6月中旬,燧原科技科创板IPO过会并提交注册,拟募资60亿元。不到两周,又一家国产AI芯片企业传来上市喜讯——北京清微智能完成创业板上市辅导,正式进入辅导验收阶段。若顺利过会,清微智能将成为国内"可重构芯片第一股",也是非GPGPU架构芯片领域首个叩开A股大门的企业。
国产AI芯片的上市潮正在加速。摩尔线程、沐曦股份已登陆科创板,壁仞科技、天数挂牌港股,燧原科技距离敲钟只差临门一脚。清微智能的进场,让资本市场对国产算力的审视维度,从"能不能做GPU"扩展到了"除了GPU,还有什么新可能"。

清微智能成立于2018年,与燧原科技同年起步,但两者从第一天就选择完全不同的技术路线。燧原科技走的是DSA领域专用架构,清微智能押注的是RPU可重构数据流架构。这两条路线都不追随英伟达的GPGPU生态,也都不兼容CUDA,却在底层逻辑上存在本质差异。
燧原科技的思路,是把AI计算中最吃算力的矩阵乘法、卷积运算等核心操作,以硬件方式"硬化"到芯片里。其自研的GCU-CARE加速计算单元和GCU-LARE片间互联技术,历经四代迭代,将计算、存储、互联的优化特性直接固化在硅片层面。这种设计的好处是极致能效比——在推理场景下,每瓦算力可以做得非常漂亮。代价是通用性被压缩,芯片出厂后硬件功能基本定型,面对全新算法结构时灵活性有限。燧原的应对方式是软件补位,自研"驭算TopsRider"全栈平台,用编译器和算子库去弥合硬件的刚性。

清微智能的打法则更像"芯片界的变形金刚"。它的RPU架构基于清华大学近二十年的可重构计算研究,核心是可重构数据流(CGRA)技术。芯片上的计算单元并非固定连接,而是通过电子"道岔"在纳秒级时间内动态重组。今天跑Transformer推理,硬件通路就搭成Transformer的形状;明天切换去跑CNN视觉模型,同一颗芯片立刻重构出另一套计算拓扑。这种"软件定义硬件"的能力,让RPU既保留了接近ASIC的能效,又具备了GPU级别的任务切换灵活性。
两种架构在集群扩展层面的差异同样明显。燧原科技的云燧智算机采用传统的高速交换机互联,节点内通过GCU-LARE实现近1TB/s带宽,跨节点走200G RDMA,属于典型的scale-out思路。清微智能的TX81则走了另一条路——C2C Mesh算力网格让芯片、服务器、甚至机柜之间可以直接点对点通信,不需要交换机中转。这意味着在构建千卡集群时,清微的方案可以省掉一层网络设备,延迟和成本都有优势。

从商业落地看,燧原科技已经证明了DSA在大规模推理市场的可行性。2025年其AI加速卡出货6.6万张,营收9.9亿元,在国产厂商中位居前列。但高度依赖单一客户也是事实——腾讯贡献了超过八成的收入,这种深度绑定既是护城河,也是风险点。清微智能的出货量更为惊人,累计已突破3000万颗,不过其中大部分是面向边缘端的TX5系列;云端TX8系列正在全国十余座千卡智算中心铺开,今年4月还完成了DeepSeek大模型的DAY0适配。
软件生态是两条路线都必须面对的硬仗。燧原科技选择自建"驭算"平台,从驱动、编译器到算子库全部自研,目前已支持PyTorch、TensorFlow等主流框架和1600余个深度优化算子。清微智能则拥抱了开源路线,其FlagOS适配规模在非GPU架构中与华为昇腾并列前二,这意味着基于FlagOS开发的AI应用可以无缝迁移到清微芯片上运行。

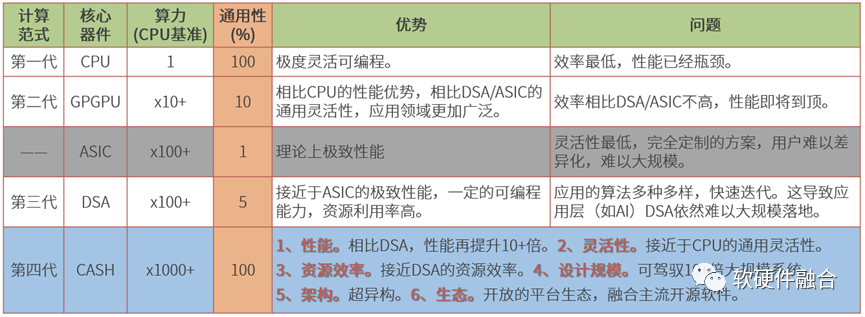
如果把国产AI芯片的版图摊开,目前大致呈现三足鼎立的格局。以摩尔线程、壁仞科技、沐曦股份为代表的GPGPU派,走的是兼容CUDA、通用性优先的路线;以燧原科技、寒武纪为代表的DSA派,在特定场景里把能效比做到极致;以清微智能为代表的可重构数据流派,则试图在灵活性和效率之间找到动态平衡点。
三派之间没有绝对的优劣,只有场景适配度的差异——训练需要通用,推理需要性价比,边缘需要低功耗,而可重构想要通吃。
燧原科技和清微智能的相继上市,传递出一个清晰的信号:国产AI芯片的叙事已经从“替代英伟达”的单一剧本,转向了多元架构并存的新阶段。DSA和RPU都不追求在CUDA生态里正面对抗,而是用架构本身的差异化,去切分推理、边缘、特定模型等细分市场。当资本市场开始为"非GPU"路线定价,中国AI芯片产业才算真正走出了自己的节奏。
清微智能的招股书尚未披露,但参考燧原科技60亿的募资规模和180亿的估值,这家“可重构芯片第一股”的IPO体量同样值得期待。无论最终定价如何,两家企业登陆二级市场后,都将接受更严苛的审视——技术路线能否持续迭代,商业化订单能否兑现,软件生态能否真正闭环。这些问题的答案,将决定国产AI芯片是停留在概念层,还是真正跑进主流数据中心。
END


往期精选:

请点下【♡】给小编加鸡腿