腾讯混元PhoneBuddy团队 投稿
量子位 | 公众号 QbitAI
过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。
模型已经能看懂手机截图、预测点击位置,甚至完成不少多步操作任务。
但从benchmark走向真实手机,问题会立刻变复杂:
真实App有账号状态、权限弹窗、网络波动和业务逻辑; 任务执行后还会产生真实副作用; Agent点到了页面,不代表任务真的完成; 说“完成了”,也不代表结果可验证。
因此,下一阶段的关键问题不只是“模型能不能拿更高分”,而是:
怎样训练出一个真实场景中可用的Phone-use Agent?
PhoneBuddy关注的正是这个问题。它想探究:
要训练这样的模型,RL环境到底应该怎么设计?是用最真实但难重置、难验证的真实App,还是用可控、可规模化但可能有gap的mock App?
腾讯混元Phone-use Agent团队给出的答案不是二选一,而是Real+Mock:
用真实App RL对齐真实手机执行,用PhoneWorld mock App RL提供可重置、可验证、可规模化的训练信号。

环境层:PhoneWorld[1]; 训练层:PhoneBuddy[2]; 执行层:PhoneHarness[3]; 边界层:PhonePrivacy[4]和PhoneSafety[5]。
Real-App Environment vs Mock-App Environment
要训练Phone-use Agent,最直接的选择是Real-app Environment。
它的优势很明显:足够真实。
真实App里有真实账号、真实页面、真实业务逻辑,也有真实的用户可见副作用。
Agent发消息,就是真的发出去;创建文档,就是真的生成文件;修改设置,就是真的改变设备状态。
这让Real-app Environment最接近最终部署场景。
但它的问题也同样明显:
响应慢:真实设备交互和rollout成本高; 难重置:一次操作就可能改变账号、缓存或服务端状态; 有风控:真实操作可能带来不可逆结果,探索空间受到限制。
另一种选择是Mock-app Environment。
它的优势正好相反:足够可控。
Mock App可以被反复重置,任务可以稳定复现,内部状态也更容易暴露出来。比如消息是否写入、收藏是否生效、文档是否创建,都可以通过规则或数据库直接检查。
这对RL非常关键,因为RL不只是需要更多交互数据,还需要稳定的环境和可靠的reward。
但Mock-app Environment也有天然风险:
不够真实:页面结构和交互逻辑可能过于简化; 行为有gap:真实App中的弹窗、权限、网络波动、业务规则很难完全复现; 任务覆盖有限:如果mock App没覆盖真实使用中的关键流程,训练收益就会受限。

这就形成了Phone-use Agent训练中的关键矛盾:
Real-app Environment更真实,但并不可控;Mock-app Environment更可训练,但可能不够真实。
因此,要训练一个真实场景中可用的Phone-use Agent,问题不只是“用更多数据”或者“换更大模型”。
更关键的是:RL的训练环境到底应该怎么设计?
PhoneBuddy怎么做?
PhoneBuddy的核心思路很直接:
既然Real-app Environment和Mock-app Environment各有优缺点,那就不要二选一,而是系统性研究它们应该如何组合。
具体来说,PhoneBuddy把训练拆成两个阶段。
第一阶段是shared SFT。
模型先同时学习来自真实App和mock App的操作轨迹,获得一个共同的Phone-use初始能力。
这个阶段的目标不是区分哪种环境更好,而是让模型先学会统一的手机操作格式:
看屏幕、理解任务、预测下一步动作。
第二阶段是RL training。
从同一个SFT模型出发,PhoneBuddy再比较不同的RL环境选择:
Real-App Environment
Agent直接运行在真实手机和真实App上。它面对的是真实页面、真实账号状态、真实业务逻辑和真实用户可见的副作用。这类环境的价值在于:它最接近最终部署场景。
Real-App+Mock-App Environment
在Real-App的基础上,进一步加入混元自建的Mock-App,PhoneWorld。PhoneWorld不是普通的静态mock页面,而是从真实GUI使用结构中重建出来的可运行Android App。
它保留真实App中对训练最重要的部分:页面结构、跳转关系、可交互元素、可变状态和任务verifier。这类环境的价值在于:它更适合规模化可验证的RL。

PhoneBuddy的目的不是只做模型,更是在研究训练recipe
PhoneBuddy的重点不只是发布一个4B模型,它真正研究的是一套训练recipe:
先用真实App+mock App轨迹做SFT让模型具备基础能力,要训练真实可用的Phone-use Agent,RL的环境应该怎么选?
