> 作者:李剑锋
1. 前言
1.1 课程回顾
在中,我们已经围绕大模型训练与模型测评,逐步梳理了从数据构建、监督微调、参数高效调优到效果评估的基本流程。到这一阶段为止,实际上已经回答了两个关键问题:一是模型能否学习到目标能力,二是模型能力提升是否能够被验证。
但是,对于大模型应用落地而言,训练和测评并不是完整链路的终点。一个模型即使完成了微调,并且在评测中取得了相对理想的结果,如果它仍然停留在本地权重文件、实验脚本或一次性的推理调用中,那么它的工程价值仍然是有限的。
真正可用的大模型能力,通常需要进一步具备几个特征:模型能够被稳定加载,能够在给定硬件资源下持续运行,能够响应外部请求,能够通过统一接口被程序调用,并能够进一步接入 Web 应用、RAG 系统、Agent 应用或其他业务系统。也就是说,大模型需要从“训练产物”进一步转变为“可调用、可复用、可集成的模型服务”。
这一转变过程,正是模型部署要解决的核心问题。
从概念上看,模型部署并不只是“把模型运行起来”这么简单。更准确地说,模型部署是指将训练完成或准备使用的模型,放置到实际运行环境中,并通过一定的推理框架、服务接口和资源配置,使其能够稳定地对外提供推理能力的过程。它既包括模型加载、推理执行、显存与内存管理等底层运行问题,也包括 API 服务、请求处理、并发访问、接口兼容和应用集成等工程问题。
因此,模型部署连接了模型训练与实际应用。一方面,它承接训练和微调之后得到的模型权重,使模型能够真正运行起来;另一方面,它又面向具体应用场景,为上层系统提供可调用的智能能力。例如,一个完成微调的问答模型,如果只是保存在本地目录中,它还只是一个模型文件;只有当它能够被稳定启动,并通过接口被前端页面、知识库问答系统或智能体程序调用时,它才真正进入应用链路。
从部署目标来看,不同阶段对模型部署的要求并不完全相同。在原型验证阶段,我们可能更关注模型能否快速运行、能否方便调用、能否完成基础功能测试;在应用开发阶段,我们会进一步关注接口形式是否统一、是否能够接入现有开发框架、是否支持流式输出、多轮对话或结构化返回;而在生产环境中,则还需要关注推理速度、并发能力、显存利用率、量化优化、服务稳定性和运维管理等问题。
也正因为如此,模型部署是一个层次较多的工程环节。它既可以是本地电脑上的轻量模型运行,也可以是服务器上的 API 服务部署;既可以是单用户的实验环境调用,也可以是面向多用户请求的高性能推理服务。不同工具和框架的差异,本质上也来自它们对这些部署目标的侧重点不同。
因此,在完成训练与测评之后,继续学习模型部署,是理解大模型完整技术链路中非常自然的一步。只有理解模型如何从权重文件变成可调用服务,才能进一步理解大模型如何真正接入应用系统,并在实际场景中持续发挥作用。
1.2 常见的模型部署工具
在理解了“模型部署”所要解决的问题之后,接下来需要进一步回答一个更加工程化的问题:当我们希望把一个模型真正运行起来,并进一步对外提供调用能力时,究竟可以选择哪些部署工具?
从更专业的角度看,这些工具虽然都服务于“模型推理与服务化”这一共同目标,但它们所处的抽象层级并不相同,优化重点也并不一致。有些工具首先关注的是高吞吐、低延迟与生产级服务能力;有些工具强调的是本地快速运行与低门槛接入;还有一些工具则更适合作为从原始模型调用逐步过渡到服务部署的中间路径。因此,与其简单地把它们看成一组“谁替代谁”的关系,不如把它们理解为面向不同部署目标的不同技术方案。
从部署目标来看,第一类工具更适合归入高性能推理服务框架。这一类的代表主要包括 vLLM、SGLang 以及 TGI(Text Generation Inference)。其中,vLLM 官方文档明确将其定位为既可做离线批量推理,也可用于 OpenAI 兼容在线服务 的推理框架;

SGLang 则明确强调自己是面向 大语言模型与多模态模型 的高性能服务框架,目标是在从单卡到大规模分布式集群的不同场景下提供低延迟、高吞吐推理。

相比之下,TGI 虽然仍然是 Hugging Face 体系中的重要部署项目,但 Hugging Face 官方文档已经明确说明 TGI 自 2025 年 12 月 11 日起进入 maintenance mode,后续主要接受轻量维护,并建议更多关注 vLLM 与 SGLang 等替代方向。换句话说,这一类工具的共同特点,不是“能不能把模型跑起来”,而是更进一步关注请求调度、吞吐能力、并发处理、批处理优化以及生产级服务稳定性。

第二类,是面向本地快速运行与轻量接入的工具,例如 Ollama、LM Studio 以及 llama.cpp / llama-cpp-python。这类工具的特点通常不是追求最高级别的服务吞吐,而是尽可能降低模型本地运行的门槛。例如,Ollama 官方提供了 Windows 安装器;LM Studio 可以在本地启动 API Server,并提供 OpenAI 兼容接口;

llama-cpp-python 也提供了 OpenAI API compatible web server,可以直接把本地模型以 Web 服务方式暴露出来。因此,这一类工具通常更适合本地体验、快速实验、小型 demo 以及对“尽快跑起来”要求更高的场景。

第三类,是更偏向通用框架与代码级控制的 Python 方案,例如 Transformers 和 LMDeploy。这类工具的一个重要特点是,它们不仅可以用于最基础的模型加载与推理,也可以进一步扩展到 API 服务部署。Transformers 本身是 Hugging Face 的通用模型框架,支持文本、视觉、音频、视频和多模态模型;同时,官方已经提供 transformers serve 命令,可以直接启动一个 兼容 OpenAI SDK 的本地服务。LMDeploy 则是一个面向 LLM 与 VLM 的压缩、部署和服务化工具包,官方文档给出的核心能力包括离线推理、OpenAI 兼容服务、量化以及不同推理后端支持;其安装文档也明确写到,它支持在 Linux 和 Windows 平台上部署 LLM 和 VLM。

