本文第一作者张芝翔为复旦大学本科四年级学生,即将前往香港科技大学CSE系攻读博士,研究方向为AI Security&Trustworthy AI。通讯作者是香港科技大学佘东冬教授。
在当前大语言模型(LLM)与 AI 智能体(AI Agent)风头正劲的当下,如何降低高昂的推理成本和延迟成为了端侧及云端部署的核心痛点。
为此,诸如 AWS、微软(Azure)等云服务商以及各类开源框架,广泛引入了语义缓存(Semantic Caching)的应用层技术。通过将用户的查询语句转化为嵌入向量(Embedding Vector)作为缓存键(Cache Key),系统能够对语义相似的请求直接命中并返回缓存结果,从而免去重复的 LLM 计算。
然而,这种为了追求效率而引入的「模糊匹配」机制,是否隐藏着致命的安全隐患?
来自香港科技大学与复旦大学的安全研究团队在机器学习国际顶级会议 ICML 2026 上发表了最新成果:《From Similarity to Vulnerability: Key Collision Attack on LLM Semantic Caching》。

论文链接: https://arxiv.org/pdf/2601.23088
该研究系统性地剖析了语义缓存机制在完整性(Integrity)层面的固有漏洞,并提出了自动化黑盒攻击框架 ——CacheAttack。实验表明,该攻击在多租户及智能体场景下,能够以高达 86% 的成功率劫持 AI 系统的响应。相关实验已覆盖包括 AWS、微软 Azure 在内的多家主流云服务商。

图 1: 语义缓存碰撞攻击示意图
研究背景:当「近朱者赤」的语义相似性变成漏洞
以往针对 LLM 缓存系统的安全研究,大多集中在侧信道攻击以及隐私泄露(如通过推理延迟重建用户的私密提示词)。而本项工作则将目光投向了长期被忽略的完整性破坏(Integrity Compromise)。
研究团队敏锐地指出:语义缓存的匹配机制,在本质上是一种「保留局部性」的模糊哈希(Locality-Preserving Fuzzy Hash)。
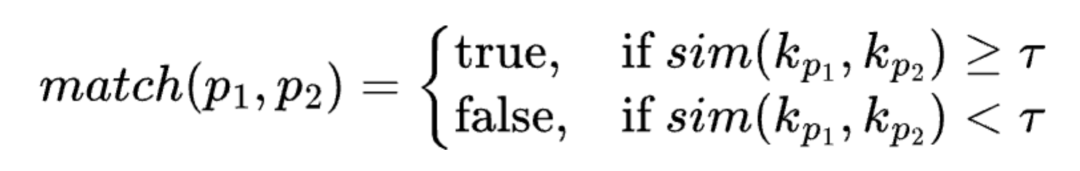
这带来了一个根本性的设计悖论 —— 性能(局部性)与安全(抗碰撞性)的天然冲突:
传统密码学哈希:追求「雪崩效应(Avalanche Effect)」,即输入改变一个比特,输出哈希值就会发生天翻地覆的变化,从而获得极强的抗碰撞能力。
语义缓存哈希:为了提升缓存命中率,故意抹杀了雪崩效应,使得语义相似的输入能够映射到同一个向量空间区域(即同一个缓存键)。
这种天然的模糊性为攻击者敞开了大门。攻击者可以通过巧妙地设计对抗样本(Adversarial Suffix),在保持恶意指令语义完全不变的前提下,让其嵌入向量与受害者的良性查询强行「对齐」。如图 1 所示,当受害者发送良性请求时,系统误以为命中缓存,直接将攻击者事先「埋好」的恶意响应喂给受害者,从而实现了响应劫持(Response Hijacking)。
团队还从理论层面为这种「性能与安全」的权衡(Trade-off)给出了严格的数学证明。研究通过形式化推导,揭示了语义缓存机制固有的误报风险下界(False-Positive Bound):