这套recipe的意义在于,它把真实世界和可验证世界放到了同一个训练框架里。
Real-App让模型接近最终使用场景。 Mock-App 让训练可以更稳定、更便宜、更容易scale。
因此,PhoneBuddy的方法可以概括成一句话:
用真实环境保证方向,用可验证环境扩大训练规模。
怎么评测真实可用?
为了验证PhoneBuddy是否真的提升了手机任务完成能力,论文没有只看离线动作预测,而是重点做了真实手机任务评测。评测包含两部分:
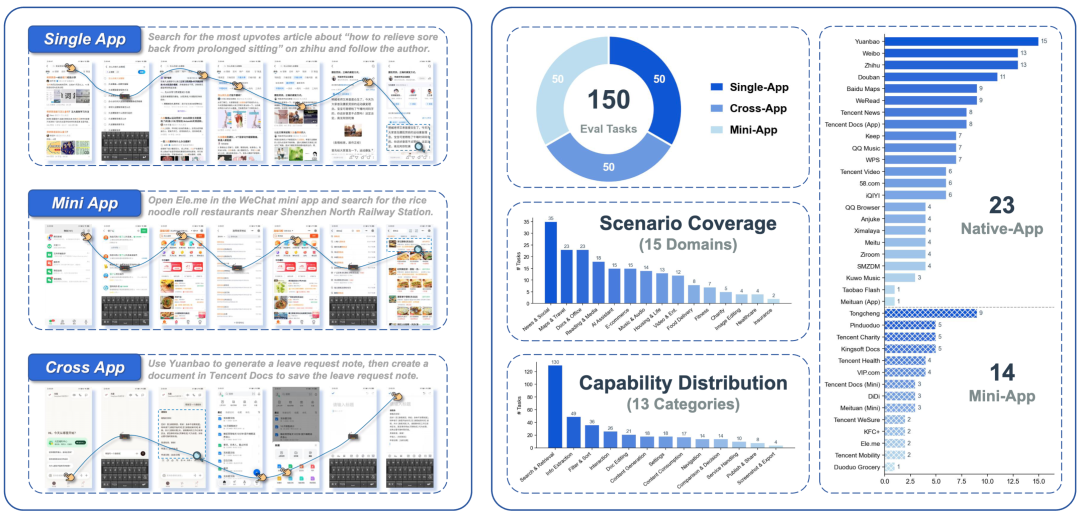
第一部分是150个真机人工评测任务。
这些任务覆盖三类真实手机场景,每类任务50个:
Single-App Tasks:在单个原生App中完成任务; Cross-App Tasks:跨多个App完成信息传递或流程执行; WeChat Mini-App Tasks:在微信小程序生态中完成任务。
第二部分是AndroidWorld。
它是一个常用的Android Agent评测环境,用来观察模型在更标准化benchmark上的表现。
这套评测的关键是:只看任务是否真的完成。
不是模型有没有给出看起来合理的动作,也不是最后页面看起来像不像成功,而是任务是否被完整执行。
这也和PhoneBuddy的目标一致:训练一个真实可用的Phone-use Agent,而不是只优化下一步点击。
Real+Mock带来了稳定提升
实验最核心的对比,是三种训练方式:
PhoneBuddy-4B-SFT:只做监督微调; PhoneBuddy-4B-Real:在真实App环境中继续做RL; PhoneBuddy-4B-Real+Mock:在真实App和PhoneWorld mock App中做混合RL。

结果非常直接。
在Single-App和Mini-App上:
PhoneBuddy-4B-SFT:34.0 / 48.0 PhoneBuddy-4B-Real:54.0 / 48.0 PhoneBuddy-4B-Real+Mock:62.0 / 56.0
在AndroidWorld上,这个趋势更明显:
PhoneBuddy-4B-SFT:60.3 PhoneBuddy-4B-Real:77.2 PhoneBuddy-4B-Real+Mock:83.2
这说明mock App并不是只能提升mock环境里的表现,尤其是在AndroidWorld上的结果,展现了Mock-App environment在OOD场景上的效果。
真实App RL让模型更贴近真实执行,PhoneWorld mock App RL让训练获得更多可验证反馈。
多项任务超过GPT-5.4
PhoneBuddy-4B-Real+Mock也和多个强闭源模型做了比较。
结果中最吸引人的一点是:
这个4B的PhoneBuddy模型,在多项任务设置上超过了GPT-5.4。
Single-App:62.0% vs GPT-5.4的50.0% WeChat Mini-App:56.0% vs GPT-5.4的40.0% AndroidWorld:83.2% vs GPT-5.4的70.7% 平均分:54.8% vs GPT-5.4的48.2%
