衡宇 发自 深圳前海
量子位 | 公众号 QbitAI
一家刚完成10亿元A轮融资的具身公司,是这么定义具身标准数据格式的:
Object Trajectory。
说人话,就是用连续3D点云去刻画物体在时间维度上的变化过程。
如此一来,需要关注的焦点就从“机器人怎么动”,变成了“物体本身发生了什么变化,包括位置移动、姿态变化,以及在复杂操作中的接触关系甚至形变过程”。
在这个逻辑下,作为一种统一的物体级状态表示,Object Trajectory就被定义为了“具身智能的token”。

创始人兼CEO说,Object这个词本身有“物体”和“目标”两种意思,所以能用它精确描述机器人本体跟物体要发生什么样的交互、要完成什么样的物体运动状态的变化
他还介绍了提出这一“具身token”的原因。
RoboScience认为,具身智能真正缺的不是动作数据,而是一种能同时表达认知与物理执行的中间语言,“需要一种能够同时覆盖认知过程与物理执行过程的中间表达,而Object Trajectory就是这个中间层”。
感觉……这家公司想做的事情大概是,先把世界压缩成“物体级动态状态”,再去做执行。
忘了展开介绍,这家公司叫RoboScience,成立于2024年。
CEO田野本科毕业于中国科学技术大学物理系(专业第一),硕士毕业于斯坦福大学AI Lab,师从AI大牛吴恩达。
2017年硕士毕业后,他加入苹果总部,在苹果工作了约7年时间,后来成为苹果总部最年轻的主任工程师之一,并担任AI平台技术负责人。
在苹果期间,他主导构建了苹果的机器学习平台,支撑了相机、Siri、Apple Intelligence等。
首席科学家邵林为新加坡国立大学计算机系助理教授,师从图灵奖得主、斯坦福计算机科学系讲席教授Leonidas J. Guibas(与Sedgewic共同发明红黑树)和斯坦福机器人实验室的核心负责人之一Jeannette Bohg。
其团队获ICRA 2025最佳论文奖,又在ICRA 2026获最佳论文奖提名。
上个月(5月),这家公司对外披露了10亿元A轮融资,是该月该赛道上曝光的最大一笔。
Object Trajectory有啥用?
从RoboScience的技术框架出发,Object Trajectory对应的是具身token的定义,也对应模型处理世界的基本单位。
创始人兼CEO田野在线下技术分享中谈到,当前具身系统面临的两个主要问题,一个来自机器人本体结构差异,另一个来自物体交互过程中的物理规律表达。
这两个问题通常被分别处理,然后在新的表示方式中被收敛到同一空间。
但RoboScience希望自己做出来的具身世界模型和硬件解耦,不能通过模仿学习跟硬件强绑定(事实上也确实这么做了)。
So,Object Trajectory出现了。
主打起到一个提供统一空间的表达方式的作用。

它的作用首先体现在对任务的重新整理上。
无论是抓取、叠衣服还是家具拼装,在这一表示方式下都会被转写成同一种结构问题,即物体从初始状态到目标状态的变化过程。
其次是对差异性的处理方式发生变化。
一般来说,机器人本体差异、物体类型差异、任务差异通常分别建模。
而有了Object Trajectory,这三类差异会被压缩进同一个表示空间中处理,系统不再依赖具体硬件结构或任务模板。
也就是说机器人本体差异被从建模层移出,进入执行层处理。
第三个变化来自学习对象本身。
田野表示,“你人去拿也可以,夹爪去拿也可以,这些都不重要”,系统关注的是物体发生的变化过程。

此“点云”非彼“点云”
虽然叫做点云,但Object Trajectory涉及的“点云”是一种数学层面的抽象表征,与深度相机直接采集到的点云数据并不一一对应。
田野告诉量子位,深度相机产生的点云只是数据获取方式之一,而RoboScience使用的物体点云“本质上是一个更高层级的结构化表示”。
Object Trajectory框架下,具身世界模型在生成物体运动轨迹时,并不只是对可观测部分进行补全,而是可以生成完整物体的三维点云,包括被遮挡区域的结构信息(这实际上是一种用模型能力弥补传感器不完备性的方式)。
好处是研究团队可以直接向操作模型提供完整的物体级运动轨迹描述。
这也是该表征作为“接口”的核心价值。
它不依赖于单一传感器视角,也不局限于局部观测信息,因此像遮挡、噪点等更多属于传感器感知过程中的数据缺陷问题,不会限制表征本身。

在能力层面,这种3D物体运动轨迹还带来了两个进一步变化。
其一是泛化方式的改变。
系统不再学习人类动作的逐帧模仿,而是先定义物体状态应当如何变化,再由机器人反推自身动作,实现从动作模仿到目标驱动的转变。
其二是系统结构的解耦。
通过这一中间表示,将感知、控制以及数据来源分离,从而为模型扩展提供更强的scaling空间。
它将如何改变具身智能的技术路线?
Object Trajectory的引入,首先改变的是学习对象的定义。
数据不再以图像或动作作为基本单位,而是统一为物体在三维空间中的连续状态轨迹,模型的目标也从识别视觉内容,转向建模物体状态随时间的演化过程。
这一变化进一步重构了数据体系本身。
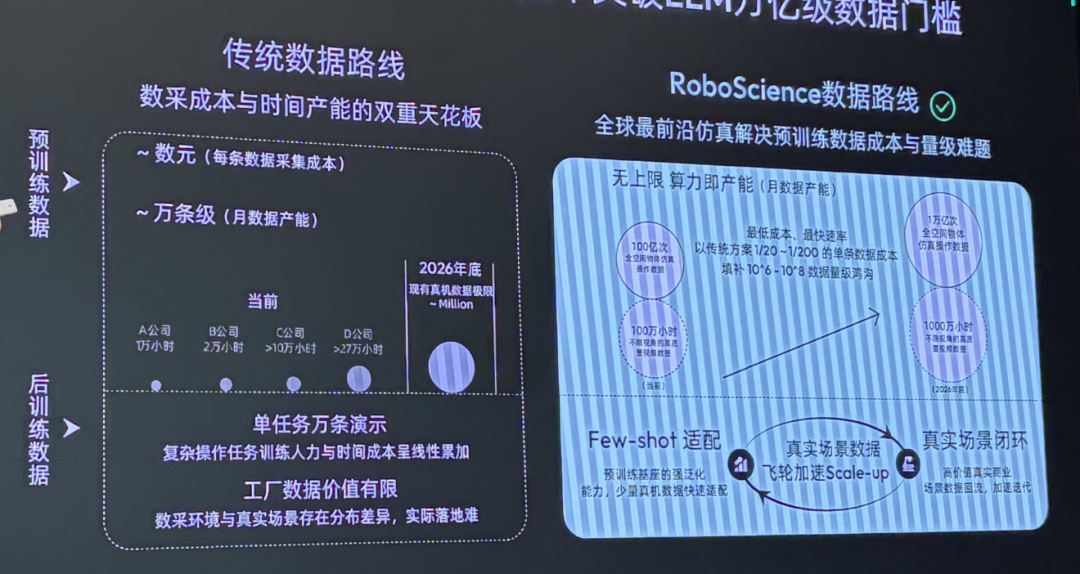
众所周知,具身智能领域目前普遍对数据很头疼,大家都在讲数据采集的故事……
在预训练阶段,依赖真机采集的方案月产能仅为万条级,远不能满足大模型对数据规模的指数级需求;在后训练阶段,单任务的复杂操作演示需要上万条人工标注数据,人力与时间成本随任务数量线性累加。

由于Object Trajectory做了中间层,学习对象从动作或图像,变成了物体在三维空间中的连续状态变化,就不存在对单一数据类型的依赖了。
RoboScience倒是也没纸上谈兵,用自家融合了“具身世界模型”和“通用操作模型”的自研Visics大模型为例,数据源就采用了视频和仿真两种方式。
一边,具身世界模型的预训练基于海量互联网视频数据。
通过全自动数据标注及清洗pipeline,团队积累了数百万小时以物体为中心的高维多模态操作相关数据集(数千万video clips),目标在2026年构建上千万小时的数据集。
另一边,作为通用操作模型学习物理规律的基础,RoboScience通过自研多模态物理引擎RoboMirage积累了数百亿次高质量manipulation操作轨迹数据集。
联合创始人兼执行总裁汪涛放话,年内目标是构建超过1T高质量manipulation操作轨迹数据集(1万亿次全空间物体的manipulation操作轨迹数据)。
汪涛表示,这一数据体系有效降低了对昂贵真机数据的依赖。
从成本上来说,单条数据的获取成本降至传统方案的1/20~1/200;从数量上来说,以每周数十万小时的增速持续扩展。
 △这个摩尔纹dbq,但我真的立竭了
△这个摩尔纹dbq,但我真的立竭了
田野称,Object Trajectory更进一步的外部价值在于作为一种统一的任务表达方式,使模型能够面向不同类型机器人传递明确的目标信息,并指导其完成相应操作。
从这一角度看,该团队希望构建的是一套跨本体的通用具身模型,使其能够适配多种形态的机器人系统,并为其提供统一的操作能力接口。
因此,这一“Token”式的数据结构同时承担了技术验证与产业扩展的双重功能,既服务于内部模型训练闭环,也指向跨机器人平台的通用能力输出。
Final Note
Object Trajectory提供了一种不同于主流路径的建模方式。
该团队称之为VLOA(Vision-Language-Object-Action)架构,现在已经实现了“指导任意机器人、操作任意物体、完成任意任务”三个维度的泛化。

不过,这条由RoboScience提出的路线目前仍处于早期的、非共识的阶段。
但它把具身学习的问题重新放回到物体状态变化这一层描述上。
故以此记录,提供给小伙伴们思考和分享~
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟










