
主讲人:邓亚峰
智猩猩整理
编辑:绿鲤鱼
让 AI 记住一亿个 Token,是什么概念?人一生持续学习到一百岁,大脑能调用的信息大约是 2 到 3 亿 Token;而主流大模型的“记性”通常被锁死在百万量级,一旦超出便开始胡言乱语。
在 2026 中国生成式 AI 大会(北京站)上,EverMind CEO 兼盛大集团副总裁邓亚峰,正是带着一组硬核数字登台。他们自研的 MSA(Memory Sparse Attention)架构,把上下文极限直接推到 1 亿 Token——当长度从 16K扩展到 1 亿时,准确率仅下降约 9%,而同场景下不少两千亿参数级的顶级模型几乎“全部罢工”。
这并非一次炫技。在“龙虾”“Hermes”等 Agent 产品轮番出圈的当下,邓亚峰抛出了一个更本质的问题:当模型能力被逐渐拉平,Agent真正的护城河是什么?他的答案是长期记忆以及由此生长出的主动性与自我进化(Self-evolving)。
围绕这两条主线,EverMind 取得了关键突破:
分层记忆系统EverMemOS 成为 ACL 2026 主会论文,是业内首个在 LoCoMo 评测上突破 90 分(约93 分)的方案
端到端的 MSA 架构则从底层重构了长上下文记忆
自我进化方向上,用Rubric-RL 训出仅 4B、却能比肩 235B 千问模型的小模型,并配套推出 EvoAgentBench 与 EverMemBench 两套评测基准
对每一位 Agent 开发者而言,这场演讲给我们的核心启示是: 让Agent 真正变强的,不是更大的模型,而是能沉淀、可进化的长期记忆。
以下是演讲实录:
邓亚峰:大家下午好,非常荣幸在这里和大家做一个分享。我们团队的名字叫 EverMind,是盛大内部正在孵化的、一个基于长期记忆的团队。如果各位关注这个行业,应该之前也注意到过我们的一些工作。
01
从“龙虾”到“Hermes”:
Agent 产品为什么受关注
去年春节大家记忆比较深的,是 DeepSeek 和推理模型;而今年春节,一个很重要的概念就是“龙虾”。当然,“龙虾”是一波热潮,现在其实已经有点降温。但我觉得它很重要的一点在于,它其实是未来 Agent 的一种原型产品——未来我们的应用,可能都应该是这个样子。

那么“龙虾”为什么会火?我觉得有这样几个原因:你跟它说一句话,它好像就能给你交付结果;它具备主动性、长期记忆这些特性;而且可以本地化部署,整个生态非常开放。我想说的是,它其实是人们脑海里那个“AI 贾维斯”的原型。和 Manus 比,很多事情 Manus 可能也能做,但为什么“龙虾”在这个时间点这么火?
另一个最近刚火起来的项目叫 Hermes Agent。我也访问了一些使用它的同事和朋友,其实它可能并没有那么好用,但为什么它能出圈?我觉得它在讲一个东西,叫 self-evolving(自我进化)。

“evolving”是什么意思?就像人和人交流一样,在这样一个交流的过程中——比如我讲完这个 talk,我自己也成长了;我听了别人的 talk,也有很多收获。再比如推荐系统,我们在使用它的过程中,AI 其实是在不断进步的。我觉得这是 AI 很重要的一个特性,而 Hermes 主打的正是这个概念。
02
我们心目中的 Agent 应该长什么样
接下来我想说,我们心目中的 Agent 应该长什么样?今天的数字世界基本上肯定是 Agent 的时代。除了大模型之外,它到底要满足哪些条件?