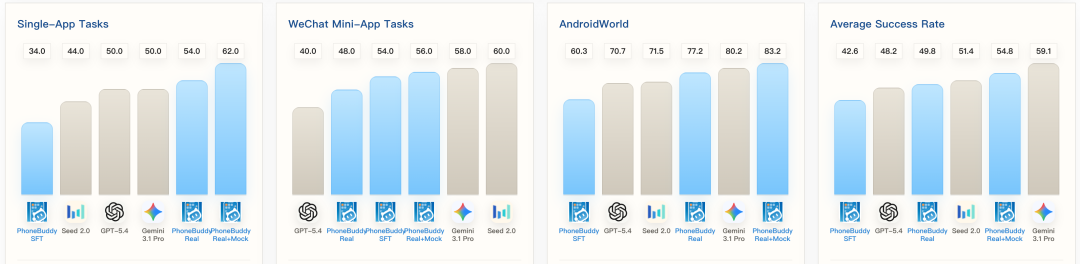
这并不是说PhoneBuddy已经全面超过闭源大模型,Gemini 3.1 Pro的整体平均分仍然更高,但这个结果说明了一件重要的事:
Phone-use Agent的能力,不只取决于模型有多大,也取决于它是在什么环境里训练出来的。
一个4B级开放模型,只要训练环境设计得足够贴近真实任务,也能在部分真实手机场景中展现出很强的竞争力。
两个case:从“看起来完成”到“真的完成”
论文中给了两个很直观的案例。
第一个是约束跟随。
任务要求Agent在微信小程序“同程旅行”里,搜索上海迪士尼附近的平价酒店。
PhoneBuddy-4B-SFT能走到酒店搜索页面,但没有真正应用预算限制;PhoneBuddy-4B-Real+Mock则继续进入筛选界面,把预算降到150元。
也就是说,它不只是“搜到了酒店”,而是记住并执行了用户的约束。
第二个是信息转移。
任务要求Agent先用元宝生成请假条,再在腾讯文档中新建文档保存。
PhoneBuddy-4B-SFT没有复制元宝生成的内容,创建文档时误用了剪贴板里的旧内容;PhoneBuddy-4B-Real+Mock则正确复制请假条,并粘贴到新文档中。
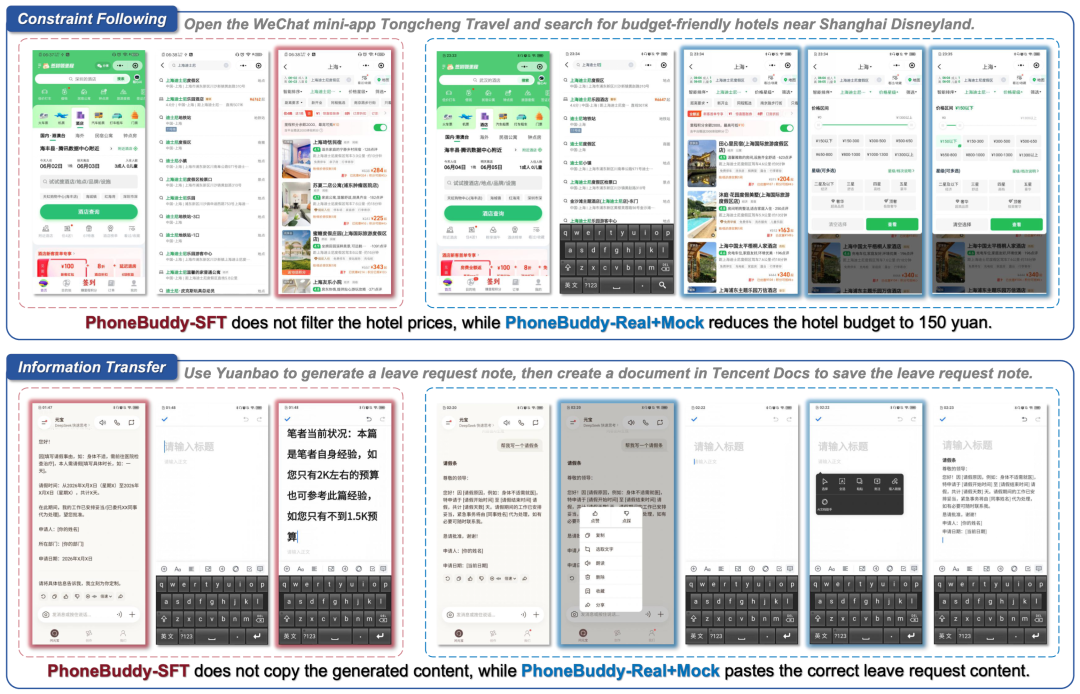
这说明,Real+Mock训练提升的不只是点击准确率,而是更接近真实使用的能力:
保留任务约束,传递中间信息,并把任务真正做完整。
不只是PhoneBuddy:混元一次完整发布5篇Phone Agent工作
PhoneBuddy当然是这次最直观的结果锚点,但它并不是一篇孤立的模型论文。
围绕Phone-use Agent,混元这次完整发布了5个彼此衔接的研究工作,系统覆盖环境、训练、执行、安全与隐私,也第一次把这条研究线比较完整地呈现出来。
这5篇工作共同回答的,其实是同一个问题:
怎样让Phone-use Agent从benchmark走向真实可用?
如果把真实可用的Phone-use Agent看成一个完整系统,那么只做模型远远不够。
环境决定能否大规模训练和评测,训练决定模型能否学到真实可用的策略,执行层决定能力能否稳定落到真机,安全与隐私则决定系统能否真正进入用户场景。
沿着这条线看,5篇工作的分工就很清楚了:
PhoneWorld[1]:环境层
构建可运行、可重置、可验证的mock App环境,让Agent拥有更多接近真实手机使用的世界去训练和评测。
PhoneBuddy[2]:训练层
研究如何把真实App和PhoneWorld mock App放进同一条训练闭环,让Phone-use Agent不只是会预测动作,而是在真实任务中提升完成率。
PhoneHarness[3]:执行层
研究模型如何真正接入手机运行时,如何组织GUI、CLI、MCP等不同执行方式,让模型输出变成可控、可追踪的真实操作。
PhonePrivacy[4]/PhoneSafety[5]:边界层
研究当Agent真的能操作手机之后,如何系统评估隐私风险、安全风险以及实际部署边界。
换句话说,PhoneWorld解决“在哪里训”,PhoneBuddy解决“怎么训模型”,PhoneHarness解决“怎么把能力落到执行”,PhonePrivacy与PhoneSafety解决“什么能做、什么不能做”。
从这个意义上说,PhoneBuddy是这条研究线中的训练层,也是第一次把前面几层能力汇总到真实手机任务结果上的关键一环。
它说明,要让 AI 真正会用手机,不能只依赖更大的模型,还需要更真实的环境、更有效的训练、更可靠的执行系统,以及更清晰的安全边界。
当然,这条路线还没有走到终点。
跨App长程任务仍然困难,复杂信息传递、中间状态验证、运行时协调都还有很大提升空间。
但这恰恰也指向了下一阶段的方向:
未来的Phone-use Agent,不会只是一个模型,而会是一整套从环境构建、模型训练、运行执行到安全评估的完整系统。
项目主页:https://phonebuddyai.github.io/
论文链接:https://arxiv.org/abs/2606.23049
GitHub链接:https://phonebuddyai.github.io/assets/paper.pdf
HuggingFace链接:https://huggingface.co/PhoneBuddyAI/PhoneBuddy-4B
[1]PhoneWorld: Scaling Phone-Use Agent Environments, https://arxiv.org/abs/2605.29486
[2]PhoneBuddy: Training Open Models for Agentic Phone Use,https://phonebuddyai.github.io/
[3]PhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions,https://phoneharness.github.io/
[4]Do Phone-Use Agents Respect Your Privacy ,https://freedomintelligence.github.io/MyPhoneBench/
[5]Safe, or Simply Incapable? Rethinking Safety Evaluation for Phone-Use Agents,https://arxiv.org/abs/2605.07630
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
【学术投稿】请在工作日发送邮件至:ai@qbitai.com,标题注明【投稿】,并告诉我们:你是谁,从哪来,投稿内容附上项目/主页链接,以及联系方式。
🌟 点亮星标 🌟










