点调度请求时,会通过前缀匹配算法,在多层缓存中寻找可复用的KV缓存块,优先从最快的存储层(GPU内存)加载,从而显著减少重复计算。
核心技术突破:贯穿推理生命周期的优化
分钟级模型加载:为快速迭代奠基
部署一个数百亿参数的大模型,第一步就是将其权重加载到GPU内存中。在分布式环境中,尤其是在阿里云生产环境使用的FUSE云存储系统上,传统的按模型结构加载方式效率低下。每个张量并行进程都需要读取所有模型文件以提取其分配的部分,导致冗余的文件读取和非顺序的访问模式,严重拖慢了加载速度。
RTP-LLM通过一系列组合优化彻底改变了这一过程。其核心是将加载范式从“模型结构驱动”转变为“文件顺序驱动”。系统按文件顺序依次读取,并一次性加载单个文件中的所有张量,这确保了顺序的文件访问模式,最大化了存储系统的预取效率。
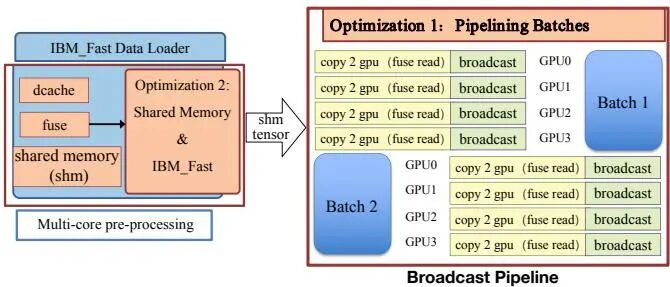
图2:模型加载优化策略。通过文件顺序驱动加载、混合分布式读取、共享内存复用和并行I/O-通信重叠,大幅提升大模型加载速度。
此外,RTP-LLM集成了IBM的fastsafetensors库,采用混合分布式读取策略:每个模型文件仅由一个进程读取,然后通过PyTorch分布式广播高效地与其他进程共享张量,消除了进程间的冗余读取。系统还复用了共享内存缓冲区,避免了每次文件读取时的重复分配开销,并将文件读取操作与张量广播并行化,进一步降低了总体加载延迟。
这些优化效果显著。在Qwen3-235B这样的大规模模型上,RTP-LLM的加载速度相比vLLM和SGLang提升了4.7倍至6.3倍,将加载时间从数分钟缩短到半分钟以内,为实现模型的分钟级弹性伸缩和快速迭代奠定了基础。
预填充-解码解耦:让专业的人做专业的事
大语言模型的推理过程天然分为两个阶段:预填充阶段和解码阶段。预填充阶段并行处理整个输入提示,生成所有提示词元的KV缓存,并产生第一个输出词元,此阶段是计算密集型的。解码阶段则自回归地生成后续词元,主要依赖对已有KV缓存的访问,是内存带宽密集型的。
RTP-LLM的预填充-解码解耦架构将这两个阶段物理分离到不同的专用计算资源上。预填充节点可以专注于处理大批次请求以最大化吞吐量,而解码节点则可以优化为低延迟的内存访问模式,处理高并发的生成请求。这种解耦允许两者独立扩展,根据实际流量模式灵活调配资源。
在生产环境中,这种架构优势明显。例如,在部署Qwen3-Coder-480B-FP8这样的超大规模MoE模型时,RTP-LLM采用4个节点负责预填充、1个节点负责解码的不对称分配。结果显示,其首词元延迟(TTFT)相比SGLang和vLLM降低了4.7倍以上,同时缓存命中率提升了1.5倍以上。这意味着用户能更快地获得响应,而系统可以用更少的机器资源支撑相同的服务。
智能流量调度与KV缓存管理:化静态为动态
面对动态多变的生产流量,一个“聪明”的调度器至关重要。RTP-LLM的主节点实现了复杂的负载均衡策略。对于预填充请求,它会将序列长度相似的请求分组,以最小化填充开销,并基于各工作节点的实时负载(运行/等待请求数、GPU内存、KV缓存占用率)进行预测性调度,将请求分配给预计最先完成的工作节点。