如果再从操作系统与实验环境的角度来看,这些工具之间的差异会更加明显。vLLM 等高性能推理框架往往更适合 Linux 服务器环境,在 Windows 上通常需要借助 WSL 或其他方式运行;相比之下,Ollama 和 LM Studio 对本地桌面环境更加友好,尤其适合在个人电脑上快速完成模型体验与应用原型验证;LMDeploy 则兼顾一定的工程化能力和本地部署需求,适合在后续进一步学习高性能部署时深入使用。
因此,在面对不同的模型部署工具时,更合理的做法并不是简单判断哪一种工具“最好”,而是结合具体目标来选择合适的方案。对于强调高吞吐与生产级服务的场景,vLLM、SGLang 等工具往往更具代表性;对于希望深入理解模型加载、推理流程和代码级控制的场景,Transformers 和 LMDeploy 更值得关注;而对于希望快速在本地运行开源大模型,并通过统一接口接入应用程序的场景,Ollama 则是一个非常适合入门和实践的选择。
也正因为如此,本文接下来将从 Ollama 入手,先完成本地大模型运行与服务化调用的基础闭环。通过 Ollama,我们可以较低成本地理解模型下载、模型运行、模型管理、命令行交互、本地 API 调用以及 OpenAI 兼容接口等关键概念。掌握这些内容之后,再进一步学习 LMDeploy、vLLM、SGLang 等更工程化的部署框架时,就能够更清楚地理解它们究竟是在什么基础上继续解决性能、并发、量化和服务稳定性等问题。
1.3 Ollama 简介
在众多模型部署工具中,Ollama 更适合作为本地大模型运行与轻量级服务化调用的入口工具。它的核心价值并不在于追求极致的推理吞吐或复杂的生产级集群能力,而在于将开源大模型的下载、管理、运行和 API 调用流程进行了统一封装,使本地大模型的使用门槛显著降低。
从使用方式来看,Ollama 提供了一套非常简洁的命令行接口。用户可以通过 ollama pull 下载模型,通过 ollama run 直接运行模型并进入交互式对话,通过 ollama list 查看本地已有模型,通过 ollama ps 查看当前正在运行或保留在内存中的模型状态,也可以通过 ollama stop 停止指定模型并释放相关资源。相比手动编写 Transformers 推理代码,这种方式隐藏了大量底层细节,更适合快速完成本地模型体验和原型验证。
更重要的是,Ollama 不只是一个命令行对话工具。它在本地运行后,会默认启动模型服务,并提供本地 API 调用能力。也就是说,模型不仅可以在终端中进行交互,也可以被 Python 程序、Web 应用、RAG 系统、Agent 系统或其他业务程序调用。对于大模型应用开发来说,这一点非常关键,因为它意味着本地模型可以从“手动运行的程序”进一步变成“可被外部系统访问的模型服务”。
Ollama 还支持 OpenAI 兼容接口。通常情况下,本地 Ollama 服务地址为:
http://localhost:11434
其中,Ollama 原生 API 一般使用 /api 路径,而 OpenAI 兼容接口通常使用:
http://localhost:11434/v1/
这意味着在 Python 中可以直接使用 OpenAI SDK 调用本地模型,只需要将 base_url 指向 Ollama 的本地服务地址,并将 model 设置为本地已经下载的模型名称即可。这样一来,原本面向在线模型服务编写的调用代码,也可以较为平滑地迁移到本地模型服务上。
这种接口兼容性具有很强的工程意义。因为在实际应用中,许多大模型开发框架和应用组件都已经围绕 OpenAI 风格接口进行设计,例如 Gradio 对话页面、LangChain 调用链、RAG 问答系统、Agent 工具调用流程等。如果本地模型也能够通过 OpenAI 兼容接口提供服务,那么上层应用在切换模型来源时就不需要大幅修改代码结构。
除了基础模型运行和 API 调用之外,Ollama 还提供了 Modelfile 机制,用于对已有模型进行自定义封装。通过 Modelfile,可以指定基础模型、系统提示词、上下文长度、生成参数、停止词以及聊天模板等内容,从而创建一个带有默认角色设定和运行配置的本地模型。例如,可以基于一个通用模型封装出面向特定应用场景的问答助手,使其在每次启动时自动加载固定的系统提示词和生成参数。
需要注意的是,Modelfile 自定义并不等同于模型微调。它不会更新模型参数,也不会让模型真正学习新的知识或能力;它更像是在已有模型外部增加一层运行配置,用于规范模型的默认行为、输出风格和调用参数。如果希望模型真正学习新的任务模式、领域知识或身份信息,仍然需要通过 SFT、LoRA、QLoRA 等微调方法完成。
在模型格式方面,Ollama 除了可以直接使用其模型库中的模型外,也支持导入部分本地模型文件,尤其是 GGUF 格式模型。GGUF 是 llama.cpp 生态中常见的本地推理模型格式,常用于 Ollama、LM Studio、llama.cpp 等本地推理工具。通过 GGUF 文件与 Modelfile 的配合,可以进一步理解模型文件、聊天模板、停止词和推理参数之间的关系。不过,本地权重导入通常比直接使用 Ollama 模型库中的模型更复杂,需要额外关注模型架构、文件路径、模板配置和运行兼容性。
总体来看,Ollama 的定位可以概括为:面向本地大模型运行的轻量级模型管理与服务化工具。它既可以帮助用户快速体验开源模型,也可以通过本地 API 和 OpenAI 兼容接口,将模型接入到更完整的应用开发流程中。
因此,在学习大模型部署时,Ollama 非常适合作为第一个实践工具。它可以帮助我们先建立对本地模型运行、模型服务、API 调用和应用集成的基本认识。等这些基础概念清楚之后,再进一步学习 LMDeploy、vLLM、SGLang 等高性能部署框架时,就能够更容易理解它们为什么需要关注推理后端、显存管理、量化优化、并发调度和服务稳定性等更深层次的问题。
那事不宜迟,接下来我们就来看看如何来在本地实现 Ollama 本地模型部署吧!
2. Ollama 环境配置
在正式使用 Ollama 运行本地大模型之前,需要先完成软件安装、命令行验证以及基础配置。对于 Windows 用户而言,Ollama 的安装流程相对简单,但在实际使用过程中,仍然可能遇到命令无法识别、后台服务未启动、模型存储路径不合理等问题。因此,本节将从安装、常见报错处理和基础配置三个方面进行说明。
2.1 Ollama 安装
进入官网(https://ollama.com/)并点击右上角的 Download:

在下载页面中选择 Download for Windows:

随后下载 Windows 安装程序 OllamaSetup.exe:

下载完成后,双击安装程序,点击 Install 即可开始安装:
安装完成后,可以看到 Ollama 的启动界面:
为了确认 Ollama 是否安装成功,可以重新打开 PowerShell 或命令行窗口,执行以下命令:

果能够正常输出版本号,就说明 Ollama 已经安装完成,并且命令行可以正确识别 ollama 指令。
2.2 常见报错处理
2.2.1 无法识别 ollama 指令
在安装完成后,如果重新打开终端并执行 ollama list、ollama --version 等命令时出现以下报错:
ollama : 无法将“ollama”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径
正确,然后再试一次。
所在位置 行:1 字符: 1
+ ollama list
+ ~~~~~~
+ CategoryInfo : ObjectNotFound: (ollama:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
通常说明 Windows PowerShell 当前无法找到 ollama.exe 可执行文件。这个问题并不代表 Ollama 安装失败,也不代表模型服务异常,而是当前系统的 PATH 环境变量中没有包含 Ollama 的安装路径。
可以先在 PowerShell 中执行以下命令,检查 Ollama 可执行文件是否存在:
(base) PS C:\Users\76391> Test-Path "$env:LOCALAPPDATA\Programs\Ollama\ollama.exe"
如果返回结果为 True,说明 Ollama 已经安装在本地,只是环境变量尚未配置正确。
接下来可以打开 Windows 的环境变量设置,找到用户变量或系统变量中的 Path:
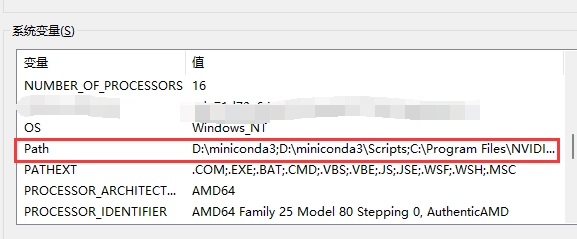
双击进入 Path 后,新建一项内容:
%LOCALAPPDATA%\Programs\Ollama
然保存设置后,关闭当前终端并重新打开 PowerShell,再次执行:

如果能够正常执行,就说明环境变量已经配置成功。
2.2.2 后台服务没有正常启动
如果在运行 Ollama 时出现以下提示:
Error: timed out waiting for server to start
Warning: could not connect to a running Ollama instance
通常说明 Ollama 客户端没有连接到正在运行的本地 Ollama Server。也就是说,ollama.exe 命令本身可以被识别,但后台服务没有正常启动,或者当前服务状态异常。
这类问题可以优先尝试以下处理方式:
关闭当前正在运行的 Ollama; 重新启动 Ollama 应用; 重新打开终端,再次执行相关命令。
重启后,可以通过命令行重新检查模型列表或服务状态:

在 Windows 环境中,Ollama 通常会随系统启动自动运行。如果开机时网络状态不稳定,或者后台服务初始化异常,就可能出现客户端无法连接 Server 的情况。一般情况下,重新启动 Ollama 后即可恢复正常。
2.3 基础配置
在正式下载和运行模型之前,建议先进入 Ollama 的 Settings 页面,对几个关键配置项进行确认。对于本地模型运行来说,比较重要的配置主要包括账号与云端能力、自动更新、网络访问权限、模型存储位置以及上下文长度设置。
这些配置会直接影响 Ollama 的使用方式、模型保存位置、资源占用和网络访问范围。

2.3.1 账号与云端能力
首先是 Ollama account 和 Cloud 相关设置。
Ollama account 表示当前是否登录 Ollama 账号。如果只是运行本地模型,例如使用 ollama run 启动模型,或者通过本地 API 调用模型,一般不需要登录账号。未登录状态下,仍然可以完成大部分本地模型运行、模型管理和本地 API 调用任务。
Cloud 用于启用 Ollama 的云端模型和 Web Search 等在线能力。也就是说,Ollama 除了可以运行本地模型,也可以在启用云端能力后使用部分在线模型或在线功能。
不过,如果当前目标是学习本地大模型运行、管理和调用,那么云端能力并不是必要配置。是否登录账号、是否启用云端能力,可以根据实际使用需求自行决定。
登录账号后,可以使用部分云端模型进行对话。不过需要注意,不同账号类型能够使用的模型范围可能不同,免费版本通常只开放部分模型能力。

2.3.2 更新与网络访问
第二部分是 Auto-download updates 和 Expose Ollama to the network。
Auto-download updates 表示是否自动下载 Ollama 更新。开启后,Ollama 可以自动获取较新的版本,从而获得新的功能、模型支持和问题修复。对于普通使用场景,开启自动更新可以减少手动维护成本;但如果需要保持实验环境或文章示例的一致性,也可以选择关闭自动更新,避免不同版本之间的行为差异。
Expose Ollama to the network 是一个需要重点关注的网络访问选项。默认情况下,Ollama 主要面向本机访问,通常通过以下地址调用本地模型服务:
http://localhost:11434
如果开启 Expose Ollama to the network,局域网内的其他设备或服务就可能访问当前电脑上的 Ollama 服务。这在某些场景中比较有用,例如:
在一台性能较好的主机上运行 Ollama,其他设备通过局域网调用; 多个本地应用需要访问同一个模型服务; 在小型内部环境中进行模型服务共享。
但需要注意,开启网络访问也意味着 Ollama 服务不再只对本机开放。如果当前设备处在公共网络或不可信网络环境中,不建议随意开启该选项,以免带来不必要的安全风险。
2.3.3 本地模型存储
第三部分是 Model location,也就是模型文件的本地保存位置。
在 Ollama 中,通过 ollama pull 或 ollama run 下载的模型都会保存到本地模型目录中。例如图中显示的路径为:
C:\Users\76391\.ollama\models
这表示当前 Ollama 下载的模型会默认存放在该用户目录下的 .ollama\models 文件夹中。对于 Windows 用户来说,这个目录通常位于 C 盘用户目录下。
在实际使用中,不建议长期将大模型文件保存在 C 盘。原因很简单:大模型文件通常体积较大,即使是较小规模的模型,也可能占用数 GB 磁盘空间;如果后续下载 7B、14B 或更大规模的模型,磁盘占用会进一步增加。模型数量越多,C 盘空间压力就越明显,甚至可能影响系统运行和软件安装。
因此,更推荐提前在空间充足的磁盘中新建专门的模型缓存目录,例如:
D:\OllamaCache
然后在 Model location 中点击 Browse,将模型保存位置修改到该目录。这样后续通过 Ollama 下载的模型就会保存到新的路径中,避免继续占用 C 盘空间。
2.3.4 上下文长度设置
最后一部分是 Context length,也就是上下文长度设置。
上下文长度可以理解为模型在一次对话或生成过程中最多能够参考多少 token。上下文越长,模型能够看到的历史对话、输入文本或文档内容就越多;上下文越短,模型能够利用的信息范围就越有限。
在设置页面中,Ollama 提供了多个上下文长度选项,包括:
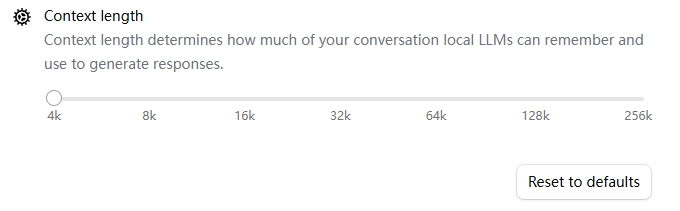
其中,4k、8k、32k 等表示大致的 token 数量。较大的上下文长度更适合长文本处理、长文档问答、多轮对话和代码文件分析等任务。
但是,上下文长度并不是越大越好。更大的上下文长度通常意味着更高的内存或显存占用,同时也可能降低推理速度。如果本地设备配置有限,盲目设置过大的上下文长度,可能导致模型响应变慢,甚至出现内存不足、显存不足或模型无法正常运行等问题。
因此,在本地实验或普通应用场景中,可以优先使用默认值,或者选择较保守的上下文长度,例如 4k 或 8k。当确实需要处理长文本、长对话或大文档时,再根据硬件资源逐步调高上下文长度,会更加稳妥。
3. Ollama 基本操作
完成 Ollama 的安装与基础配置后,就可以开始进行模型查阅、模型下载、本地运行、API 调用以及资源释放等操作。Ollama 的核心优势在于,它将本地模型管理和模型服务调用进行了统一封装,使用户可以通过较少的命令完成从模型获取到本地推理的完整流程。
3.1 模型查阅
在使用 Ollama 之前,首先需要确定要运行的模型。Ollama 官方提供了模型检索页面,可以查看当前支持下载和运行的模型:
https://ollama.com/search
例如,可以在模型库中搜索 Qwen 系列模型:

Ollama 模型库通常会为模型标注不同能力标签,例如:
vision:表示模型具备视觉理解能力;thinking:表示模型支持思考或推理模式;tools:表示模型支持工具调用能力;embedding:表示模型可用于文本向量化任务。
这些标签可以帮助用户根据实际需求选择合适的模型。例如,如果目标是构建图文理解应用,可以优先选择带有 vision 标签的模型;如果目标是构建 RAG 系统,则可以关注 embedding 类型模型;如果需要进行 Agent 工具调用实验,则可以选择支持 tools 的模型。
在本文示例中,为了兼顾本地运行门槛和模型能力展示,选择体量较小的 qwen3.5:0.8b 模型作为演示对象。该模型规模较小,更适合在本地设备上快速下载和运行。

3.2 模型下载与运行
确定模型名称后,可以通过命令行或 Python 程序调用 Ollama 模型。Ollama 的模型名称需要与官方模型库或本地模型列表中的名称保持一致,例如:
qwen3.5:0.8b
3.2.1 命令行下载与运行
最直接的方式是使用 ollama run 命令。该命令既可以运行本地已有模型,也可以在模型尚未下载时自动完成拉取:
ollama run qwen3.5:0.8b
如果本地尚未存在该模型,Ollama 会先从模型库中下载对应文件,并保存到前面配置的模型存储目录中。

模型下载完成后,终端会进入交互式对话模式,此时可以直接输入问题并查看模型回复:

如果需要退出当前对话,可以使用快捷键:
Ctrl + D
如果只希望下载模型,而不立即进入对话模式,可以使用 ollama pull 命令:
ollama pull qwen3.5:0.8b
该命令只负责拉取模型文件,不会自动进入交互式对话。

如果模型此前已经下载完成,再次执行 ollama pull 时,Ollama 通常会检查本地文件状态,并避免重复下载相同内容。
3.2.2 Python 中调用 Ollama
除了命令行方式,Ollama 也提供了 Python 客户端,便于在程序中调用本地模型。首先需要安装对应的 Python 包:
pip install ollama
安装完成后,可以通过如下代码调用模型:
from ollama import chat
response = chat(
model='qwen3.5:0.8b',
messages=[{'role': 'user', 'content': '你好,你是谁?'}],
)
print(response.message.content)
如果模型已经下载到本地,程序会直接向本地 Ollama 服务发送请求,并返回模型生成结果。例如,可能得到类似下面的回复:
你好!我是 Qwen3.5,一个超大规模语言模型。我基于阿里巴巴集团自研的超大规模语言模型技术,能够处理文本、图像、代码、视频等多种格式,提供多种语言支持,并具备强大的推理、生成和数据分析能力。我擅长处理复杂的自然语言对话、代码解析、多任务学习、图像识别、文档分析、多模态理解等任务,并支持 AI 模型训练、图像生成、多模态推理等多种功能。
你的任何问题都可以向我提出,我会尽力提供帮助!|
需要注意的是,Python 客户端本质上仍然是在调用本地 Ollama 服务。因此,在运行 Python 代码之前,需要确保 Ollama 后台服务已经正常启动,并且指定的模型名称与本地模型名称一致。
3.3 模型查看
在下载和运行多个模型之后,可以通过命令行查看本地已经存在的模型列表。
ollama list
执行后,Ollama 会列出当前本地已经下载的模型,包括模型名称、模型 ID、模型大小以及更新时间等信息。

如果需要查看当前正在运行或仍然保留在内存、显存中的模型,可以使用:
ollama ps
例如,先启动模型:
ollama run qwen3.5:0.8b
然后重新打开一个终端窗口,执行:
ollama ps
此时可以看到当前模型的运行状态:

从示例结果可以看到,qwen3.5:0.8b 当前仍然保留在 GPU 上,占用约 2.3GB 资源,并使用 4096 的上下文长度。具体字段含义如下:
NAME | |
SIZE | |
PROCESSOR | |
CONTEXT | |
UNTIL |