比较基本的几点:使用起来很顺畅,成功率很高,能持续用下去;比较安全可控;付出的成本和它创造的价值之间能够算得过来。
此外,在智能层面,我觉得有几个很重要的特性。
一是长期记忆。它需要能记得住。
二是主动性。 就像我们和同事合作一样,如果一个同事总是很被动,你讲了什么他才去做,你会觉得他没那么好用;而一个好的同事,会在你的基础上主动问你“咱们要不要做这件事”,或者告诉你“我已经做完了”,超出你的预期。我认为这是一种更好的体验。
三是自我进化。 它能不能像推荐系统、像人与人的智能那样,随着不断交流、不断学习而自己进步?这就是所谓的 self-evolving,或者叫 continue learning、self-improvement,这种类似的概念。
还有一点,现在大家、特别是硅谷在讲一个概念叫 harness 。今天来看,它基本上就等于:模型加上和 data 或 memory 有关的部分,再加上整个处理流程 process 部分,大概就组成了一个 Agent 的核心框架。 这也是为什么我们今天一起来讨论长期记忆这个方向,因为它非常重要。
03
为什么我们要做记忆:
从互联网的护城河说起
我自己在互联网领域工作了很多年,所以今天也要问一个问题:AI 应用、AI Agent 的壁垒或者护城河是什么?
我们做几个类比。OpenAI 曾经领先,今天 Claude、Anthropic 反而有点反超的趋势;Manus 出现之后,又有其他产品跟进;还有像 Cursor 和 Claude 之间的关系。问题在于,作为一个互联网应用,你的壁垒是什么?
回顾过去二十年比较成功的产品——从ASO,到传统搜索引擎(比如 Google、百度),再到推荐系统(比如字节)——这些团队之所以有大的商业成功,我觉得很重要的一个原因,特别是在中国这样的商业环境下,是你必须有壁垒。总结一下会发现,过去的壁垒大多来自用户交互:通过交互不断产生新的能力提升,从而形成一种用户体验上的壁垒或优势。

2012 年前后我们在阿里想做搜索引擎,也请了非常厉害的人,腾讯当时也在做。为什么做不过百度?因为百度先出发了,它形成了一个用户迭代的循环,自己在不断提高,后面追赶的人,仅靠技术是很难完全追上的。 这是我们过去得到的经验,或者说教训。
回到今天的话题,为什么我们要做记忆?因为今天的 AI 智能应用面临这样几个挑战:你能不能充分利用历史信息,比如“龙虾”就是在不断压缩数据;你能不能做到个性化,如果每次跟你聊天,我都像第一次见到你一样,这是有问题的;你的智能是静态的还是动态的;以及你的应用有没有护城河。

那么 memory 主要有什么价值和作用?
突破上下文窗口的限制,同时又不超出语言模型的上下文
在成本、速度和精度之间做一个很好的权衡(trade-off)
能不能基于长期记忆建立用户偏好、构建用户画像(profile)
能不能在 AI 系统上形成一种自主的、自我进化的智能
我觉得这些正是今天的长期记忆或者基于长期记忆的相关技术可以解决的。EverMind 基本上就在做这件事情。

