克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
全球最强超算,易主了!
中山大学教授带队、深圳制造的灵晟超级计算机,刚刚登顶全球超算TOP500榜单,打破了西方近十年的垄断地位。
更让人惊诧的是,这个TOP1超算,含英伟达量为0,甚至一块GPU也没用。
在超过2EFlops的超算系统中,独一无二,惊诧友邦。

△来源:中山大学计算机学院官微
具体来说,灵晟采用了自主可控的纯CPU架构,CPU芯片、存储架构和高速互连网络全部自研。
图灵奖得主Jack Dongarra评价,灵晟是“AI4S新型架构的希望之光”,将重新划定全球算力竞争格局。
0GPU含量,全链路自主可控
灵晟没有使用一块GPU,这在今天的超算领域几乎是一个异类。
El Capitan、Frontier、Aurora……当前TOP500前列的E级超算,无一例外都依赖GPU提供主要算力。
GPU擅长大规模并行计算,是过去十年超算性能跃升的核心驱动力。
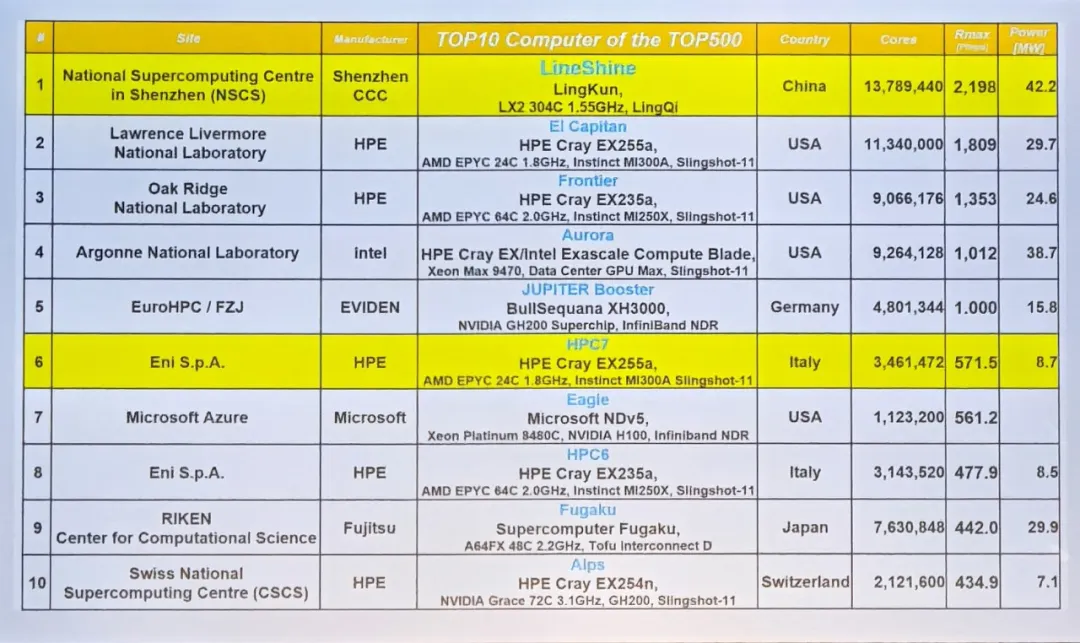
但灵晟选择了一条完全不同的路——Online Acceleration全CPU架构,而且芯片、互连、存储、操作系统到上层软件,全部自研。
灵晟的核心处理器是自研的LX2芯片。
LX2基于Armv9指令集,每颗LX2集成304个核心,主频1.55GHz,整机共部署约1379万核。
LX2并不是一颗传统意义上的通用CPU,其内部集成了AI矩阵加速单元,原生支持FP64、FP32、BF16、FP16、INT8多种精度格式,将矩阵加速能力直接内嵌进了CPU。
官方表示,灵晟在混合精度与稀疏/稠密矩阵计算等关键指标上,已超越传统CPU+GPU异构架构。
LX2的内存架构同样是灵晟的亮点。
灵晟是首款集成国产HBM的超算系统,每颗LX2片上都搭载了32GB国产HBM,内存带宽达4TB/s,同时搭配最高256GB的外部DDR5内存,兼顾带宽与容量。
相比传统CPU,灵晟的内存带宽提升了10倍。

