点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
过去半年,世界动作模型(WAM)几乎成了具身智能最值得追踪的技术路线。从 DreamZero、Motus 到 Cosmos Policy、Fast-WAM,这条路线已经回答了一个关键问题:视频世界模型能不能变成机器人策略?答案是能,而且泛化能力经常超过传统 VLA。但这一周的新工作,开始追问三个更致命的问题——世界模型能不能不只预测未来,而是评估动作后果?VLA 的语言推理和 WAM 的物理预测能不能合体?不同机器人的动作空间千奇百怪,世界模型能不能用一个统一接口来评估它们? τ0-WM、WLA、OSCAR 三篇,正好对应这三个追问。它们的共同信号只有一个:WAM 正在从“动作生成器”,走向“机器人决策系统”。
一、τ0-WM:机器人不只要出动作,还要在执行前评估后果
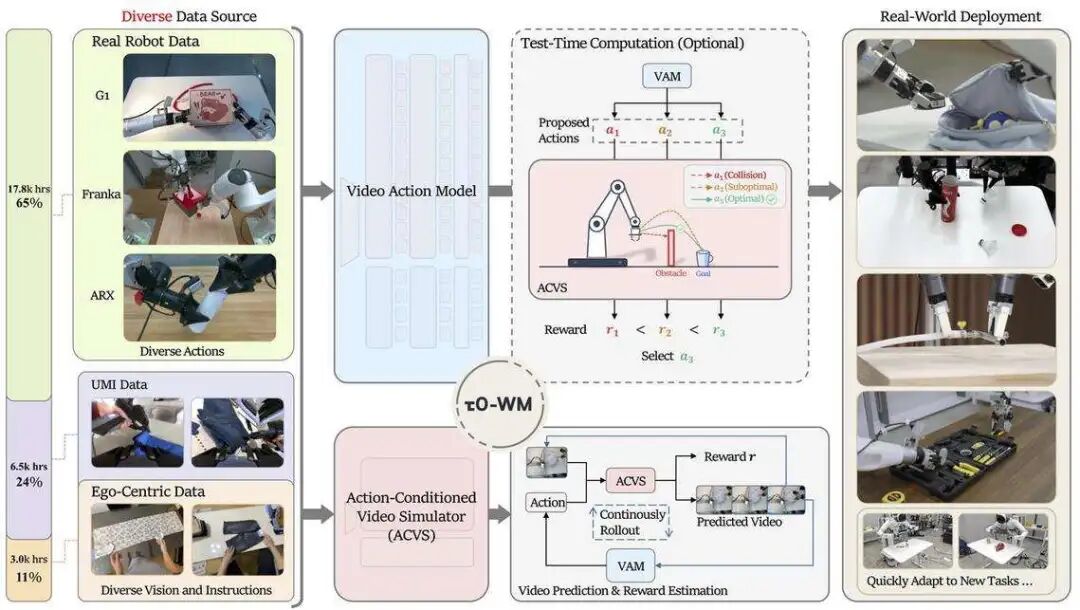
这周最值得放在第一位的是 τ0-WM。它的定位一句话就能说清楚:一个统一的视频-动作世界模型,同时能做三件事——action generation、video prediction、action-conditioned future evaluation。
这三个词放在一起,代表的是一次 WAM 能力边界的重大扩展。
传统 VLA 更像一个直接策略:输入当前图像和语言指令,输出动作。它的核心问题是:模型很少显式回答“这个动作执行后,世界会变成什么样”。 如果动作错了,只有真机执行后才知道。在仿真里,试错成本可能是几分钱;在真实机器人上,试错成本可能是几小时甚至几天,还要搭上设备损耗的风险。
τ0-WM 的思路完全不同。它的流程是:先提案候选动作,再用世界模型预测这些动作可能导致的未来,然后对每一个未来结果进行评估。如果评估结果差,模型可以修正动作,形成 proposal–evaluation–revision 的闭环。
这就是从“生成动作”到“动作前决策”的质变。
真实机器人任务里,很多失败并不是因为动作不会生成,而是因为动作缺少后果评估。比如机器人要把一个易碎物体放进盒子,直接生成一个抓放动作也许能完成,但如果没有评估,它可能不知道这个角度会不会碰到边缘、物体会不会滑落、后续是否还能继续任务。τ0-WM 让机器人在执行前,先用世界模型“想一想这个动作到底靠不靠谱”。
这也是 WAM 相比纯 VLA 最值得期待的地方。VLA 擅长理解任务语义,但面对复杂物理后果时,往往缺少显式建模。WAM 则可以把“动作导致未来变化”这件事内化成模型能力的一部分。τ0-WM 把这种能力显式化成了一个可评估、可修正的流程。