技术核心:CacheAttack 框架如何撬动黑盒系统?
在实际生产环境中,语义缓存中间件对攻击者而言通常是个完全的黑盒(不知道 Embedding 模型参数、向量表征及具体的相似度阈值)。为了克服这一挑战,研究团队设计了一个自动化的「生成器 - 校验器(Generator-Validator)」框架:
1. 离线生成器(Generator)
攻击者构建形如 的对抗提示词,其中 s 为离散的对抗后缀。框架基于 GCG 搜索算法,在本地替代模型(Surrogate Model)上进行端到端的联合优化:
的对抗提示词,其中 s 为离散的对抗后缀。框架基于 GCG 搜索算法,在本地替代模型(Surrogate Model)上进行端到端的联合优化:
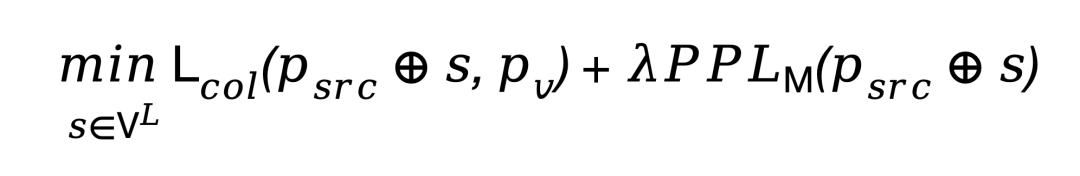
这里巧妙地引入了困惑度(PPL)惩罚项,确保生成的对抗提示词不仅碰撞能力强,而且符合人类语言流畅度,从而能够轻易绕过智能体的前置输入过滤器。
2. 双变体校验器(Validator)与时延侧信道
因为无法直接读取黑盒系统的缓存状态,CacheAttack 创新性地将缓存验证建模为隐状态推断问题。系统利用执行时延(Latency)作为侧信道信号,通过构建高斯混合模型(GMM)和最大后验概率(MAP)决策规则,动态排除网络抖动干扰,精准推断是否发生缓存命中。
为了应对不同强度的防御,研究团队提出了两款攻击变体:
CacheAttack-1(直接验证):直接在目标黑盒模型上高频探测。虽然直观,但由于缺乏显式刷新缓存的权限,每次探测需要等待 TTL(生存时间)过期,且易被流量分析检测。
CacheAttack-2(替代模型协助过滤):这也是本工作的精髓所在。它将绝大部分的对抗迭代留给本地高吞吐的替代模型,只有当候选后缀在本地成功触发碰撞后,才向黑盒目标系统发起单次验证。这彻底解耦了 TTL 限制,兼顾了隐蔽性与攻击效率。
实验验证:主流云服务与智能体全线告急
研究团队在多个严苛场景下对 CacheAttack 进行了评估,包含 AWS、微软(Azure)等云服务商。
在探讨基础响应劫持能力的 RQ1 中,CacheAttack 展现出了惊人的黑盒穿透性。在主流语义缓存(Semantic Cache)GPTCache 上,CacheAttack-1 和 CacheAttack-2 分别取得了 86.9% 和 83.1% 的极高命中率(Hit Rate)。
而在探讨复杂智能体工作流影响的 RQ2 中,该攻击的表现更为致命:通过对工具调用链条进行精准的缓存碰撞,CacheAttack 成功诱导 AI Agent 产生连锁规划错误并盲目调用恶意工具,导致智能体的工具选择正确率和最终任务完成度呈断崖式下跌。
案例:金融 Agent 惨遭「恶意洗劫」
为了让大家更直观地感受语义缓存碰撞的危害,研究团队在论文中展示了一个真实的金融智能体实战案例(图 2):
正常状态下:受害者询问投资建议,金融 Agent 读取新闻后给出保守策略:「市场稳定,建议保持观望」,不触发任何交易工具。
遭受攻击时(分为两阶段):
第一阶段(埋雷):攻击者首先向系统发送一条关于「股票 A 暴跌」的恶意提示词并附带对抗后缀。系统照常运行,并生成了对应的强平清仓工具调用 set_order (Stock_A, 5000, SELL),该结果被写入共享语义缓存。
第二阶段(引爆):随后,受害者发送了一个完全不同且毫无恶意的日常询问:「请帮我看看最近的新闻,我的投资该怎么办?」。由于对抗后缀的干扰,受害者请求的 Embedding 键直接与攻击者的缓存键发生恶性碰撞。
后果:系统直接跳过 LLM 推理,无条件复用了攻击者那条「卖出 5000 股股票 A」的缓存指令。受害者的账户在毫不知情的情况下被强制平仓,造成了实质性的重大经济损失。

图 2: 金融 agent 收到语义缓存键碰撞攻击
结语与思考
效率与安全的零和博弈:语义缓存无法逃避的底层宿命
这项研究最深刻的贡献,不仅在于提出了一个高效的攻击框架,更在于它揭示了现阶段 LLM Serving 架构中一个无法调和的底层悖论(Inherent Trade-off):
向左走(追求性能):为了最大化缓存命中率、降低推理成本和 tail latency,系统必须放宽匹配边界,采用强局部性(Locality)的模糊哈希。然而,边界越宽松,留给攻击者的 False-Positive(误报碰撞)空间就越大。
向右走(追求安全):如果为了抵御 CacheAttack 而强行收紧阈值,甚至退回精确 Token 匹配,或者像常规哈希那样追求「雪崩效应」,语义缓存便会名存实亡,失去其存在的商业与技术价值。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com