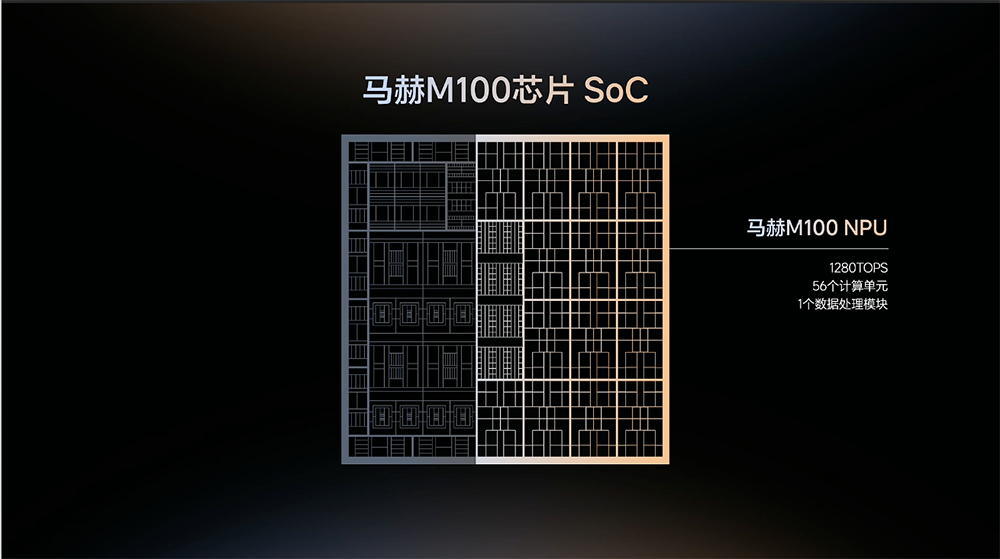
273GB/s带宽,56个NPU计算单元!理想马赫M100芯片细节披露。作者 | ZeR0编辑 | 漠影芯东西6月15日报道,刚刚,理想汽车在Livis Day活动上展示了其采用5nm制程的自研AI芯片马赫M100,披露架构细节,并称这是“全球首款动态数据流AI芯片”。不久前,理想马赫M100已搭载在其最新上市的全新理想L9车型上,随着车型上市交付,已经实现落地商用。马赫M100采用5nm车规级工艺,基于数据流架构设计,算力达1280TOPS,算力利用率达82%。“给我拍张照片,要不网上留下的都是我举桌子的。”理想汽车董事长兼CEO李想举起马赫M100芯片说,“这张照片,在我旁边标上「全世界性能最强的AI芯片」。”理想汽车基座模型负责人詹锟谈道,双马赫M100芯片算力达到2560TOPS,模仿学习规模提升50%,强化学习规模提升15倍,模型参数量提升10倍,模型计算量提升15倍。理想汽车CTO谢炎详细解读了马赫M100芯片,称这是“全世界量产的最强大的车规级算力芯片”。他解释说,基于SMT架构的GPGPU,达到82%的实际算力利用率是非常困难的。AI的计算天然是并行的。数据是张量的,关系是确定的,数据流动路径是清晰的。让数据的流动来驱动计算的发生,让架构本身围绕AI的计算形态来设计,这就是数据流架构。“它是用完全不同的思路造出来一栋完全不同的房子。”谢炎谈道,“冯·诺伊曼架构用70年推动了通用计算的辉煌,今天我们以马赫M100为起点,希望用数据流架构接过历史这一棒,继续推动AI计算再辉煌70年。”马赫M100芯片SoC把超过一半的面积给了神经网络处理器(NPU)。NPU包含56个计算单元,提供1280TOPS AI算力。CPU部分由24核Arm Cortex-A78AE核心组成,主频为2.3GHz,这是车载旗舰级大核,负责安全和系统控制。另外还有8路LPDDR5X子系统实现273GB/s高带宽,提供片外大容量内存高速通道。据谢炎分享,与全球智驾领域主流芯片英伟达Thor-U直接对比,基于CNN的骨干网络、UniAD和理想马赫VLA模型,每一个测试,马赫M100全部超越Thor-U,不是略微领先,而是数倍的性能差距。除了智能驾驶外,马赫M100还能跑其他大模型,比如部署Qwen3.5-35B-A3B通用大模型。英伟达桌面超算DGX-Spark的售价4万元,测试结果显示,马赫M100的prefill速度是DGX-Spark的2.7倍,decode速度是DGX-Spark的1.5倍。“这是一个装在车里的芯片,比一台4万块的桌面超算跑得更快。”谢炎说。今年马赫M100芯片架构的论文已经入选国际顶会——ISCA 2026国际计算机体系结构研讨会工业分区。谢炎强调道,理想汽车是汽车行业中历史上第一家在ISCA工业分区获得论文录取的企业,与其同期入选的是谷歌、美光、Meta、Ampere、MongoBoost等。理想汽车提出并实践了一种创新的架构思路,马赫M100架构团队将于6月30日在ISCA 2026会议现场进行主题分享。最好的芯片还不够,理想在马赫M100的基础上构建了一套完整的具身智能系统,包括心脏、眼睛、大脑、手脚、神经系统,这些模块协同工作,形成一个整体。星环OS是理想为AI原生设计的操作系统,“感知-决策-执行”全链路深度融合,通过系统协同,把端到端延时压缩到0.28秒,反应速度比人类快40%。安全也是马赫M100最重要的价值之一。理想将把密钥保护、设备身份、可信启动链、关键权限管控全部前置到芯片设计中,再通过全栈自研的软件实现统一调度,让芯片、编译器、操作系统、AI算法在同一套可信的基础上协同运行,这是覆盖全链路的纵深防御体系。随着马赫M100量产部署,理想汽车已实现芯片编译器、操作系统、AI算法及域控制器的全栈自研,系统的每一行代码、每一处硬件设计、每一套运行逻辑全部由理想自己掌控。马赫M100的能力远不止于智能驾驶,它已经跑通了车上所有智能化场景,能运行大语言模型、支持智能代理,将驱动具身智能,还会支持更多我们今天还没有想到的AI场景,并将持续进化。谢炎总结说,这就是理想造芯片的原因,不是为了今天,是为了接下来的70年。