点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
闭着眼在口袋里摸出钥匙、戴着厚手套把线穿进针眼、捏起一块豆腐又不把它捏碎——这些事你不用看,靠手就能完成。换成今天最强的 VLA 机器人,大概率要翻车。
原因很简单:VLA 这套范式,本质是「看着干活」。 它把视觉、语言、动作接到一个统一接口里,这两年语义理解和泛化突飞猛进——你说「把红色的杯子递给我」,它能听懂、能找到、能递过去。
但任务一旦进入「接触」环节——拧、插、捏、抹——光靠眼睛就不够了。眼睛能看到手「在哪」,却感觉不到手「使了多大劲、有没有打滑」。这块缺的拼图,就是触觉。
触觉重要,早就是共识。这些年触觉路线也没闲着:从把力觉直接喂给模仿学习策略,到联合预测未来的触觉或视觉,再到把触觉当成低层的快速修正信号接进控制器;怎么把触觉塞进 VLA,也已经有 VTLA、OmniVLA 这些代表作在探。
触觉对建模动力学、对接触型任务有多关键,这一点没人会反对。
可奇怪的是,今天主流的技术报告里,真正用上触觉的还是少数。为什么?道理也不复杂:触觉这条路线还没收敛,传感器、处理方法都还在试错;更头疼的是,触觉信息怎么和 backbone 接得更顺、怎么和视觉语言这些模态对齐,本身就是个大难题。
说白了,大家都知道触觉是好东西,但还没摸清「怎么把它优雅地塞进去」。
最近,徐丹飞和李飞飞的一篇新工作给了个挺新的思路,合作者里还有英伟达的 Jim Fan——光这个阵容,就值得点开看看。(老读者应该记得,我们之前专门聊过徐丹飞那条线。)

论文标题:T-Rex: Tactile-Reactive Dexterous Manipulation arXiv:https://arxiv.org/abs/2606.17055 项目主页:https://tactile-rex.github.io/
T-Rex 先把现有「让机器人用触觉干活」的做法,理成了三类,每一类都点明了长处和没解决的事。
第一类,把触觉直接接进操作策略。最早的做法很糙——拿个浅浅的 MLP,把触觉读数当额外输入,塞进模仿学习策略就完事;后来越做越精细:有人专门设计了能感知刚体位姿的触觉表示,有人让模型联合预测「未来视觉/未来触觉 + 动作」,也有人把触觉放进低层的动作修正模块里。这一类已经把一件事证明清楚了:在抓取稳不稳、细小接触怎么调、捏软乎乎的可变形物体这些事上,触觉是真有用。