对于解码请求,调度器则优先考虑KV缓存亲和性。如果一个请求带有聊天ID,并且该聊天会话之前被分配给了某个工作节点,调度器会尽可能将新请求路由到同一节点,以便直接复用本地缓存的KV状态,避免远程加载带来的延迟。
KV缓存的高效管理是另一大亮点。RTP-LLM采用基于哈希的前缀匹配机制。本地KV缓存管理器将所有工作节点的缓存键聚合到一个统一的哈希映射中,使得前缀匹配的复杂度从O(B×W)降低到O(B)(B为块数量,W为工作节点数),极大提升了匹配效率。此外,系统还采用了采样前缀哈希技术,在匹配精度和元数据存储开销之间取得平衡。
通过将智能调度与高效缓存管理相结合,RTP-LLM在真实的阿里内部机器人问答和淘宝商家客服咨询场景中,将TTFT的P95延迟降低了35%-37%,并将缓存复用长度提升了超过200%,使得在保持平均TTFT性能的前提下,预填充机器数量减少了75%。
推测解码:打破自回归的序列瓶颈
自回归生成本质上是顺序的,每个词元的生成都依赖于前一个词元,这限制了GPU的并行利用率。推测解码是一种通过“猜测”未来多个词元并并行验证来加速这一过程的技术。
RTP-LLM实现了一个模块化的推测解码框架,支持多种算法,包括:
朴素推测解码:直接使用更小的模型作为提议模型。 多词元预测(MTP):在一次前向传播中预测多个后续词元(如DeepSeek-V3所用)。 Eagle:通过训练自回归头来预测未来的隐藏状态。 提示词查找:针对输入提示进行N-gram匹配,直接提取候选词元,特别适用于代码编辑等可提取场景。
该框架将推测解耦分为四个模块:提议执行器、评分执行器、推测采样器和推测更新器,保持了组件的松散耦合和算法的可扩展性。在实际部署中,例如为在线商家数据智能体服务提供支持的Qwen3-235B MoE模型上,启用多词元预测后,系统在保持输出质量的同时,有效提升了生成速度。
面向未来的运行时扩展
为了支持多样化的模型和硬件,RTP-LLM还集成了多项运行时优化:
多层次并行执行:综合运用张量并行、流水线并行、数据并行和专家并行,以分布式方式承载千亿参数模型,最小化首词元时间并最大化系统吞吐量。 自适应量化技术:同时采用仅权重量化(如AWQ、GPTQ)和KV缓存量化。将KV缓存从FP16/BF16量化为INT8或FP8,可直接将缓存大小减半,显著缓解解码阶段的内存带宽压力,支持更大的批处理规模和更长的上下文。 解耦的多模态处理:对LLaVA、Qwen-VL等多模态模型,RTP-LLM采用视觉编码器与语言模型解耦部署的策略。视觉编码和语言生成可以在不同的流上执行,避免了计算争用。在高并发下,这种设计可以实现计算重叠,提升整体性能,同时减少单设备的实际GPU内存占用。

图3:视觉编码器-语言模型解耦部署架构。ViT模型和LLM独立部署,通过嵌入数据连接,实现了计算过程的分离与重叠。