ollama ps 对于观察本地资源占用非常有用。尤其是在显存有限的环境中,可以通过该命令判断模型是否仍然占用 GPU 资源,从而决定是否需要手动停止模型。
3.4 本地模型服务调用
Ollama 在本地运行后,会默认提供 API 服务。默认服务地址为:
http://localhost:11434
这意味着,Ollama 不仅可以通过命令行交互,也可以作为一个本地模型服务被外部程序调用。
3.4.1 OpenAI 兼容接口调用
除了 Ollama 原生 API 之外,Ollama 还提供 OpenAI 兼容接口。OpenAI 兼容接口地址通常为:
http://localhost:11434/v1/
需要注意的是:
http://localhost:11434/api
通常对应 Ollama 原生接口,而:
http://localhost:11434/v1/
对应 OpenAI 兼容接口。
借助 OpenAI 兼容接口,可以直接使用 openai Python 库调用本地 Ollama 模型。这种方式的优势在于:调用代码与在线大模型服务的调用方式高度一致,后续切换到其他兼容 OpenAI 接口的本地服务框架时,代码改动也相对较小。
示例代码如下:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1/",
api_key="ollama"
)
response = client.chat.completions.create(
model="qwen3.5:0.8b",
messages=[
{
"role": "system",
"content": "你是一个人工智能课程助教,回答应准确、简洁。"
},
{
"role": "user",
"content": "请用三句话解释什么是大语言模型。"
}
],
temperature=0,
max_tokens=512,
reasoning_effort="none"
)
print(response.choices[0].message.content)
这里的几个参数需要重点理解:
base_url指向 Ollama 本地 OpenAI 兼容接口;api_key是 OpenAI SDK 所需参数,本地 Ollama 通常不会校验,可以填写ollama;model需要填写本地模型名称,并且应与ollama list中显示的名称一致;messages用于传入对话消息,其中system表示系统设定,user表示用户输入;temperature用于控制生成结果的随机性,设置为0时输出更加稳定;max_tokens用于限制本次回答最多生成的 token 数;reasoning_effort用于控制是否启用模型的思考模式,这里设置为"none",表示关闭思考过程,只返回最终回答。
运行后,可以看到模型返回类似结果:
大语言模型(LLM)是一种基于深度学习的智能系统,能够处理人类语言并理解其含义。
它通过训练海量文本数据,学习语言的结构与规律,从而具备强大的推理、生成和问答能力。
当前的大语言模型能够理解复杂语境,并自主创作、翻译和撰写各种类型的文本内容。
到这里,就完成了 Ollama 的本地模型服务化调用。与直接在终端中使用 ollama run 对话不同,OpenAI SDK 调用方式可以让本地模型接入 Python 程序、Web 应用、RAG 系统、Agent 系统或其他业务程序。
3.4.2 流式输出调用
除了普通的一次性返回结果,Ollama 也可以通过 OpenAI 兼容接口实现流式输出。流式输出会在模型生成过程中逐步返回内容,而不是等待完整答案生成后一次性返回。
这种方式更适合聊天机器人、Web 应用、交互式问答页面等场景,因为用户可以更早看到模型输出,整体交互体验更接近在线大模型产品。
示例代码如下:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1/",
api_key="ollama"
)
stream = client.chat.completions.create(
model="qwen3.5:0.8b",
messages=[
{
"role": "user",
"content": "请简要介绍 Ollama 的作用。"
}
],
temperature=0,
max_tokens=512,
reasoning_effort="none",
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
在这段代码中,关键参数是:
stream=True
设置该参数后,接口会返回一个可迭代的流式响应对象。每次迭代都会获取一小段模型生成内容,因此可以通过循环逐步打印输出。
如果程序运行时报错,可以优先检查以下几项:
Ollama 是否正在运行; 模型是否已经下载到本地; model名称是否与ollama list中显示的一致;base_url是否写成了http://localhost:11434/v1/;是否误将 OpenAI SDK 的地址写成了 Ollama 原生接口 http://localhost:11434/api;本地端口 11434是否被其他程序占用或拦截。
3.4.3 模型测评
完成本地调用之后,还可以进一步结合评测框架,对 Ollama 中运行的模型进行简单测评。这里以 EvalScope 为例,演示如何通过 OpenAI 兼容接口评估本地模型。
示例代码如下:
from evalscope.run import run_task
from evalscope.config import TaskConfig
task_cfg = TaskConfig(
model="qwen3.5:0.8b",
api_url="http://localhost:11434/v1/",
api_key="ollama",
eval_type="openai_api",
datasets=["gsm8k"],
limit=10,
generation_config={
"do_sample": False,
"temperature": 0.0,
"max_tokens": 512,
"extra_body": {
"enable_thinking": False
}
},
dataset_args={
"gsm8k": {
"few_shot_num": 2,
"prompt_template": "{question}\nGive only the final numeric answer.",
"few_shot_prompt_template": (
"Here are some examples of similar problems:\n\n"
"{fewshot}\n\n"
"{question}\n"
"Give only the final numeric answer."
