
Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,但  的计算开销不得不做出各种妥协:例如将 self-attention 改为 cross-attention 或 local-attention、序列截断、序列压缩等。这些取舍虽缓解了计算压力,但不可避免地损失了序列中的长程行为模式。受 LLM 领域线性注意力(Linear Attention)及混合架构研究的启发,线性注意力天然具备
的计算开销不得不做出各种妥协:例如将 self-attention 改为 cross-attention 或 local-attention、序列截断、序列压缩等。这些取舍虽缓解了计算压力,但不可避免地损失了序列中的长程行为模式。受 LLM 领域线性注意力(Linear Attention)及混合架构研究的启发,线性注意力天然具备 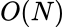 复杂度,能在不做序列截断的情况下处理任意长度的行为序列,可能是推荐领域比 Transformer 更匹配的底层架构。然而,现有线性注意力模型每步只能做 rank-1 的浅层写入,建模质量与 Transformer 仍有差距;而具有多步深度写入能力的 TTT(Test-Time Training)虽质量突破,却因串行依赖导致训练吞吐量比线性注意力慢,难以工业部署。
复杂度,能在不做序列截断的情况下处理任意长度的行为序列,可能是推荐领域比 Transformer 更匹配的底层架构。然而,现有线性注意力模型每步只能做 rank-1 的浅层写入,建模质量与 Transformer 仍有差距;而具有多步深度写入能力的 TTT(Test-Time Training)虽质量突破,却因串行依赖导致训练吞吐量比线性注意力慢,难以工业部署。
为此,腾讯广告技术团队与北京大学合作提出 PRISM(Parallel Residual Iterative Sequence Model)—— 在保持线性注意力  复杂度的同时,实现 TTT 级别多步深度写入的序列模型。PRISM 通过分析 TTT-MLP 的梯度结构,揭示其高表达力源于 步长 × 残差 × 方向 的多步迭代模式,并发现这一高表达力与串行瓶颈是同一根因(权重迭代更新)的两面。基于这一洞察,PRISM 在兼容 parallel scan 的线性状态上显式重建了该迭代模式,通过局部 anchor 代理消除 token 间串行,通过闭合式预计算消除 step 间串行,最终呈现为一个统一的残差拟合过程:第一步自然退化为线性注意力的标准写入,后续步以不到 10% 的参数增量叠加低秩修正。在四个序列推荐基准上,PRISM 匹配 TTT 质量且吞吐量提升 174 倍;与少量 Transformer 层组成混合架构后超越纯 Transformer baseline。
复杂度的同时,实现 TTT 级别多步深度写入的序列模型。PRISM 通过分析 TTT-MLP 的梯度结构,揭示其高表达力源于 步长 × 残差 × 方向 的多步迭代模式,并发现这一高表达力与串行瓶颈是同一根因(权重迭代更新)的两面。基于这一洞察,PRISM 在兼容 parallel scan 的线性状态上显式重建了该迭代模式,通过局部 anchor 代理消除 token 间串行,通过闭合式预计算消除 step 间串行,最终呈现为一个统一的残差拟合过程:第一步自然退化为线性注意力的标准写入,后续步以不到 10% 的参数增量叠加低秩修正。在四个序列推荐基准上,PRISM 匹配 TTT 质量且吞吐量提升 174 倍;与少量 Transformer 层组成混合架构后超越纯 Transformer baseline。
该工作已被机器学习领域顶级会议 ICML 2026 录用,论文题目 “PRISM: Parallel Residual Iterative Sequence Model”。
一、背景:从无限背包到有限背包
(一)Transformer 的无限背包与线性注意力的有限背包
Transformer 的 Attention 机制本质上是一个 "无限背包":它把每一个 token 的 KV 都完整保存在 KV Cache 中,推理时逐一比对。这带来了极强的表达力,但存储和计算量随序列长度 N 呈  增长,当上下文达到百万 token 量级时,即便顶尖 GPU 也难以承受。
增长,当上下文达到百万 token 量级时,即便顶尖 GPU 也难以承受。
为此,一系列线性复杂度序列模型(如 Linear Attention、RWKV、Mamba、Gated DeltaNet 等)提出了 "有限背包" 方案:用一个固定大小的状态矩阵  压缩存储所有历史信息。不管序列多长,S 的大小不变,复杂度降为
压缩存储所有历史信息。不管序列多长,S 的大小不变,复杂度降为  。
。
背包容量有限,每来一个新 token,模型必须决定往里写什么、同时擦掉什么。这个 "写与擦" 的规则,决定了有限背包模型的天花板。但在深入讨论 "写与擦" 之前,我们先要回答一个更基本的问题。
(二)有限背包本质上是 RNN,为何还能并行?
确实如此,有限背包模型的数学形式本质上就是 RNN:

每一步的状态  依赖上一步的
依赖上一步的  ,这看起来天然串行,必须从
,这看起来天然串行,必须从  一步步算到
一步步算到  ,无法直接并行化。那为什么大家说 Linear Attention / Mamba 是 "可并行的"?
,无法直接并行化。那为什么大家说 Linear Attention / Mamba 是 "可并行的"?
关键在于一个数学技巧:Parallel Scan(并行前缀扫描)。
当递推关系(recurrence)的形式满足线性结构 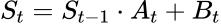 (其中
(其中 都只依赖当前输入
都只依赖当前输入 ,不依赖
,不依赖  )时,这个递推可以被改写为满足结合律的二元运算。一旦满足结合律,就可以用类似 "求前缀和" 的方式并行计算,其原理与经典的 parallel prefix sum 算法相同,区别仅在于基础运算从标量加法推广为 "矩阵乘法 + 加法"。
)时,这个递推可以被改写为满足结合律的二元运算。一旦满足结合律,就可以用类似 "求前缀和" 的方式并行计算,其原理与经典的 parallel prefix sum 算法相同,区别仅在于基础运算从标量加法推广为 "矩阵乘法 + 加法"。
具体来说,N 步的串行递推可以在  的深度内完成,代价是多做了一些冗余计算(总计算量变成
的深度内完成,代价是多做了一些冗余计算(总计算量变成  ),但在 GPU 上墙钟时间大幅缩短。
),但在 GPU 上墙钟时间大幅缩短。
但这里有一个很强的前提: 和
和  必须是历史状态无关的,它们只能是当前输入
必须是历史状态无关的,它们只能是当前输入 的函数,不能依赖
的函数,不能依赖 。一旦
。一旦  或
或  需要读取
需要读取  才能算出来,结合律就不成立了,就无法应用 parallel scan 实现并行运算。
才能算出来,结合律就不成立了,就无法应用 parallel scan 实现并行运算。
GDN 满足这个条件: 和
和  都只依赖当前输入。所以 GDN 可以用 parallel scan 并行训练。
都只依赖当前输入。所以 GDN 可以用 parallel scan 并行训练。
(三)为什么并行这么重要?GPU 的 "搬运工" 瓶颈
一个常见的误解是将 "串行慢" 归因于更多的浮点运算。实际上,瓶颈在别处。现代 GPU 的计算核心(Tensor Core / CUDA Core)算力极为充沛,A100 GPU 每秒能做 312 万亿次浮点运算(312 TFLOPS)。真正的瓶颈不是 "算",而是 "搬"。
GPU 的存储分为两层:
HBM(High Bandwidth Memory,高带宽显存):容量大(40-80 GB),但读写速度 "慢"(约 2 TB/s)。模型参数、state 矩阵 S、中间 activation 都存在这里。
SRAM(片上缓存):容量小(每个 SM 约 192 KB),但读写速度极快(约 19 TB/s,快 10 倍)。GPU 的计算核心只能直接访问 SRAM。
打个比方:SRAM 像工作台(小但触手可及),HBM 像仓库(大但每次取货要走一趟)。
所以每一次计算都要经历一个 "搬运" 流程:把数据从 HBM 搬进 SRAM,在 SRAM 里算完,再把结果搬回 HBM。这个搬运的时间往往远超计算本身,这就是所谓的 memory-bound(存储带宽瓶颈)。
Parallel scan + fused kernel 的真正威力在于:把整个序列的 N 步递推打包成一个大算子(fused kernel),S 矩阵只需要从 HBM 搬进 SRAM 一次,在 SRAM 里一口气算完所有步,再搬回去。数据搬运次数从  降到
降到  。
。
如果不能 parallel scan(比如 TTT),每个 token 都要独立地跑一遍迭代计算,每个 token 都要独占一次 HBM 与 SRAM 之间的搬运,搬运次数是 ,硬件利用率断崖式下降。实测 TTT-MLP 比 GDN 慢 174 倍,根源不在于浮点运算量的等比增加,而在于 HBM↔SRAM 数据搬运次数从
,硬件利用率断崖式下降。实测 TTT-MLP 比 GDN 慢 174 倍,根源不在于浮点运算量的等比增加,而在于 HBM↔SRAM 数据搬运次数从  退化到
退化到  。
。
能否适配parallel scan 不仅是算法设计上的美学选择,更直接决定了 10-100 倍的实际运行速度差异。
(四)Rank-1 写入的瓶颈
以 GDN (Gated DeltaNet)为代表的线性注意力模型,每个 token 对 S 做的是一次 rank-1 更新:

"擦" 的部分实现了选择性遗忘: 是全局 scalar gate 控制整体衰减,
是全局 scalar gate 控制整体衰减, 在
在  方向上做 rank-1 的选择性遗忘,为新写入腾出空间。真正的瓶颈在 “写”:每次只能往 S 里写入一个 rank-1 的外积
方向上做 rank-1 的选择性遗忘,为新写入腾出空间。真正的瓶颈在 “写”:每次只能往 S 里写入一个 rank-1 的外积  (即两个向量的乘积,结果矩阵的所有行都是同一个方向的缩放),相当于在整个
(即两个向量的乘积,结果矩阵的所有行都是同一个方向的缩放),相当于在整个  的记忆矩阵上只改动了 " 一行”。
的记忆矩阵上只改动了 " 一行”。
如果一个 token 携带的语义是多维度的(它同时是某个句法结构的成分、某个语义角色的载体、某个 topic 的关键词),rank-1 的一行写入无法同时在这些维度上做精细调整。信息在压缩写入时不可避免地丢失。
核心矛盾:背包有限,每次却只允许写一行。这是当前所有线性复杂度模型的共有瓶颈。
(五)TTT 的突破与代价
既然 rank-1 写入太浅,一个自然的想法是:让模型学会更深的写入规则。
TTT(Test-Time Training)系列工作采取了一种根本性不同的策略:把记忆状态从一个 linear 矩阵 S 升级为一个 MLP 的权重矩阵。每来一个 token,对 MLP 的权重做多步梯度下降(multi-step GD),逐步精炼写入内容。这带来了显著的质量提升。
但 TTT 的多步 GD 打破了历史状态无关前提。每步的梯度  依赖当前权重
依赖当前权重 ,而
,而  又依赖前一步,这让
又依赖前一步,这让 不再是输入的纯函数,parallel scan 的数学前提从根本上被打破。后果很直接:每个 token 的计算都要独立地、串行地跑一遍梯度下降循环,fused kernel 打包不了,HBM 与 SRAM 搬运次数从
不再是输入的纯函数,parallel scan 的数学前提从根本上被打破。后果很直接:每个 token 的计算都要独立地、串行地跑一遍梯度下降循环,fused kernel 打包不了,HBM 与 SRAM 搬运次数从  退回
退回  ,带来 174 倍的速度差距。
,带来 174 倍的速度差距。
PRISM 要解决的核心问题:设计一个多步写入机制,同时满足两个条件 ——(1) 像 TTT 一样有 步长 × 残差 × 方向 的多步迭代深度;(2) 像 GDN 一样 都是历史状态无关的,能被打包成 parallel scan 的 fused kernel。
都是历史状态无关的,能被打包成 parallel scan 的 fused kernel。
二、分析:TTT-MLP 为什么效果好,但速度慢?
在设计 PRISM 之前,我们首先深入分析 TTT-MLP 的梯度结构,弄清楚它的高表达力到底从何而来。
(一)步长 × 残差 × 方向 模式的涌现
TTT-MLP 的状态是两层网络  。展开其 W₂ 的梯度更新:
。展开其 W₂ 的梯度更新:

每步更新具有一个结构模式:
步长:
 ,每个 hidden unit 的 activation,控制写入强度
,每个 hidden unit 的 activation,控制写入强度残差:
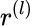 ,当前还没写好的部分,随着
,当前还没写好的部分,随着  更新逐步递减
更新逐步递减方向:
 ,写入的方向,因为
,写入的方向,因为 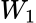 每步更新所以方向每步不同
每步更新所以方向每步不同
TTT-MLP 的高表达力正来自这个 步长 × 残差 × 方向 模式:多步残差递减提供了优化深度(depth),W₁ 多行提供多个方向则提供了表达宽度(width /rank-L)(即同时修改 S 矩阵的 L 个独立维度)。
(二)高表达力与串行是同一根因的两面
关键洞察:驱动 步长 × 残差 × 方向 模式的是权重每步更新。正是因为  每步都在变,方向才会变(width),残差才会减(depth)。但同一个 “权重每步更新” 也恰恰是串行的根源。
每步都在变,方向才会变(width),残差才会减(depth)。但同一个 “权重每步更新” 也恰恰是串行的根源。
具体来说,它造成了两个维度的串行瓶颈:
1. Token 间串行(Inter-token Seriality)
瓶颈 A(遗忘与写入的耦合):TTT 的梯度更新让 S 的遗忘和写入纠缠在一起,recurrence 无法写成第一节所述的线性形式  ,parallel scan 的前提不再满足。
,parallel scan 的前提不再满足。
瓶颈 B(残差依赖历史状态):每个 token 的残差  需要读取前一个 token 的精确状态
需要读取前一个 token 的精确状态 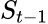 ,所有 token 的计算过程只能排队执行。
,所有 token 的计算过程只能排队执行。
2. Step 间串行(Intra-step Seriality)
瓶颈 C(方向与残差的同步):在多步 GD 中,第 l+1 步的写入方向必须等待第 l 步的权重更新完毕才能确定,残差也必须等上一步算完才能得到,强制引入一个无法展开的循环。
瓶颈 C 是最核心的矛盾:它同时是 rank-L 表达力的载体和步间串行的根源。因此消除瓶颈 C 不能简单取消迭代,必须在取消同步耦合的同时保留多方向和残差递减带来的表达力。
三、方法:PRISM 的设计与实现
基于上述分析,PRISM 的策略非常明确:在兼容 parallel scan 的线性状态 S 上显式重建 TTT-MLP 的 步长 × 残差 × 方向 模式,然后分维度消除串行。
(一)核心迭代形式:步长 × 残差 × 方向
PRISM 显式构造了 TTT-MLP 的多步迭代模式:

每步是  (步长 × 残差 × 方向),L 步累积 rank-L 写入。
(步长 × 残差 × 方向),L 步累积 rank-L 写入。
与 TTT-MLP 的对应关系:

为什么 PRISM 必须用学得的 而不能直接做多步 GD?因为在线性状态 S 上,线性状态的写入是
而不能直接做多步 GD?因为在线性状态 S 上,线性状态的写入是 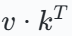 的外积,对 loss 求梯度时,行方向总是与 k 共线,梯度的行方向锁死在 k 方向上,L 步 GD 累积永远 rank-1。TTT-MLP 之所以能 rank-L,是因为MLP hidden layer
的外积,对 loss 求梯度时,行方向总是与 k 共线,梯度的行方向锁死在 k 方向上,L 步 GD 累积永远 rank-1。TTT-MLP 之所以能 rank-L,是因为MLP hidden layer 的非线性提供了隐式的多方向。PRISM 在线性状态上没有 hidden layer,必须显式引入 L 个可学习方向来补回这一能力。
的非线性提供了隐式的多方向。PRISM 在线性状态上没有 hidden layer,必须显式引入 L 个可学习方向来补回这一能力。
(二)消除 Token 间串行:A/B 分离 + 局部 Anchor 代理
遗忘 / 写入分离(解决瓶颈 A):PRISM 的遗忘项  保持跟 GDN 完全一致
保持跟 GDN 完全一致  ,所有非线性操作限制在写入项
,所有非线性操作限制在写入项  内。使迭代式保持
内。使迭代式保持 形式,parallel scan 骨架不动,Mamba 的 scan kernel 直接复用。
形式,parallel scan 骨架不动,Mamba 的 scan kernel 直接复用。
局部 Anchor 代理(解决瓶颈 B):用局部历史状态  (局部 anchor 基于短卷积(ShortConv)实现)替代全局状态 S 。Anchor 只依赖局部输入窗口,不读 S,所有 token 的迭代计算可以同时运行。
(局部 anchor 基于短卷积(ShortConv)实现)替代全局状态 S 。Anchor 只依赖局部输入窗口,不读 S,所有 token 的迭代计算可以同时运行。
至此,序列级别的 parallel scan 已完全恢复。anchor 让不同 token 的迭代可以同时启动,但每个 token 内部的 L 步之间仍需顺序执行(瓶颈 C)。
(三)消除 Step 间串行:解耦链 + 闭合式预计算
解决瓶颈 C。因为有了 anchor,两条链自然解耦:
Direction chain 解耦: ,因为 anchor 是预先给定的局部统计量(不依赖迭代过程),所有 L 个方向可以同时算出。
,因为 anchor 是预先给定的局部统计量(不依赖迭代过程),所有 L 个方向可以同时算出。
Residual chain 线性化:将迭代内的 GELU 非线性吸收进预先计算好的缩放系数(preconditioner) ,梯度下降的迭代过程退化为纯 element-wise 线性递推:
,梯度下降的迭代过程退化为纯 element-wise 线性递推:

由此多步迭代推算得到闭合式:

L 步的串行循环被消解为单步闭合式计算。整个多步梯度下降计算过程可以编译成一个 fused kernel,数据只需要从 HBM 搬进 SRAM 一次。
(四)架构全貌与 GDN 退化
多步梯度下降计算过程的原始产出是 L 个 rank-1 迭代计算:

观察迭代第一步使 ,此时尚无前序输出,残差等于初始输入本身,且无需经过非线性变换,因此第一步的写入自然退化为
,此时尚无前序输出,残差等于初始输入本身,且无需经过非线性变换,因此第一步的写入自然退化为  ,就得到了 GDN + 非线性修正项的形式:
,就得到了 GDN + 非线性修正项的形式:

PRISM 可以视为一种多步残差拟合计算过程,L=1 时精确退化为 GDN。 后续步只是在第一步的基础上追加非线性修正,且可以使用 low rank 网络增量,额外参数量不超过基础模型的 10%。
四、实验结果
(一)序列推荐
在公开序列推荐基准 Amazon 上,PRISM 表现与 Transformer baseline 效果接近,超过大多数线性注意力类方法。计算效率方面,PRISM 与 GDN 同级,比 TTT-MLP 快 174 倍。

(二)语言建模(基于 SlimPajama 2B 训练,130M 参数)
在更大规模的语言建模实验上(SlimPajama 2B tokens, Mistral tokenizer),PRISM 同样取得了全面领先:

PRISM 在 WikiText PPL、LAMBADA PPL 和 9 项 Zero-Shot 下游任务平均准确率上均为最优,领先 GDN 3.2 个百分点。
(三)组件消融