性能实测:在基准与生产流量中的表现
研究团队对RTP-LLM进行了全面评估,对比对象包括vLLM和SGLang这两个业界知名的开源推理引擎。测试涵盖了从8B到235B的不同参数规模模型,并同时使用了可控基准测试和真实生产流量。
模型加载性能:如图4所示,对于中等规模模型(8B-32B),RTP-LLM在不同张量并行配置下实现了1.4倍至4.2倍的加载加速。对于Qwen3-235B这样的大模型,加速比达到4.7倍至6.3倍,且在高TP配置下性能优势更明显,展现了卓越的并行加载效率。
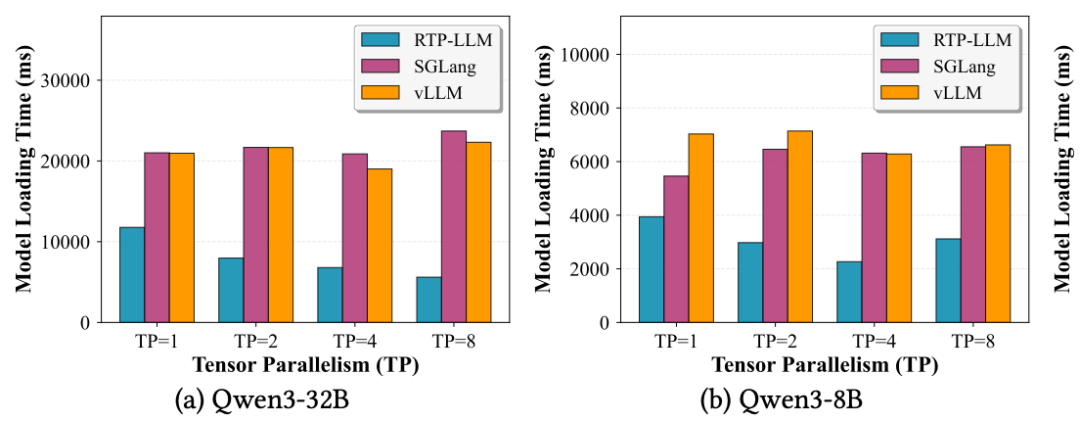

图4:中等规模模型(8B-32B参数)在不同TP配置下的模型加载时间对比。RTP-LLM(蓝色)在多数情况下显著优于SGLang(酒红色)和vLLM(橙色)。
量化推理效率:在Qwen3-32B模型上测试不同的量化配置(AWQ(FP8)、FP8 KV缓存、基线)。结果显示,RTP-LLM在FP8 KV缓存配置下实现了35%-40%的批次延迟降低,同时首词元时间(TTFT)相比基线框架有1.9倍至3.0倍的改善,而精度损失(PPL)控制在可接受范围内。
多模态推理性能:在GQA基准数据集上测试Qwen-VL-7B模型。得益于解耦的EPD架构,RTP-LLM的吞吐量达到SGLang的1.86倍、vLLM的2.52倍;首词元延迟则分别降低了2.36倍和2.12倍。其内存使用也呈现出高效的不对称分布,视觉编码GPU占用远低于语言生成GPU。
推测解码增益:使用DeepSeek-V3模型测试,RTP-LLM的推测解码吞吐量分别比vLLM和SGLang高出1.12倍和2.48倍。
这些数据共同表明,RTP-LLM不仅在各项独立指标上领先,更重要的是其全栈集成的设计使得各项优化技术能够协同作用,在复杂的真实生产环境中稳定交付高性能。
总结与展望
RTP-LLM是阿里云在大语言模型工业级部署领域交出的一份系统性答卷。它从生产实践中的核心痛点出发,通过集成化的设计,在模型加载、内存管理、计算调度、并行策略、量化加速和多模态支持等维度进行了深度优化。其价值不仅在于一系列的性能提升数据,更在于提供了一套经过超亿级用户生产环境验证的、完整的推理系统架构与工程实践。
该系统现已开源,为社区和业界提供了一个可扩展、高性能的推理引擎基础。开源意味着更广泛的协作与创新,开发者可以基于RTP-LLM构建自己的应用,研究人员可以深入探索其设计细节。
展望未来,大语言模型推理优化之路仍很长。RTP-LLM团队表示将继续探索如深度求索稀疏注意力等更先进的加速技术,并持续优化系统以适应不断演进的模型架构和硬件生态。随着模型规模的持续增长和应用场景的不断深化,像RTP-LLM这样着眼于全栈、注重系统协同的推理引擎,将成为释放大语言模型真正潜力的关键基础设施。
> 本文由 Intern-S2 等 AI 生成,机智流编辑部校对
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群