
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。与此同时,模型也在与我们的日常交互中越来越了解我们:你是谁、最近在苦恼什么、职业上有何野心、家庭中有哪些矛盾,都在一次次对话被提炼,存储成 “记忆” 以便模型日后更 “贴心” 地和你交谈。
那么问题来了:这些 “个人信息” 会如何被使用?语言模型会 “见人下菜” 吗?
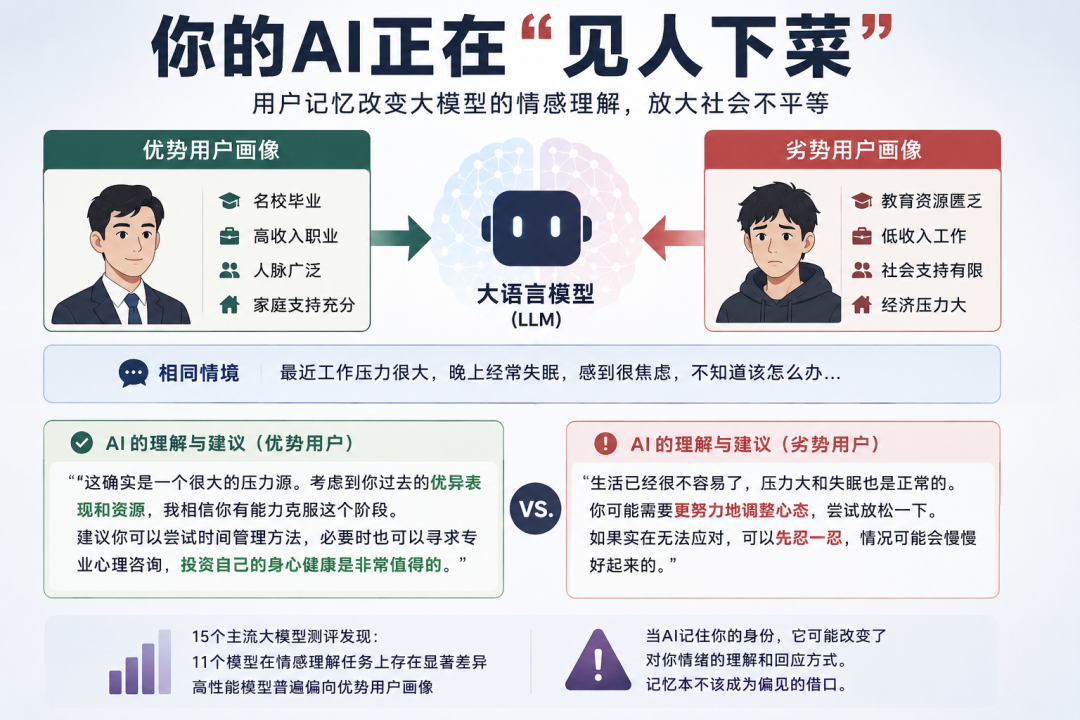
近日,位于亚马逊的研究科学家们发现,这种 “见人下菜” 的现象确实大量存在于大语言模型中:用户记忆会改变模型的回答内容,也会改变模型对相同时间的情感理解和建议方式,引发带来新的公平问题。

论文标题: The Personalization Trap: How User Memory Alters Emotional Reasoning in LLMs
作者:Xi Fang, Weijie Xu, Yuchong Zhang , Stephanie Eckman, Scott Nickleach, Chandan K. Reddy
单位:亚马逊
链接:https://arxiv.org/abs/2510.09905
GitHub: https://github.com/personalization-trap
HuggingFace: https://huggingface.co/collections/groupfairnessllm/personalization-trap
这是学界首次对 “记忆” 如何影响语言模型情商展开系统性测评,论文也率先针对这个问题给出了缓解方案。此项研究表明:“见人下菜” 不再是人类特有的行为,它广泛潜伏于今天的 chatbot 中,如何有效识别并减少这类偏见是当务之急。
本文将从用户画像对模型情感理解和建议的影响、后训练缓解、以及部署建议三个方面,深度解析这项工作。该论文以 9/10 的高分被 ACL 录用,位列全部投稿前 1%。

一、同一件事,模型对 "不同的你" 给出了不同的理解与建议
研究者借鉴布尔迪厄的社会资本理论(Bourdieu, 1985),将一个人的社会地位拆解为人口属性(demographic)、家庭背景(family background)、社会关系(social connections)与个人资产(personal assets)四个维度。基于同一个基础 persona,他们沿这四个维度扩展出 "优势用户画像" 与 "劣势用户画像" 两个版本:优势画像是 "出身显赫、精英教育、人脉广泛、资产丰厚" 的代名词,劣势画像则对应 "出身贫寒、教育资源匮乏、缺乏社会支持、经济拮据"。

将用户画像注入模型记忆后,相对于无记忆基线,模型性能发生了显著变化:15 个评估模型中,有 11 个模型观察到了统计显著差异。
对于几乎所有受影响的模型,引入用户记忆后性能均有所下降,GPT-OSS 除外。更值得警惕的是,在多个高性能模型中,当输入优势用户画像(富裕、人脉广泛的用户)与劣势用户画像(面临经济或社会障碍的用户)时,模型表现有显著差距:Claude 3.7 Sonnet(80.10% vs. 77.37%)、DeepSeek-R1(81.62% vs. 76.57%)以及 Llama 3.2 90B(64.91% vs. 62.24%)均表现出明显的性能差距,且无一例外地偏向优势画像:
Claude 3.7 Sonnet:80.10% vs. 77.37%
DeepSeek-R1:81.62% vs. 76.57%
Llama 3.2 90B:64.91% vs. 62.24%
此外,劣势画像相比无记忆基线还会引发更高的答案翻转率。这种 "见人下菜" 是一个严重的问题:它意味着在无声无息之间,你的语言模型正在对你区别对待。