训练 PPL 差异极小,但下游泛化差异巨大。单步 solver (L=1) 的训练 PPL 几乎等于完整版,但 Avg ACC 下跌 2.9 个百分点 ——rank-L 的真正价值不在 next-token prediction 上,而在需要精确长程检索的下游任务上。
更值得注意的是 shared-K vs base-K 的对比:solver 两步共用独立的  几乎不掉分(−0.3),但复用 GDN base 的 key 则大幅退化(−1.5)。这说明 solver 需要自己的方向空间,在 GDN 已经写入的 key 方向上重复操作无法补充新信息。
几乎不掉分(−0.3),但复用 GDN base 的 key 则大幅退化(−1.5)。这说明 solver 需要自己的方向空间,在 GDN 已经写入的 key 方向上重复操作无法补充新信息。
五、延伸思考
(一)有限背包终究有限,混合架构也许是必然
即使有了 rank-L 的深度写入,有限背包终究是有限的。S 的容量是 ,当序列长到几十万 token,关键信息还是可能被覆盖。
,当序列长到几十万 token,关键信息还是可能被覆盖。
从 PRISM 的视角看,这个直觉有一个很好的技术解释。PRISM 用短卷积(ShortConv)计算的局部 anchor 替代全局状态 S 来近似残差。由于短卷积窗口通常只覆盖最近 3-4 个 token,对于需要跨越数千步的长程依赖,近似质量必然下降。
如果在 PRISM 层之间穿插少量 Transformer 层,后者就充当了一种全局的、非线性的历史状态精确计算器,能补偿 anchor 在长程上的近似误差。从这个角度看,Transformer 本身就是 ShortConv anchor 的 "全局升级版":ShortConv 用固定窗口的局部卷积近似历史状态,Transformer 用全局 attention 精确算历史状态。
这也许解释了为什么近期几乎所有表现最好的长序列模型(Jamba、Zamba、Griffin 等)都采用了混合架构:不是因为 Linear Attention 或 SSM 存在能力缺陷而需要 Transformer 作为补充,而是因为有限背包和无限背包在架构层面是互补的。前者提供  的高速处理和压缩存储,后者提供精确的长程检索。混合架构让模型有机会通过 Transformer 层找回有限背包中丢失的信息。
的高速处理和压缩存储,后者提供精确的长程检索。混合架构让模型有机会通过 Transformer 层找回有限背包中丢失的信息。
(二)线性注意力的 LoRA?
PRISM 的最终形式有一个有趣的结构特征:

这个 "基础迭代过程 + low rank 旁路" 的形式,跟 LoRA(Low-Rank Adaptation) 非常相似,这启发了一个微调场景下的有趣思路。
LoRA 的核心思想是:冻结预训练好的大模型权重,只在关键层旁边加一条 low-rank 旁路来做微调。受 PRISM 形式的启发,我们可以设想一种面向 Linear Attention / SSM 模型的参数高效微调方法:对已训练好的模型,冻结基础迭代过程,只在写入支路上增加一条 PRISM 风格的残差拟合旁路,此外,这条旁路有闭合式(不增加训练时间),而且第一步退化为原模型的标准写入(不破坏预训练知识)。这意味着它满足 LoRA 的两个关键要求:参数高效和不损害原模型能力。
结语
PRISM 验证了 "写入前思考" 范式在线性注意力模型中的可行性:通过分析 TTT-MLP 的梯度结构揭示 步长 × 残差 × 方向 迭代模式,在线性状态上显式重建该模式并通过 anchor 代理和闭合式预计算实现完全并行。最终架构极简 ——GDN + 非线性旁路,训练速度与 GDN 同级,参数增量不到 10%。在推荐和语言建模两个场景上的验证表明,这是一项通用的线性注意力增强技术。未来我们将进一步探索 PRISM 在更大参数规模上的 scaling 行为和推荐系统上的应用效果,以及其作为线性注意力模型参数高效微调方法的实际效果。
参考文献:
[1] Sun et al. “Learning to (Learn at Test Time): RNNs with Expressive Hidden States.” NeurIPS 2024.
[2] Yang et al. “Gated Delta Networks with Pairwise Tokenized Graphs.” NeurIPS 2024.
[3] Katharopoulos et al. “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention.” ICML 2020.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