第二类,触觉感知版的 VLA。这一类开始把触觉当成 VLA 的一个额外模态,或者干脆显式去对齐视觉、语言、触觉的 latent,也有人专门为「力与接触」这种信号设计结构。思路对,但有个共同缺口:大多还没形成一套「先大规模预训练、再用触觉做中期训练补能力」的标准打法,尤其在双手灵巧操作这种最难的场景里更少见。论文说得很直白:现有工作大多还停在单臂、或者平行夹爪。
第三类,大规模第一视角人类视频预训练。EgoScale、EgoVLA、EgoMimic 这一批,从人的第一视角视频里学操作先验——这条路的价值早被反复证明。(我们去年 8 月也写过第一视角人类视频那条线。)它给的是大量视觉语义和手部交互先验,但短板也明显:它压根没覆盖机器人的触觉信号,更没覆盖「机器人一接触到物体、就得实时改动作」的那段闭环控制。
T-Rex 的聪明之处,是不押单一路线,而是把这三件事拼到一起:保留大规模人类视频预训练(拿视觉语义和手部先验)、补一套触觉同步的机器人中期训练数据(把机器人真正接触时的触觉补上)、再用一个能区分「低频规划」和「高频修正」的结构,把两边接起来。
打个比方,这套结构特别像人干精细活时的两套节奏:低频规划,是大脑在想「接下来该拧哪、往哪插」;高频修正,是手指一感觉到打滑,不等大脑反应过来就先使了把劲。T-Rex 想做的,就是让机器人同时拥有这两套节奏——既有 VLA 给的「脑子」,又有触觉给的「手感」。
路线还没收敛,T-Rex 未必是终局。但它至少把一件被绕过去太久的事摆回了台面:VLA 这两年补语义、补泛化、补世界模型,补到现在,该补「手感」了。一个只会看、不会摸的机器人,永远干不了最需要手上功夫的那些活。

数据与训练配方:22889 小时「看人干活」,换那 100 小时的「手感」
做具身的人都懂一个道理:真正贵的,从来不是「任意的机器人数据」,而是足够多、足够广、还带着同步触觉的灵巧操作数据。T-Rex 想清楚了这件事,所以它没把数据集做成「少数几个任务反复演示」的长尾集合,而是围绕两个轴去铺——动作原语和物体交互。
什么叫动作原语?说白了,就是操作的「基本动作单位」——拧、插、推、捏、倒……复杂任务都是这些原语拼出来的,有点像操作版的乐高积木。T-Rex 拿 207 个常见家居物体,去和 22 个动作原语做组合,理论上能配出 4554 种「物体-动作」对。但这里面一大半物理上根本不成立(你没法「拧」一个西瓜),逐个做可行性筛查删掉之后,最后留下 502 个真正有效的组合,共 7755 条轨迹。