大家可以看右侧,这是 Agent 的主要 loop,记忆系统要在其中去提取情景记忆(episodic memory)、语义记忆、程序性记忆(procedural memory),以及 profile、知识库(knowledge base)等等,再融合到整个 Agent 中。我们今天做的,基本上就是基于长期记忆、并且希望能做自我演化的 AI Agent 基础设施,来赋能 AI Agent。
04
长期记忆的三条技术路线
关于记忆的方案,按我自己的理解,基本上有三种路线。
人类有 working memory(工作记忆)——我们把数据放到大脑某一个区域去进行推理,那部分数据就放在 working memory 里,它很像语言模型的 context;除此之外的,我们就叫 long-term memory(长期记忆)。
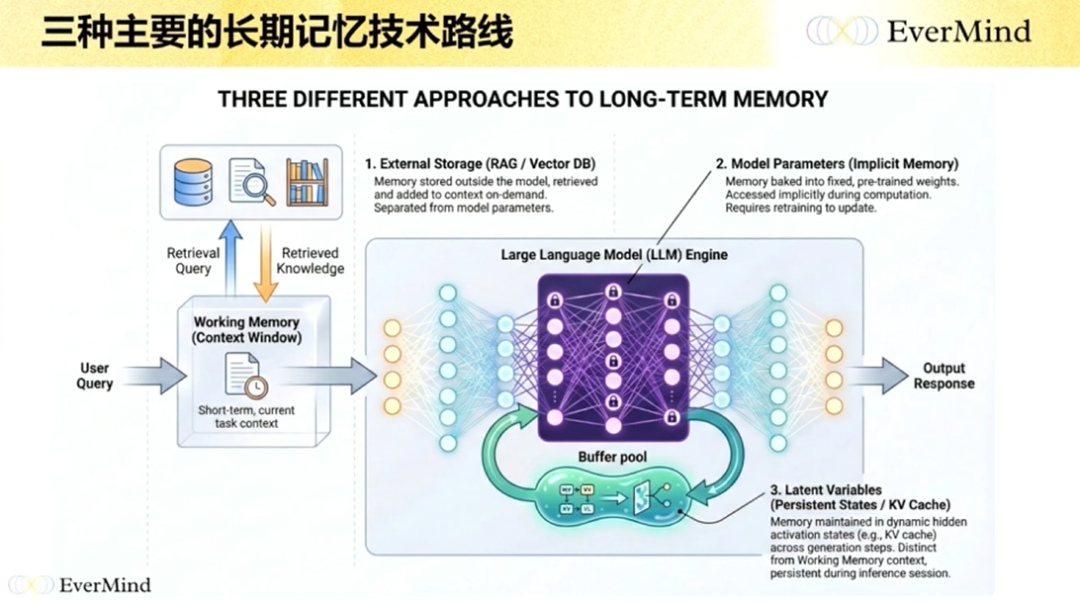
long-term memory基本上有三种路线。
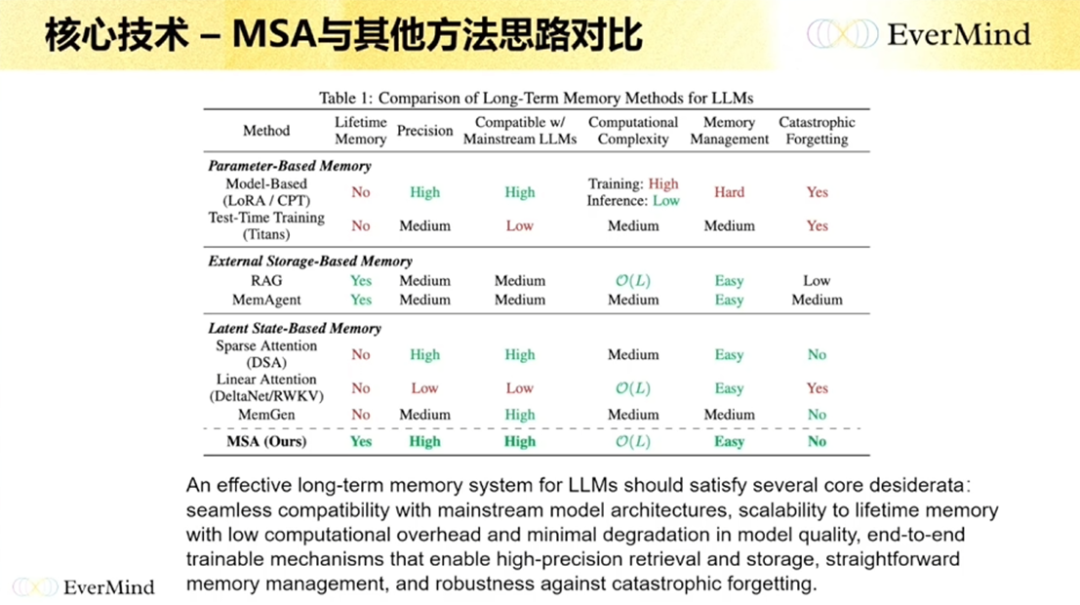
第一种,外挂的数据库。 无论是 RAG,还是今天讲的各种各样的记忆系统,本质都是在模型之外存储;模型需要的时候,我把总结好的数据给它就行。它的好处是很容易用,坏处是它和模型没办法端到端,也没办法解决多跳(multi-hop)的问题。
第二种,用模型参数去迭代记忆。 这方面也有一些工作在做,包括前一段时间DeepSeek 的相关工作就类似这个思路——通过把数据压进模型,来获得个性化,或者记录一些比较局部的信息。简单来说,SFT、LoRA 也可以理解成一种记忆模型。但它最大的挑战在于怎么处理灾难性遗忘,而且你不可能给每个人都搞一个模型,管理成本非常高。
第三种会更隐蔽一点,是把记忆放到隐变量、隐状态(latent state)里去。 包括行业中有些工作,把它放在 RNN 的一些参数中,或者放在中间推理过程的KV Cache 里。这条线相关的工作相对少一点,核心是训练难度比较高。