△来源:国家超级计算深圳中心
网络层面,灵晟采用自主设计的灵启高速互连网络,支持200万个端口、10万节点的超大规模组网,节点间带宽达1.6Tb/s。
在软件层面,灵晟运行的是阿里巴巴基于RHEL开发的Anolis OS 8.9,并配套自研全栈软件,将灵晟的底层硬件能力以可编程、可优化的方式开放给上层应用。
散热方面,灵晟首创100%全液冷散热机柜,整机功耗42.2MW,能效比达52.07GFlops/W,在Green500能效榜上排名第50位。
灵晟能靠纯CPU架构在双精度浮点性能上登顶TOP500,并同步拿下HPCG榜单第一,证明了全CPU路线在传统科学计算场景下的可行性。

△来源:国家超级计算深圳中心
而将AI矩阵加速单元直接内嵌进CPU的设计思路,也让灵晟天然具备承载HPC与AI融合计算的潜力。
在大规模并行环境下,灵晟的平均扩展效率达84.4%,全系统可调度核心数超过千万。
9年,中国超算重返世界之巅
灵晟的夺冠意味着,时隔九年,中国超算重回TOP500榜首;上一次登顶,还是2017年的神威·太湖之光。
而且灵晟此次以全国产自主架构直接夺冠,给外界带来的关注也不止于性能数字。
灵晟是全球首台纯CPU架构突破2EFlops的超算系统,打破了E级算力必须依赖GPU的行业惯例。
超算行业里,GPU的统治地位由来已久。
过去十年,随着并行计算需求的爆发式增长,GPU逐渐取代CPU成为超算系统的核心算力来源。
据英伟达官方披露,在本届ISC2026发布的TOP500榜单中,英伟达技术支撑的超算系统数量已超过400台,占TOP500总数的81%。
当前TOP500前列的E级超算——El Capitan、Frontier、Aurora——无一例外都以GPU作为核心算力引擎。
GPU在超算领域的渗透,也让英伟达成为全球算力基础设施中几乎不可绕过的一环。
AI时代的到来,也进一步强化了这一格局。
大模型训练对GPU的需求,让英伟达的超算地位与AI产业深度绑定,形成了更难被撼动的生态壁垒。
灵晟的出现,是这个格局中罕见的异数。
图灵奖得主Jack Dongarra在颁奖现场评价,灵晟让世界看到了超算通向AI4Science新型系统架构的希望之光。
在HPCG榜单上,灵晟同步登顶,绩达22 PFLOPS,进一步印证了灵晟在传统科学计算场景下的综合实力。
灵晟的总设计师、国家超算深圳中心主任、中山大学教授卢宇彤,与这个领域的渊源可以追溯到更早。
2013年至2015年,卢宇彤以天河二号副总设计师的身份,六次站上全球超算最高领奖台,见证了天河二号创下的六连冠纪录。
时隔十一年,卢宇彤再度登台领奖,灵晟接续了天河二号的历史。

△来源:国家超级计算深圳中心
性能之外,灵晟的实际应用已在多个科学领域展开。
AI for Science(AI4S),正在成为超算领域最受关注的前沿方向。
从AlphaFold预测蛋白质结构,到大规模气候模型、药物分子筛选、材料性质预测,AI与传统科学计算的融合正在加速重塑各个基础学科的研究范式。
这对超算系统提出了新的要求,不仅要跑得快,还要能同时承载高精度科学模拟与大规模AI训练两类截然不同的计算任务。
现有的GPU加速架构在AI训练上表现出色,但在两种计算模式的深度融合上,仍存在架构层面的天然割裂。
灵晟的出现,很好地弥补了这个不足。
自灵晟系统部署以来,灵支撑大气海洋、工程仿真、材料科学、药物发现、脑科学、科学AI、大模型推理等方向的计算任务。
面向科学、工程、产业各领域的大规模应用需求,灵晟提供了多学科、全流程、多精度融合的科学智能应用平台,并已形成世界级应用成果。
参考链接:
[1]https://mp.weixin.qq.com/s/1wzSE-f3s47abkXGKbrbtw
[2]https://mp.weixin.qq.com/s/NzNYNqaoEizPmVhkKLI0Qw
[3]https://www.tomshardware.com/tech-industry/supercomputers/chinas-lineshine-supercomputer-dethrones-us-el-capitan-secures-first-place-in-top-500-list-f
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟