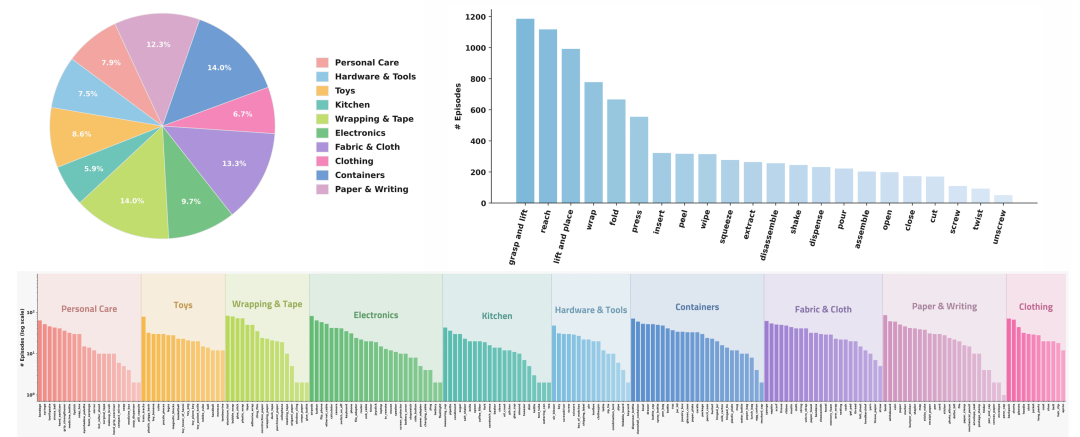
这些轨迹有多「实」?中位长度 29.8 秒,四分位区间 21.0 到 41.1 秒,平均每个有效组合约 16 条演示。每一条都不是光有画面,而是同步打包了:头部相机 + 两个腕部相机的 RGB、双臂的本体状态、双手指尖的触觉力向量、接触的形变图,再加一句语言指令——高层线程按 30 Hz 对齐时间戳。说白了,机器人每一刻「看到什么、摸到什么、使了多大劲、被要求干什么」,全都对得上。
为了不让策略只会「死记固定布局」,T-Rex 还特意在场景上加了扰动:6 种桌面背景、随机摆放的干扰物、目标物体的初始位姿也随机化。逼着模型去理解任务本身,而不是背答案。
有个细节挺值得说。这套数据的语言标注,不是人一句句手写的,而是先让一个商业视觉语言模型,根据几帧采样画面 + 物体名 + 动作原语名,自动生成命令句,再由人工核验、过滤掉幻觉和不准的描述。这招很省成本,但也提醒了一件事:标注质量,始终是整条流水线里那个不能松手的环节——AI 起草、人来把关,这套配合本身就是当下做数据的常态。
T-Rex 的低频动作规划和高频触觉修正
T-Rex 的策略输入包含当前 RGB 观测 、语言指令 、触觉力历史 和触觉形变图 。作者把多模态context记为:
并让策略预测未来一段动作块 。动作生成采用 conditional flow matching,训练目标写为
这里 表示干净的动作块, 表示高斯噪声; 要学习的是从噪声轨迹回到真实动作轨迹的向量场。这个写法本身不稀奇,关键在于后面怎么把它拆成两个频率不同的 expert。
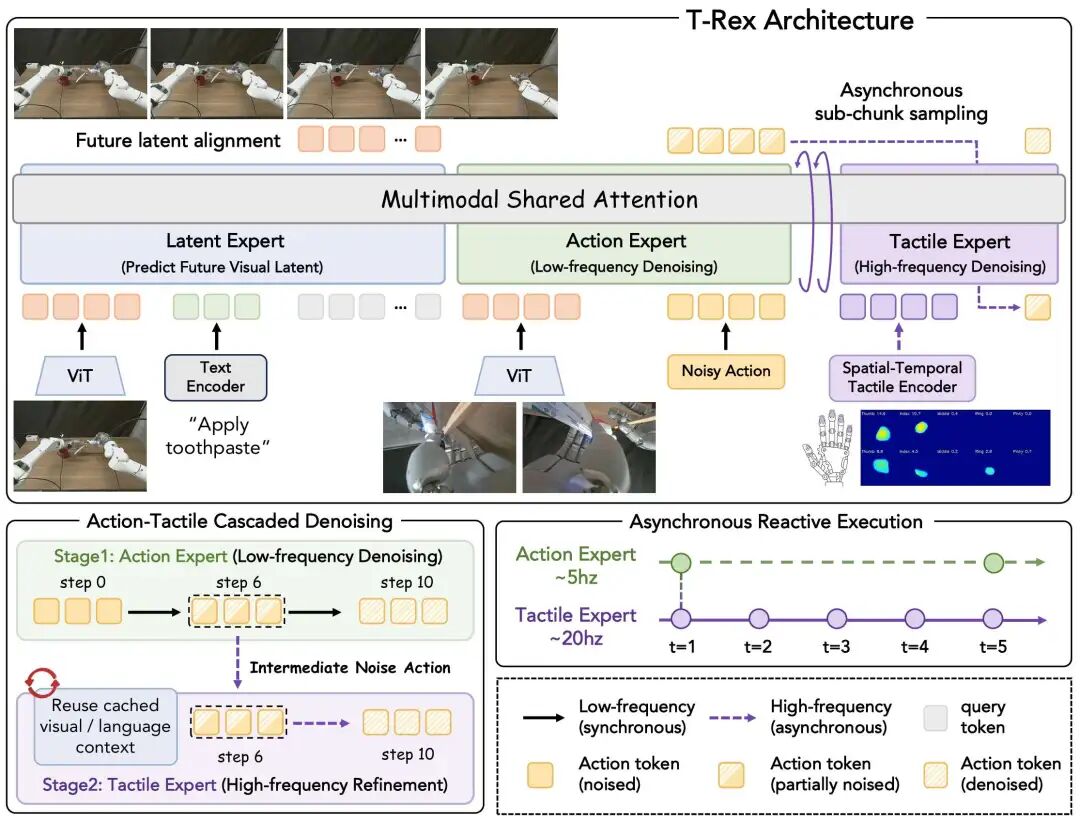
T-Rex 的骨干是 Mixture-of-Transformer-Experts(MoT)。三个 expert 的职责分工是:
latent expert:处理视觉和语言,预测未来视觉表征,给动作生成提供带时间方向的上下文; action expert:在较低频率上完成动作去噪,先生成一个中间动作状态; tactile expert:复用冻结的视觉-语言上下文,在更高频率下根据实时触觉继续去噪,输出最终动作。
触觉编码器不是简单地把一帧力信号扔进去。作者把它写成
这条式子对应三部分信息:
:对最近 16 帧力历史做时间编码,捕获接触变化过程; :把时间编码后的力觉表示量化到离散 token 空间里,降低噪声和漂移影响; :保留当前时刻的瞬时力信息,避免只看历史而丢掉此刻接触强度; 与 :从当前形变图提取空间接触几何,例如边缘、剪切、滑移痕迹。