这几条路线过去其实都有。现在基本上所有工作主要集中在第一列,它的好处是很容易用,坏处是和模型没法端到端、也没法解决多跳。我们自己基本上是在第一条线和第三条线上都在做一些事情,待会我会分享。
05
EverOS:采用长期记忆四层架构
这里要介绍的第一个工作,是我们之前的工作EverMemOS,它是今年 ACL 2026 的一个主会论文。它是一个分层架构:记忆进来之后,开始做各种处理,包括topic切分、提取各种语义单元、构建语义单元之间的关系,再基于这些关系构建索引,然后在索引上做各种各样的记忆应用。
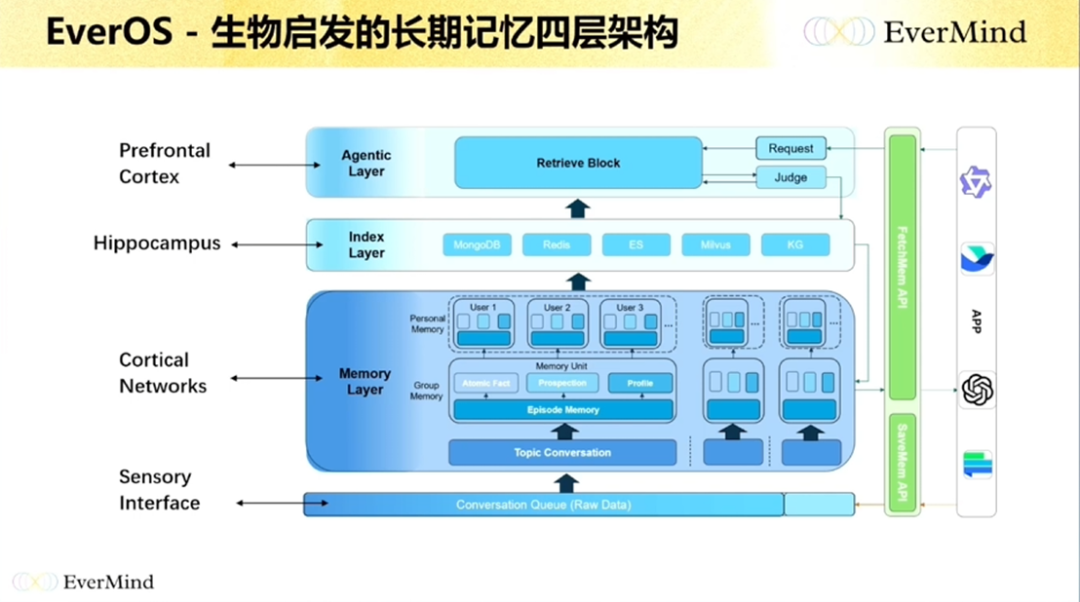
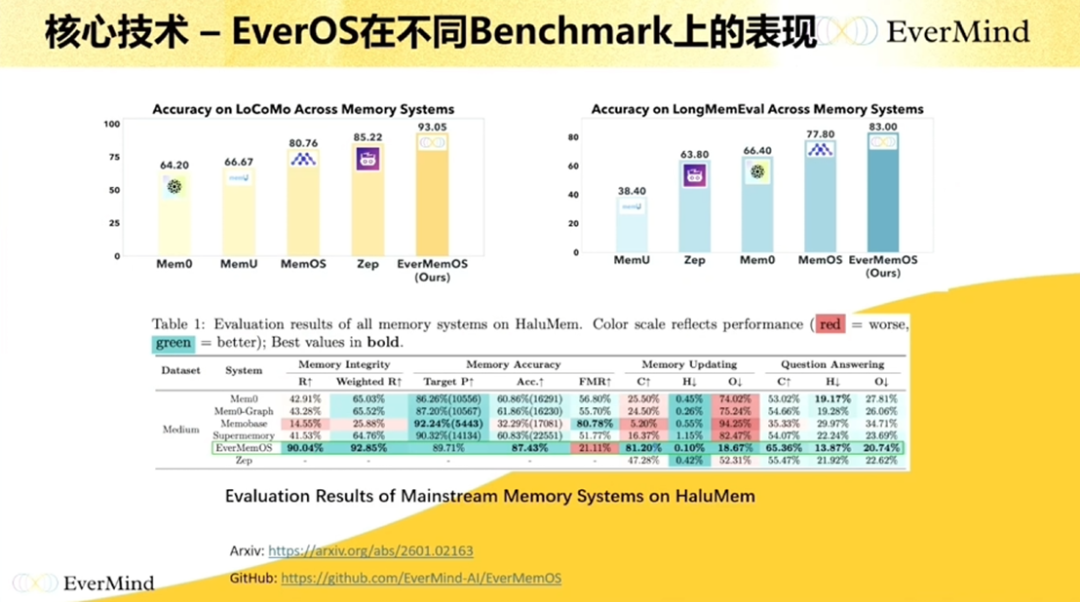
这是论文中的处理逻辑。这个工作基本上是行业中第一个在 LoCoMo 上做到 90 分以上的工作,去年 11 月时指标大概是 93 分,是一个非常高的指标,最近才有一些工作开始慢慢超过这个值。我觉得它最核心的是有一个比较好的框架设计,而且在语义提取、在关系构建上做得比较好。

还有一点,我觉得这篇文章最重要的是它在评测和分析上做得非常仔细。如果大家在学术界做和记忆有关的工作,其实可以参考它。评价不同的工作,一方面你可以比指标,另一方面很重要的是,在相同 Token 的用量下,你的准确率到底怎么样。在其他 Benchmark 上,它基本上表现也比较好。最近有些工作指标非常高,但其实没有那么严谨,包括算力使用等方面。总之,这是一个我觉得挺严谨的工作,感兴趣可以参考。
06
MSA 架构把上下文推到 1 亿 Token
第二个工作,我想介绍我们自己的 Memory Sparse Attention。这是一个模型侧的工作,也就是我刚才讲的第三条技术路线。大家可以看到,这是把通义千问(Qwen)模型做了非常底层修改的一个工作。

我们最核心的思路是这样:所谓记忆,狭义理解,就是用一段话拿着问题去库里找答案。如果把它简化,最初我们理解它有点像一种“单塔结构”——我拿着问题,去和每一个候选答案问大模型“这是不是我要找的信息”。这个工作基本上就是把这个想法做成了一个模型,所以它是一个很优雅的端到端模型。
这里我们大概做了九个月,是一个很难的工作。中间负责的那位同事,经常觉得这件事到底能不能做成;我就一直鼓励他说,这件事一定是对的,我们一定能做成。最后他确实做成了。它有几个关键技术:
一是改进的位置编码——因为它的目标是设计成一个支持很长上下文的端到端模型,最终在两张卡上可以支持到 1 亿Token,那么这么长的时候 position embedding 怎么设计就很关键;
二是用KV Cache 来记录中间状态,新的问题或新的记忆进来后,老的记忆不再重复运算,这样计算量才足够小,这里它做了一个很极致的压缩,大概压缩了几十倍;
三是设计了一个多轮机制,因为传统 RAG 比较难做多轮,通过多轮的方式去完成多跳问答。所以它在结构上做得非常好。
最终的指标是:当上下文长度从 16K 扩展到 1 亿 Token 时,它的准确率只下降了约 9%。这篇论文也是开源的。和行业中比较优秀的长上下文工作相比,很多方法在长程下降得很厉害;还有某个 Agent 框架,它比较慢,但效果也不错。我们能做到大概 1 亿这样的长度,包括“大海捞针”任务和通用问答,它都做得不错。

我们当时为什么想做这个?是因为我们有这样一些观点:如果你真想从学术或模型层面解决这个问题,比如你能不能支持到 1 亿长度——我觉得一两兆的长度是没意义的,现在模型基本都能做到;你能不能和主流模型兼容——如果是完全重新创新的架构,比如 Google 的一些框架虽然很好,但还很早期,很难和现在的大模型一起用,而这个工作是可以和大模型直接端到端放在一起用的;此外还有计算复杂度要好,能不能做 memory 的增删管理,能不能克服灾难性遗忘。综合来看,它相对来说是一个不错的工作,当然它也不完美。
此处现场播放了一段科普视频,要点如下:
24 小时不断学习直到一百岁,大脑最终能记住并随时调用的信息大约是 2 到 3 亿 Token;相比之下,主流 AI 的记性通常被锁死在 100 万以内,超过这个数就会开始“胡言乱语”。
如何让AI跨越这道鸿沟?EverMind 推出的 MSA 用三套绝招把 AI 的记忆极限直接轰到了 1 亿 Token。
第一,先扫目录再读正文。以前的AI遇到问题会傻傻的把整个图书馆翻个遍。MSA则是给精准定位最相关的十几本书,剩下99%的无关信息碰都不碰,因此处理长文本速度飞快;
第二,回归每本第一页。传统AI把所有文档从头编号到第几一页,训练时从没见过这么大的数字,推理时自然懵了。MSA 让每篇文档独立从第一页开始,不管图书馆多大,每本书看起来都是熟悉的长度;
第三,持续联想,有些问题需要串好几步才能回答,MSA不强求一次检索搞定,而就像人类回忆一样,每找到一条线索就以它为跳板继续往下找,直到答案浮出水面。
三招叠加,把上限扩大约 100 倍,还能保留 Transformer 架构、实现端到端持续进化;在 1 亿 Token 的极限测试下,准确率损耗不到 9%,而那些两千亿参数的顶级模型在同样长度下几乎全部“罢工”。
这个视频是我们公司另一个团队做的,他们做 AI 视频做得也非常好。
07
自我进化、开源平台与 Benchmark
另外,我想介绍我们最近在self-evolve上的一些进展。
我觉得行业里有一个很重要的点:随着用户不断使用,系统能不能变得越来越好。但现在其实非常缺少一个好的 Benchmark,所以我们首先建了一个 Benchmark,待会会讲。在这个Benchmark 上,我们尝试了一些策略。这些策略今天来看还比较早期、比较传统,但我们验证了一些关键想法:当你的训练集里有和测试集类似的任务时,让 AI 先在推理阶段跑一遍,它就能学到一些 skills 或 SOP ——也就是这类题该怎么做——然后会有非常显著的提升,绝对值基本能提高 40% 多。
把这些题全部混在一起后,让 AI 自己去决定怎么匹配。因为有时不一定能完全对得上,所以整体上会有损耗,但相对提升仍然比较可观。大家看那个绿色的字,最高的相对提升可能有两百多,有的是百分之几十。整个评测和方案我们都还在做,我自己觉得这也是未来 Agent 领域非常重要的一个方向。大家如果去看 Hermes,它的策略可能比这个还要更简单,没有经过比较严肃的评估和验证。

经过这一系列评测,我们得到了一些结论:对于一些密集型的、在实际中经常见到的任务,效果比较明显;小模型用了这样的策略之后,有些效果可能和大模型差不多;而且它不仅能提高成功率,还能减少轮数。由于我们这套策略对五类任务都是类似处理的,所以它是一个比较通用的方法。
我们也做了GitHub的开源版本,叫EverOS,还有一个云平台,两者机制基本一致。它支持Profile Memory——这个人到底是什么样子、目标是什么、偏好是什么;还有Episodic Memory,记录什么时间、什么地点发生了什么事这类事实性信息;我们还增加了一个 Forecast ,不仅判断当前事件的关联,还能预测它对未来有什么影响。此外是Agent Memory,我们在这块做得比较多、比较好。之前有些工作基本是用前面那套来管 Agent 的,其实不太理想,所以我们在 Agent Memory 上支持了一些新特性,包括多模态。从场景上讲,它适配 Chat、Enterprise 等场景,天然支持多人场景,也支持一些硬件,整个模式比较广。

下面再讲讲自我演化,这是其中一个比较重要的特性。在 Agent 的整个对话过程中,我们会对它进行分析,提取 case,一个任务进去,整个 trace 我们就认为是一个 case。我们会对 case 做聚类,聚完之后把相同的 case 总结成 skills,也就是对这样的应用场景该怎么做,并支持检索。新任务来了之后,它就可以在已有的、AI 自动生成的 skills 中检索、匹配,然后完成工作。

由于它整个是一个 Agent 系统,本质上是一种众包的方式:只要某类任务出现过,你就可以得到这样的经验,然后变得更好。所以这里既有Skills 的 memory,也有 Cases 的 memory,这些我们现在都已经原生支持。如果你做 Agent,在这个基础上继续做就好。另外,动态性也很重要,所以我们现在支持各种各样的文档类型,以及图片和其他格式;而且检索策略上也做得比较特殊,所以在准确性和精度上都做得不错。