),
"system_prompt": "You are a helpful assistant. /no_think"
}
}
)
result = run_task(task_cfg=task_cfg)
print(result)
这段代码中,eval_type="openai_api" 表示 EvalScope 会按照 OpenAI 兼容接口的方式访问本地模型;api_url 指向 Ollama 的本地服务地址;datasets=["gsm8k"] 表示使用 GSM8K 数学推理数据集进行测试;limit=10 表示只抽取少量样本进行快速验证。
需要注意的是,qwen3.5:0.8b 属于小规模模型,参数量较小,复杂数学推理能力通常比较有限。因此,在 GSM8K 这类数学推理任务上,测试结果可能并不理想。

这种现象并不意味着 Ollama 调用失败,而是说明当前模型规模和任务难度之间存在差距。对于本地轻量模型而言,更适合优先验证基础问答、文本生成、简单指令遵循和应用集成流程;如果要获得更好的数学推理或复杂任务表现,则需要选择更大规模或能力更强的模型。
3.4.4 对话页面构建
除了在终端或 Python 脚本中调用 Ollama,也可以通过 Gradio 快速构建一个本地对话页面。由于 Ollama 提供 OpenAI 兼容接口,因此可以直接借助 Gradio 的相关能力接入本地模型服务。
首先安装 Gradio:
pip install gradio
然后使用 gr.load_chat 快速创建一个聊天界面:
import gradio as gr
demo = gr.load_chat(
"http://127.0.0.1:11434/v1",
model="qwen3.5:0.8b",
token="ollama"
)
demo.launch()
启动后,浏览器中会打开一个本地对话页面:

这种方式适合快速验证本地模型的交互效果。与手动编写完整前端页面相比,Gradio 可以用较少代码构建可视化界面,方便进行模型体验、原型展示和功能验证。
3.5 停止模型
在使用 Ollama 运行模型后,即使当前终端对话已经结束,模型也可能会在一段时间内继续保留在内存或显存中。这样做的好处是,后续再次调用时可以减少模型重新加载的时间;但如果本地显存或内存资源有限,模型持续占用资源也可能影响其他程序运行。
可以通过以下命令查看当前仍在运行或保留中的模型:
ollama ps
如果确认暂时不再使用某个模型,可以通过 ollama stop 手动停止它。例如,停止 qwen3.5:0.8b:
ollama stop qwen3.5:0.8b
停止完成后,再次执行:
ollama ps
如果列表中不再显示该模型,就说明模型已经停止运行,相关资源也已经释放。

3.6 Ollama 自定义模型
除了直接运行 Ollama 模型库中的现成模型外,Ollama 还支持通过 Modelfile 创建自定义模型。这里的“自定义模型”并不是重新训练模型,也不是对模型参数进行微调,而是在已有模型的基础上封装默认系统提示词、生成参数、上下文长度、停止词和聊天模板等配置,使模型在启动时自动具备特定的角色定位和运行行为。
从实际使用角度看,Modelfile 更像是 Ollama 的模型运行配置文件。它可以帮助我们把一个通用模型包装成更适合特定场景的本地模型,例如技术问答助手、代码解释助手、知识库问答助手或领域任务助手。这样在后续调用模型时,就不需要每次都重复传入相同的系统提示词和参数配置。
3.6.1 自定义参数与提示词
首先来看最常见的一类自定义方式:基于 Ollama 模型库中已经下载好的模型,创建一个带有默认角色设定和运行参数的新模型。
例如,可以基于 qwen3.5:0.8b 创建一个“人工智能技术助手”模型,使其默认以专业、简洁的方式回答大模型相关问题。
首先在 PowerShell 中创建一个目录,用于存放本次自定义模型的配置文件:
mkdir D:\OllamaModels\course-assistant
cd D:\OllamaModels\course-assistant
需要注意的是,这个目录中保存的是我们自己编写的 Modelfile 配置文件,并不是模型权重文件。真正的模型文件仍然由 Ollama 根据前面设置的模型存储目录统一管理。
接下来创建一个临时的 Modelfile.txt 文件:
notepad Modelfile.txt

按下“是”后,在文件中写入以下内容:
FROM qwen3.5:0.8b
PARAMETER temperature 0
PARAMETER num_ctx 4096
SYSTEM """
你是一个人工智能课程助教,主要帮助学生学习大模型基础、提示词工程、RAG、Agent 和模型部署。
回答问题时应准确、简洁,并尽量结合课堂知识进行解释。
"""
接下来保存并关闭文件。这里的 FROM qwen3.5:0.8b 表示当前自定义模型基于已经下载好的 qwen3.5:0.8b 创建;PARAMETER 用于设置模型运行参数;SYSTEM 用于设置默认系统提示词。也就是说,后续运行这个模型时,它会默认以“人工智能课程助教”的身份进行回答。
除了设置系统提示词以外,Modelfile 中也可以设置对应的参数信息,例如:
PARAMETER temperature 0
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.1
PARAMETER num_ctx 4096
PARAMETER num_predict 512
这些参数的含义如下:
temperature | |
top_p | |
repeat_penalty | |
num_ctx | |
num_predict |
例如,如果希望课程助手回答更加稳定、简洁,可以将 Modelfile 改成下面这样:
FROM qwen3.5:0.8b
PARAMETER temperature 0
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.1
PARAMETER num_ctx 4096
PARAMETER num_predict 512
SYSTEM """
你是一个人工智能课程助教,主要帮助学生学习大模型基础、提示词工程、RAG、Agent 和模型部署。
回答问题时应准确、简洁,并尽量结合课堂知识进行解释。
"""
文件保存完成后,需要将文件名中的 .txt 后缀去掉。因为 Ollama 默认识别的配置文件名是 **Modelfile**,而不是 Modelfile.txt。
在 PowerShell 中执行:
Rename-Item .\Modelfile.txt Modelfile
然后使用 ollama create 创建自定义模型:
ollama create course-assistant -f Modelfile
其中:
ollama create | |
tech-assistant | |
-f Modelfile | Modelfile 作为配置文件 |
创建完成后,可以通过以下命令查看本地模型列表:
ollama list
此时可以看到,除了原来的 qwen3.5:0.8b,本地模型列表中还会新增一个 tech-assistant 模型。

接下来就可以运行这个自定义模型:
ollama run tech-assistant
由于已经在 Modelfile 中设置了 SYSTEM,因此运行 tech-assistant 时,系统提示词会默认生效。也就是说,这个模型不再只是一个普通的基础模型,而是已经被封装成了一个具有固定角色设定和默认生成参数的本地助手。
对于部分支持 thinking / reasoning 模式的模型,终端中有时会输出较长的思考过程。如果只希望看到最终回答,可以在运行时关闭思考模式,例如:
ollama run course-assistant --think=false "你是谁?"
此时模型会直接返回最终回答,例如:

通过这个例子可以看到,tech-assistant 已经不再只是原始的 qwen3.5:0.8b 模型,而是一个带有默认系统提示词和运行参数的自定义本地模型。
这里需要特别强调:Modelfile 自定义模型不是微调。
Modelfile 只是对已有模型的运行方式进行封装,包括默认提示词、生成参数、上下文长度、停止词和模板等内容。它不会更新模型参数,也不会让模型真正学习新的知识、身份信息或任务能力。如果希望模型在参数层面学习新的数据,仍然需要通过 SFT、LoRA、QLoRA 等微调方法完成。因此,Modelfile 更适合用于轻量级角色封装和运行参数管理,而不是用于替代真正的模型微调。
3.6.2 自定义权重文件
除了基于 Ollama 模型库中的现有模型进行自定义外,Ollama 也支持导入部分本地模型权重。也就是说,如果本地已经准备好了某个模型文件,也可以尝试通过 Modelfile 将其注册到 Ollama 中,然后像普通 Ollama 模型一样运行和调用。
不过,本地权重导入比基于现有 Ollama 模型进行自定义更复杂。它不仅涉及模型文件路径,还涉及模型格式、模型架构、聊天模板、停止词、Tokenizer 兼容性以及推理参数等问题。
3.6.2.1 Safetensors 与 GGUF
对于 HuggingFace / Safetensors 格式的模型,Ollama 对模型架构有一定限制,并不是所有 HuggingFace 模型目录都能被直接识别和加载。
在实际使用中,如果模型架构不在支持范围内,直接导入时可能会出现“不支持该模型架构”之类的错误。例如,直接导入某些 Qwen 系列的 Safetensors 模型目录时,就可能因为架构兼容性问题而无法成功创建 Ollama 模型。对于 HuggingFace / Safetensors 格式的模型,Ollama 目前主要支持以下几类架构的直接导入:
Llama,包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2; Mistral,包括 Mistral 1、Mistral 2 和 Mixtral; Gemma,包括 Gemma 1 和 Gemma 2; Phi3。
除了直接导入 Safetensors 模型目录之外,另一种更常见的方式是使用 GGUF 格式模型。

GGUF 是 llama.cpp 生态中常见的本地推理模型格式,广泛用于 Ollama、llama.cpp、LM Studio 等本地推理工具。与 HuggingFace / Safetensors 格式相比,GGUF 更偏向推理部署场景,通常更适合在轻量化本地推理框架中运行。

需要注意的是,GGUF 更适合作为推理部署格式,而不是训练格式。一般情况下,模型训练、监督微调或 LoRA 微调仍然主要基于 HuggingFace / Safetensors 格式完成;当模型需要在 Ollama、llama.cpp、LM Studio 等工具中运行时,再根据需要转换或下载对应的 GGUF 版本。
对于 Qwen 系列模型,如果自行使用 llama.cpp 将 Transformers 格式模型转换为 GGUF,可能会受到 Tokenizer、Chat Template、thinking 模式、RoPE 参数和运行时兼容性等因素影响。比如我尝试过将之前微调的模型进行转换后,再在 Ollama 中运行会出现无限循环的情况。
因此对于一般使用场景,如果官方或社区已经提供了对应的 GGUF 模型,优先下载现成版本会更加稳妥。例如,可以通过 ModelScope 下载 Qwen3-0.6B 的 GGUF 模型:

modelscope download --model Qwen/Qwen3-0.6B-GGUF --local_dir D:\微调与部署\qwen-gguf
下载完成后,可以在目录中看到对应的 GGUF 文件:
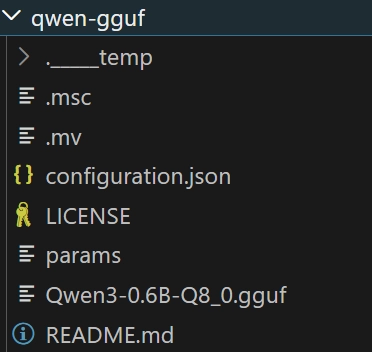
假设我们要使用的文件名为:
Qwen3-0.6B-Q8_0.gguf
接下来就可以基于这个 GGUF 文件创建 Ollama 模型。
3.6.2.2 基于 GGUF 文件编写 Modelfile
首先进入 GGUF 文件所在目录:
cd "D:\微调与部署\qwen-gguf"
然后创建或打开 Modelfile ,并在文件中写入以下内容:
FROM ./Qwen3-0.6B-Q8_0.gguf
PARAMETER temperature 0.6
PARAMETER top_k 20
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.2
PARAMETER num_ctx 4096
PARAMETER num_predict 512
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
{{ .Response }}"""
SYSTEM """
你是一个本地运行的人工智能助手。
回答问题时应准确、自然、简洁。
不要重复用户问题,不要反复输出相同内容。
"""
这里需要重点关注三个部分。
第一是:
FROM ./Qwen3-0.6B-Q8_0.gguf
它表示当前模型基于本地的 GGUF 文件创建。FROM 后面需要填写实际的 GGUF 文件名,如果文件名不同,需要改成自己目录中的真实文件名。
第二是前面提到的生成参数:
PARAMETER temperature 0.6
PARAMETER top_k 20
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.2
PARAMETER num_ctx 4096
PARAMETER num_predict 512
第三是在原理时提到过的提示词模板和停止词:
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
{{ .Response }}"""
对于 Qwen 这类 ChatML 风格的模型,需要通过模板明确区分 system、user 和 assistant 的位置。如果模板设置不合适,模型可能会把用户输入当成普通文本续写,从而出现重复输出或回答异常。因此,导入 GGUF 文件时,除了指定模型文件本身,也要注意设置合适的 TEMPLATE 和 stop 标记。
3.6.2.3 创建并运行本地 GGUF 模型
保存 Modelfile 后,执行以下命令创建模型:
ollama create qwen3-0.6b-q8 -f Modelfile
此时模型会被注册到 Ollama 中:
接下来可以进行测试。如果希望关闭思考模式,可以在输入中加入 /no_think:
ollama run qwen3-0.6b-q8 "你是谁?/no_think"
此时返回的结果类似如下:

如果不加入 /no_think,模型会启用 thinking / reasoning 模式,先输出思考过程,再给出最终回答:
ollama run qwen3-0.6b-q8 "你是谁?"
此时的回复类似如下:

通过这个例子可以看到,Ollama 不仅可以基于模型库中的模型进行自定义,也可以通过本地 GGUF 文件创建新的模型。整体流程可以概括为:
下载或准备 GGUF 文件
↓
编写 Modelfile
↓
设置 FROM、PARAMETER、TEMPLATE、SYSTEM
↓
ollama create 创建模型
↓
ollama run 运行测试
需要注意的是,导入本地权重文件和前面基于官方模型库进行自定义有所不同。前者需要考虑模型格式、文件路径、聊天模板、停止词和生成参数;后者只需要通过 FROM qwen3.5:0.8b 引用已有模型即可。因此,自定义权重文件更适合作为进阶用法,用于理解 Ollama 如何加载和管理本地模型文件。
4. 总结
到这里,我们就把 Ollama 的基本使用流程完整走了一遍。从前面的内容可以看到,Ollama 最适合解决的并不是复杂的生产级部署问题,而是帮助我们先把开源大模型在本地真正跑起来。它把模型下载、模型管理、命令行运行和 API 调用都封装得比较简单,所以很适合作为本地大模型实践的第一站。
在环境配置部分,我们完成了 Ollama 的安装,处理了命令无法识别、后台服务未启动等常见问题,也了解了模型存储路径、网络访问和上下文长度这些基础设置。虽然这些内容看起来比较零散,但在实际使用时非常关键。尤其是模型保存位置和上下文长度,一个影响磁盘空间,一个影响资源占用和运行速度。
在基本操作部分,我们通过 ollama pull、ollama run、ollama list、ollama ps 和 ollama stop 等命令,完成了模型下载、运行、查看和停止的完整流程。掌握这些命令之后,就已经可以比较熟练地管理本地模型了。
更重要的是,我们还通过 OpenAI 兼容接口,把 Ollama 从一个“终端里的聊天工具”变成了一个“可以被程序调用的本地模型服务”。这样一来,本地模型就可以进一步接入 Python 程序、Gradio 页面、EvalScope 测评流程,甚至后续的 RAG 和 Agent 应用中。
最后,我们还介绍了 Ollama 的 Modelfile 机制。它可以为已有模型封装默认提示词和运行参数,也可以配合 GGUF 文件导入本地模型。不过这里需要记住一点:Modelfile 自定义不是微调。它只是让模型以某种固定配置运行,并不会真正改变模型参数。
所以,总体来说,Ollama 的价值可以概括为一句话:它让开源大模型从“下载到本地”到“被程序调用”这一步变得足够简单。
掌握 Ollama 之后,我们对模型服务化已经有了一个比较直观的认识:模型不只是一个权重文件,也不只是一次命令行对话,它还可以变成一个能够被应用程序持续访问的本地服务。
下一节内容,我们会继续往工程化方向推进,介绍 LMDeploy。如果说 Ollama 解决的是“如何更方便地把模型跑起来”,那么 LMDeploy 更关注的是“如何更高效、更可控地把模型部署起来”。届时会进一步涉及推理后端、显存占用、量化优化和 OpenAI 兼容服务等内容
-- 完 --
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有与、、、、等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群