附录给了更多实现细节。每根手指的力觉时间窗长度是 ,VQ-VAE 的 codebook 大小是 ,codebook 用 EMA 更新;为了避免模型只学到“多数时间没接触”这种主导状态,重建损失对高接触力帧施加更高权重。另一方面,形变图编码器先用自监督卷积自编码器预训练,再在策略学习阶段冻结。这个组合说明作者很在意两个问题:一是高频触觉的时间动态,二是不同触觉硬件下常见的噪声与漂移。
真正的核心创新是 异步触觉反应级联流匹配。这里先定义共享的 flow 目标:
是演示动作块, 是高斯噪声, 是两者之间的线性插值, 是整个去噪过程要回归的常速度目标。action expert 和 tactile expert 都学习这个同一个目标,但它们处理的是不同时间段的去噪区间。
慢速流先跑上半段。推理时总共使用 个 Euler 步,并把分界点固定在 :
这一步的意思是,让 action expert 先从纯噪声 出发,完成 6 步低频去噪,得到一个中间动作状态 。它已经包含了视觉、语言和整体动作意图,但还没有被实时触觉充分修正。
快速流再接手下半段:
这里动作块长度 ,tactile expert 会在块内偏移 这些时刻被异步触发。它不再重复整套视觉网络,而是直接读取实时触觉 token 和缓存下来的视觉-语言上下文,对中间动作做高频修正。论文把这一点看得很重,因为真正的接触反应,本来就应该建立在“视觉上下文相对稳定,但触觉变化很快”的事实上。
训练目标相应拆成两部分:
主文里把 tactile expert 的条件写成 ,附录又进一步说明它实际上依赖两部分上下文:一部分是分界点缓存下来的 ,另一部分是高频触觉 token 。更重要的是,tactile expert 不直接看原始视觉观测,它只用触觉流和缓存的中间上下文来修正动作,这样才能把高频计算成本压下来。
总损失为
其中 ,。 用来约束 latent expert 预测未来视觉表征,让模型在训练时持续保持对未来交互结果的时间对齐。
附录里还有两个很容易被忽略、但实际上很关键的设计。
第一,工作会把 action 位置在分界点重新编码,再与视觉语言键值一起组成 。这样 tactile expert 看到的不是“最初的噪声时间编码”,而是已经部分去噪后的中间上下文。