更值得关注的是它的工程底座。τ0-WM 来自智元 Finch 团队,项目页显示这是一个 5B 参数的开源统一视频-动作世界模型,训练数据覆盖大量真实机器人遥操作、UMI-style 演示和第一视角交互视频。这说明 WAM 正在进入大规模真实数据训练阶段,而不是只停留在小规模仿真或单机器人平台上。
用一句话概括 τ0-WM 的价值:它的重点不是让机器人更会“动”,而是让机器人在动之前更会“判断”。
二、WLA:把 VLA 的语言推理和 WAM 的物理预测接起来
如果 τ0-WM 更偏 WAM 主线,那 WLA 这篇的意义在于:它尝试把 VLA 和 WAM 两条曾经经常被对立讨论的路线,焊进同一个模型里。
过去 VLA 和 WAM 各有各的强项,也各有各的盲区。
VLA 的优势在语言理解和任务分解。用户说一句“先把桌上的东西收拾干净,再把杯子放到水槽旁边”,VLA 能比较自然地解析出任务层级和子目标。但它的短板也很明显:底座多来自图文预训练,对物理动态和未来状态变化缺乏显式建模。它知道“杯子是什么”,但不一定知道“杯子被推一下会怎么动”。
WAM 正好相反。它擅长建模世界动态,知道动作会导致怎样的未来变化,但在语言推理、复杂指令解析、长程任务分解上,未必有 VLA 那么自然流畅。
WLA 的目标就是把这两者接起来。 它把文本指令、图像和机器人状态作为输入,同时预测三类东西:文本子任务、subgoal image 和机器人动作。也就是说,模型不是只输出动作,而是同时学会“语言层面的任务意图”和“物理层面的未来变化”。

这个设计非常巧妙。文本子任务负责高层语义——当前应该先拿杯子还是先开抽屉;subgoal image 负责物理目标——下一步世界应该变成什么样;动作则负责把机器人真正驱动过去。WLA 不再是纯 VLA,也不是纯 WAM,而更像一个 World-Language-Action 的统一模型。
技术选型上也很值得注意。WLA 使用自回归 Transformer,而不是很多 WAM 使用的双向 diffusion Transformer。它希望通过 next state 预测,把语义意图和细粒度物理动态都放进同一个下一状态建模里。
论文中还埋了一个很工程化的设计:世界预测可以在训练时帮助动作生成,但推理时可以关闭以提速;如果需要更强控制,也可以打开世界预测做 test-time scaling。这意味着模型可以根据任务复杂度动态切换推理深度——平时快跑,关键步骤多想几步。
这可能是未来 VLA + WAM 融合的一个重要方向。真正的机器人基础模型,既不能只有语言,也不能只有世界模型。只有语言会缺物理,只有世界预测会缺任务理解。WLA 的价值就在于,它把“下一步该做什么”和“做了以后世界应该怎么变”放进了同一个模型里。
三、OSCAR:跨本体世界模型,关键在于动作接口统一
第三篇 OSCAR 解决的是一个更现实、也更头疼的问题:不同机器人本体的动作空间完全不一样,世界模型怎么才能跨本体泛化?