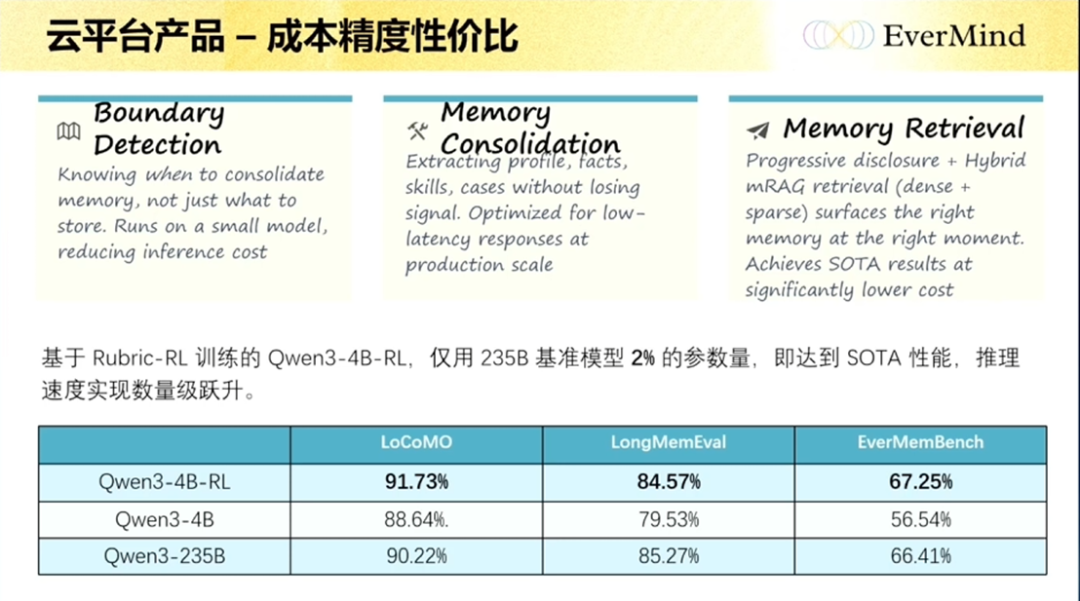
还有一点,我们也对模型做了极致优化。我们用一种 Rubric-RL 方法训练了一个 4B 模型,效果基本能比肩 235B 的千问通用模型,而参数量大概只有它的 2%。大家可以看这几个 Benchmark 的指标都挺不错,基本和那种特别大的模型相差一两个点,有的还更高一些,这也是我们一个比较特别的工作。
整体上它是开源的,云端机制和开源机制一致;你想本地部署也行,想用云上的也行,而且它还支持自我演化等特性。

我们也做了一些 Benchmark 来推动领域工作。
一个叫 EvoAgentBench,它不依赖长期记忆,评的是 OpenClaw 这类框架。我们设计了五类子任务,每类有几百道题,而且都划分好了,核心评的是你能不能自进化。它支持不同的智能体框架,也已经支持几种主要的自进化算法。
另一个叫EverMemBench,是我们做的长期记忆评测,分静态和动态。动态主要支持细粒度信息的召回,以及记忆的觉察和用户画像理解,把记忆分成了几步,并且支持训练集和测试集,所以你天然可以在上面做 RL 这些工作。

EvoAgentBench 我自己觉得是做得相对比较完整的一个工作,如果大家对自演化、或者对评估OpenClaw 这类框架感兴趣,可以去看看。

08
应用场景与展望
在场景上,我们最近也组织了一些 Hackathon,发动社区的力量去设想不同的场景,其中有些还蛮有趣的。比如虚拟陪伴、智能硬件,还有两个很温情的项目:一个是用记忆来帮助阿尔茨海默病患者提高生活质量;另一个是针对走失儿童——父母可能对孩子的过去有一些印象片段,孩子可能也对过去有一些记忆片段,通过这种方式把他们匹配起来。还有一个是多 Agent 协作写代码的项目。当时的一等奖,大家都觉得做得比较好,他们用记忆做了数据分析,核心就是能够持续演化和进步,这些都是非常有趣的项目。

最后我想说,我自己觉得今天的 Agent 远远没有到理想状态。虽然 Claude Code 这些工作已经很不错了,但距离我们终极的那个“AI 贾维斯”还很远。而在这里面,长期记忆以及基于长期记忆的主动性、自我进化、持续学习,一定是这个时代最重要的一些技术,需要我们持续攻关。我们一直也在这条路上,非常感谢大家关注我们的工作,后面可以共同交流,谢谢大家。
END
✦
✦
2026中国AI智能体大会
✦
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。










✦
✦
入群申请
✦

点击下方名片 即刻关注我们