第二,专门加入了 delay augmentation。部署时,视觉缓存和实时触觉天然存在时间错位,所以训练时显式从 里采样离散延迟,去模拟这种“视觉略旧、触觉更新更快”的状态。这个方案瞄准了工程实现上的一个痛点,很值得关注。
实验对比分析
1)用了Sharpa的手,和Dexmate Vega-1
实验平台是固定底座的双臂 Dexmate Vega-1,配两只 22 自由度的 Sharpa Wave 灵巧手。策略看头部和腕部相机图像、每根手指的触觉力向量与形变图,双臂用相对末端位姿增量控制,手指用绝对关节控制。评测基准一共 12 个接触丰富任务,每个任务测试 16 次,并按多阶段进度给分。

2)任务性能分析
T-Rex 在 12 个任务上的平均成功率达到 65%,最强基线 EgoScale 为 35%,整整低了 30 个点。
更有意思的是,给预训练 VLA 生硬加触觉输入并不自动带来收益,0.5 + tactile 的平均成功率只有 6%,甚至比不带触觉的 0.5 还差很多。这说明问题不在“有没有触觉”,而在“触觉是以什么结构、什么频率、什么训练方式接进去的”。

从具体任务看,T-Rex 在翻页、转移鸡蛋、开锁、取卡、酸碱中和这类依赖细致接触调整的任务上都有明显优势。论文给出的解读也很直接:大规模人类第一视角预训练提供了广泛的视觉运动先验,而触觉同步中期训练与异步高频修正,才让这些先验真正适配到接触丰富双手操作。
如果把全部触觉输入去掉,平均成功率从 65% 掉到 42%,相当于下降 23%。如果只保留较轻量的 MLP 力觉编码加形变图,成绩是 58%;只用形变图是 54%;只用力觉相关表示是 59%。这说明时间力觉和空间形变各自都有效,二者合起来最好。作者提出的 VQ-VAE 力觉编码,不是唯一贡献来源,但确实提供了更完整的高频触觉表示。

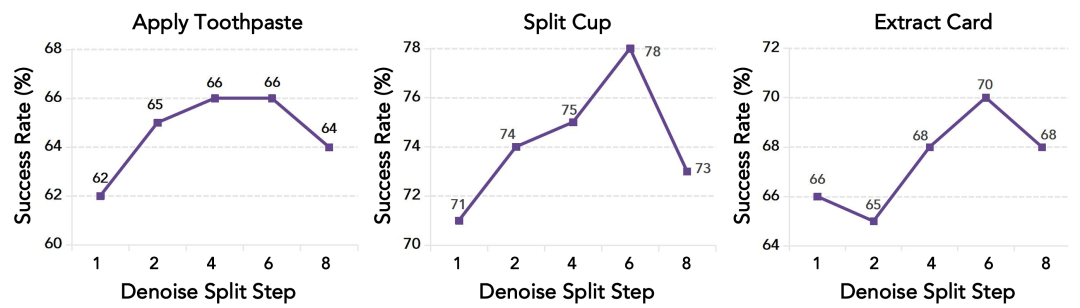
去掉异步后,平均成绩从 65% 降到 60%。同时,作者还扫了不同的分界步数,发现中间分界最优:分得太早,action expert 给后续修正留下的视觉动作先验不够;分得太晚,tactile expert 能参与修正的空间又太小。
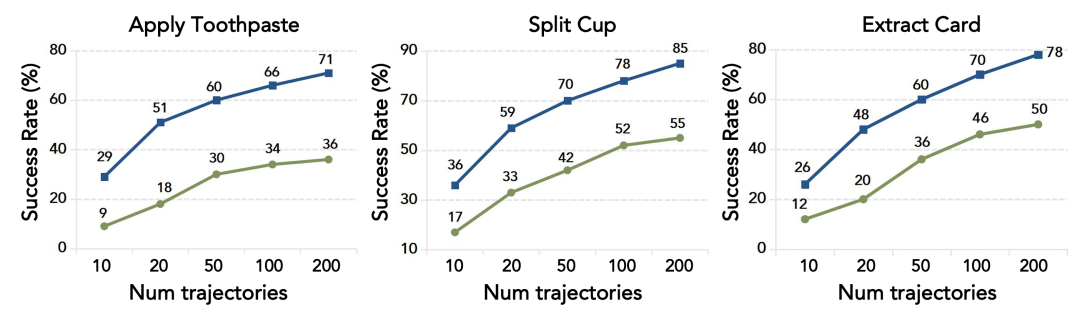
研究团队把 T-Rex 数据集与一个同样 100 小时、但来自 11 个任务专用采集的数据集做比较。结果很清楚:按动作原语和物体交互组织的中期训练数据,泛化更强,零样本迁移也更好。在后训练任务上,T-Rex 数据集版在 6 个代表任务里都领先;在零样本任务上,优势更明显,例如 Pick Cube 达到 45%,而任务专用数据中期训练只有 15%,没有中期训练则是 5%。