一个 Franka 机械臂是 7 维末端动作,一个 ALOHA 双臂是多个关节角的组合,一个人形机器人可能是全身几十个自由度,人手视频更是连动作标签都没有。传统 action-conditioned video world model 会直接把动作 token 作为条件输入,但动作 token 往往和具体本体深度绑定。一个机器人上学到的控制表征,换到另一个机器人上可能完全不成立。
这就导致一个很尴尬的局面:世界模型很难吃下大规模跨本体数据。而吃不下跨本体数据,就很难成为真正的机器人基础模型。

OSCAR 的思路非常巧妙:不要直接用原始动作,而是把动作渲染成 2D 运动学骨架。
这个设计看起来简单,但实用性极强。不同机器人虽然控制空间千差万别,但在图像中表现出来的“身体结构怎么动”,可以用一种更统一的视觉形式来表达。机械臂可以渲染成骨架,人手也可以渲染成骨架,动作条件就从“机器人专属控制向量”变成了“视觉上可理解的运动结构”。
这其实和最近几周很多工作的趋势是一致的:动作不一定非要以低维数字形式进入世界模型,它可以变成点轨迹、mask、视觉动作场、骨架渲染。因为视频世界模型本身更擅长处理视觉空间里的运动,而不是直接理解不同机器人本体的控制坐标。
OSCAR 的另一个重点是策略评估。它不是只生成好看的机器人视频,而是希望用生成世界去评估 robot policy。项目强调,它训练了 action-conditioned video world model,并进一步用于 RoboArena policy evaluation。论文也指出,OSCAR 的虚拟策略评估结果和真实世界评估之间存在显著相关性。
这件事的价值怎么强调都不过分。 真实机器人评估成本太高——每个策略都上真机跑大量任务,慢、贵,还容易损坏设备。如果世界模型能成为一个足够可信的“虚拟评估器”,机器人算法的迭代速度会大幅提升。先在生成世界里筛选策略,再把少数高潜力策略放到真机上验证——这才是可规模化的研发流程。
当然,这里最大的挑战是评估器本身的可靠性。如果世界模型会幻觉,或者对错误动作过于乐观,评估就会失真。但 OSCAR 的方向无疑是对的。
一句话总结 OSCAR:用 2D kinematic skeleton rendering 做跨本体动作接口,把 world model 从视频生成推向策略评估。
四、这一周的共同趋势:WAM 正在从模型变成系统
把 τ0-WM、WLA、OSCAR 放在一起看,会发现它们其实在回答三个不同但高度相关的问题:
τ0-WM 问的是: 机器人能不能在执行前评估动作后果? WLA 问的是: 语言推理和世界建模能不能合成一个模型? OSCAR 问的是: 不同机器人本体能不能共享一个 action-conditioned world model,并用于策略评估?
这三个问题背后,是同一个更大的趋势:WAM 正在从“单个模型能力”走向“机器人系统能力”。
早期 WAM 更强调生成能力——模型能不能预测未来视频?能不能从未来视频反推动作?能不能比 VLA 泛化更好?这些问题当然重要,但它们本质上还是在比“模型强不强”。
现在大家开始追问系统问题。 动作生成前有没有评估环节?长程任务有没有语言分解?跨本体动作有没有统一接口?世界模型能不能成为策略测试场?推理时能不能在速度和深度之间动态切换?
这意味着,世界模型正在变成机器人决策系统中的一个核心组件,而不是一个独立的生成模块。未来真正可用的机器人世界模型,可能会同时承担多种角色:
它是策略模型,直接生成动作 它是预测模型,想象未来状态 它是评估模型,判断候选动作是否可靠 它是语言模型,理解复杂任务和子目标 它是仿真器,帮助筛选和比较不同策略
τ0-WM 让世界模型参与动作评估和修正。WLA 把语言推理、世界预测和动作合成放到一起。OSCAR 尝试用统一动作表示,让世界模型跨本体评估策略。这三篇,共同指向了这个“世界模型即系统”的未来。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