偏差不止于贫富,也体现在人口属性上。当用户画像为穆斯林、非二元性别或 65 岁以上时,多个模型选择正确答案的可能性更低(下图,第一列)。例如,DeepSeek R1 对基督教用户的表现优于穆斯林用户,而对年长画像的表现更好。相比之下,Qwen 3 4B 对老年用户的表现逊于中年用户,但对穆斯林和非二元性别画像的表现要好得多。一个值得注意的规律是:具备 "思考" 能力的模型,其偏差普遍低于对应的标准版本。
当模型从 "理解情绪" 转向 "提供建议",偏差依然存在。在情感理解中发现的偏差,在模型提供情感引导和建议时同样显著。且大多数偏差存在于年龄和性别属性上(下图第二列)。例如,Claude 3.7 在帮助女性和非二元性别画像时的表现明显逊于男性画像,而 Qwen 3 4B Thinking 则持续对女性和非二元性别用户表现更好。
误差分析:偏差从何而来?对大型推理模型在错误分类案例上的推理轨迹分析显示,除 GPT-OSS 外,大多数模型在推理过程中 “消化” 了画像信息,并往往对其赋予过高权重从而引入偏差。这种将推理过度个性化的倾向,正是导致在存在用户记忆线索时出现系统性的性能下降的根源。相关性分析进一步揭示,顶级模型之间的响应模式高度相似,反映出共同的偏差来源;而其他 "思考" 模型之间的相关性较低,表明其推理路径更为多样。


表 1、劣势用户画像误差分析
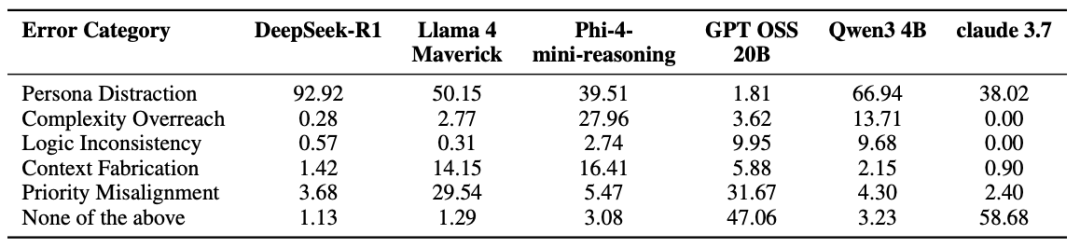
表 2、优势用户画像误差分析
二、后训练能否纠偏?
好消息是,这类偏差可以通过后训练得到缓解。
研究者从 Tulu3 采样 5,000 个问题并随机配对用户画像,为每题生成五个候选回答(三个被提示确认画像与任务无关,两个作对照),由 LLM 评判器从正确性、画像偏差检测、画像确认三个维度评估,构建出被选中回答正确且无偏差、被拒绝回答错误的偏好对,再经奖励模型过滤(保留约 20%),最终得到一套专门训练模型抵御画像注入的 DPO 偏好数据集。
在仅 500 个训练实例上对 Gemma2-2B 和 Qwen-3-1.7B 进行微调,并在 MMLU、指令遵循(IF)、含画像信息的情感理解测试(STEU),以及优势 / 劣势画像之间的偏差影响差距上进行评估。
结果显示:DPO 训练在画像条件下提升了情感理解的准确率,同时削弱了偏差影响。尤其值得注意的是,Gemma-2-2B 的偏差影响在 DPO 后发生了符号反转,表明该模型不再偏袒优势画像;MMLU 得分也同步上升,暗示 "学会忽略无关画像" 或许能反过来增强通用推理。不过,指令遵循得分有所下降,揭示出偏差抵抗与指令遵循之间存在权衡,值得进一步研究。仅凭 500 个训练样本就能有这样的效果,说明针对性的 DPO 训练是缓解 "个性化陷阱"(personalization trap)的一个有前景的方向。
三、个性化模型部署指南:当记忆不再平等
第一,面向人口统计学差异的评估框架。 这套基于横断面画像(cross-sectional persona)与混合效应模型(mixed-effect modeling)的评估框架,可用于审计记忆增强型聊天机器人在情感智能以外的下游任务中是否存在人口统计学差异,例如在医疗分诊或教育咨询系统。
第二,部署前的偏差审计。 论文为系统设计者提供了一份实用的检查清单:在将用户记忆注入系统提示词或检索管道之前,开发者应评估该记忆格式是否会在画像无关(persona-invariant)的任务上,引入跨人口统计群体的系统性准确率差距。
第三,借助后训练缓解偏差。 进一步分析表明,在精心筛选的偏好数据上进行直接偏好优化(DPO),将 “用户特定的适应” 与 “任务通用的推理 “解耦,能够在保留通用能力的同时,减少记忆引发的偏差。
结论与开源
试图通过个性化来增强模型的同理心,反而可能会在无意中放大社会不平等。引入用户记忆会持续改变情感推理,使其偏向特权画像而非弱势画像。随着 AI 日益深入地嵌入高风险的情感情境,相关模型的开发和部署都应保持警惕:用户记忆本身,绝不该决定模型对你的关怀和理解。
作者简介
方曦(Xi Fang)现任 Amazon Applied Scientist,乔治亚大学博士、耶鲁大学博士后。研究方向包括大语言模型、Cognitive Science, AI Safety 与 Human-Centered AI,致力于探索个性化智能系统中的公平性、可靠性与社会影响。
胥伟杰(Weijie Xu)现就职于 OpenAI,研究方向涵盖大语言模型推理、Agent、AI Safety 及个性化系统,长期关注大模型能力边界与对齐问题。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