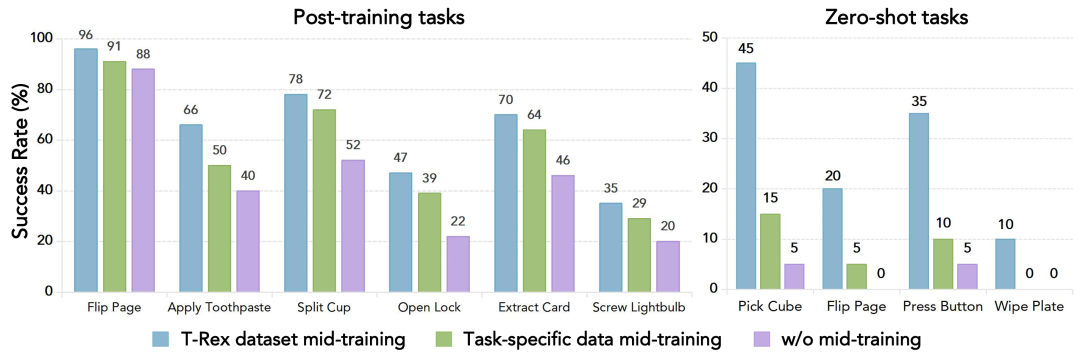
这套配方的收益还能从训练流程消融里再看一遍。完全不做大规模预训练也不做触觉中期训练时,6 个代表任务平均成功率只有 18%;只做触觉中期训练是 34%;只做大规模预训练是 45%;两者都做则达到 65%。这组数字很有说服力,因为它把三阶段路线里每一段的作用分开了:第一视角预训练负责提供广泛先验,触觉中期训练负责把这些先验真正落到机器人可执行的接触控制上。

最后还专门分析了失败案例。比较典型的几类问题包括:灯泡任务里的物体碰撞、开锁任务里的抓取滑脱、转移鸡蛋时的定位不准、麻将盒任务里的多指摩擦干扰、挤牙膏时用力过大,以及取卡任务里的滑动错位。作者据此给出的局限性也比较坦诚:一方面,长程任务里如果接触协调非常精细、遥操作采集又困难,后续可能还需要强化学习或在线交互修正;另一方面,触觉反应能力目前仍受硬件限制,包括传感器畸变、设备间标定漂移,以及缺少更密集的手掌触觉。

写在最后
T-Rex 的核心贡献,可以概括成三件事:一套 100 小时、围绕动作原语组织的触觉同步双手操作数据;一套把低频动作规划与高频触觉修正拆开的 MoT 架构;以及一条把大规模第一视角预训练、触觉中期训练和任务微调连起来的训练路线。
我觉得文中最有分量的结论有两个。第一,触觉确实不能只当成一个额外输入通道随手接进预训练 VLA ;第二,触觉中期训练数据如果按“物体-动作原语”来组织,收益并不局限在训练过的具体任务上,它还会影响后续微调效率和零样本迁移能力。
通过这篇工作和一些近期的工作,可以看到触觉方案正在走向成熟。
如果顺着这条线往后看,我觉得触觉方案接下来大概率会有三个变化。
第一,触觉会逐渐进入基础模型,而不是少数接触任务才临时外挂的模态;尤其到了 humanoid 和双手系统里,只靠视觉很难覆盖插入、滑动、旋拧、挤压这类动作。
第二,触觉数据的组织方式会继续从任务堆砌转向更可复用的交互单元,T-Rex 这种“物体-动作原语”的思路很可能会被保留下来,再往上接到更大范围的整机数据与评测体系里。
第三,真正限制上限的部分会逐渐从模型转到稳定硬件、统一表示和低成本采集流水线,因为传感器漂移、标定一致性、手掌级稠密触觉和多指协调,都会直接决定这些模型能不能从演示走向长期部署。
推荐阅读 :