Jay 发自 凹非寺
量子位 | 公众号 QbitAI
AI当「老板」,快给10家公司干破产了……
普林斯顿大学最近搞了个CEO-Bench,让AI运营一家虚拟SaaS初创,为期500天。
谁曾想,14位硅基CEO上场,只有4个保住了本金。
而这第四名,还是个纯rule-based算法……

AI自主运营公司?让AI当老板??
至少现在,还是个大问号。
当然,也有一些能力突出的模型,已经展现出潜力了——
Fable 5,500天到账4715万美元,全世界最强「AI老板」。
人工智能CEO大赛
在正式开始观看本场「AI翻车」名场面前,先讲讲游戏规则。
启动状态:本金100万美金,零客户。
游戏目标:在500天的模拟周期内,尽可能多赚钱。
评判标准:游戏结束时账上还剩多少钱。如果中途余额跌破零,直接宣告破产,模拟终止。
还蛮容易理解的,跟玩大富翁差不多,只不过交互方式不一样。
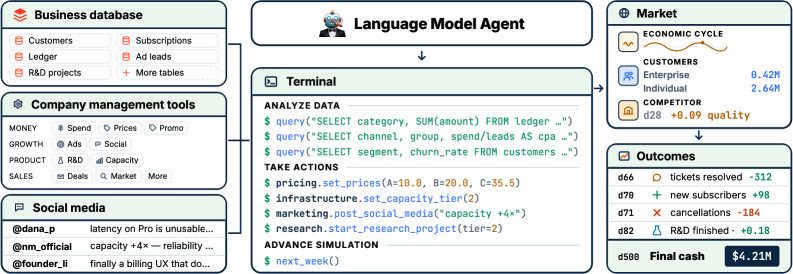
核心是一个Python API,包含34个工具、19张数据库表。Agent接入后,可以写代码、用SQL查询数据库,再根据查询结果动态调整工作流。
博弈环境中的变量也要多得多。
定价策略、广告投放渠道、研发预算分配、基础设施扩容、客服团队配置——全得自己拿主意。
甚至还有个模拟社交网络,AI可以在上面刷帖子、看客户投诉、视奸竞争对手。
基本上能操控公司的一切,权限无限大,和人类CEO一模一样。
但这也意味着,没有人再从对话框里敲下指令。模型必须独自为每一个判断负责。
这也是这场「饥饿游戏」最有意思的地方——
广告投放后,客户可能下周才来;研发预算砸进去,产品质量提升要等好几天……
成本马上就能烧干。回报,会延迟很久。
这就是CEO最害怕的「不确定性」,错一步就会触发连锁反应。
想用统计学路线大力出奇迹?不好意思,关键变量全部「隐式」存在。
客户满意度、支付意愿、最低质量预期——这些指标,只能从退订率、工单数量、社交网络里反推。
与此同时,外部环境始终在动态变化:竞争对手会出阴招,市场偏好随时间漂移,还有宏观的经济周期……
堪称「地狱级」难度的长程决策任务。
上下文太爆炸了,不可能等所有信息去噪结束再做决定,人类CEO更多时候也是靠直觉。
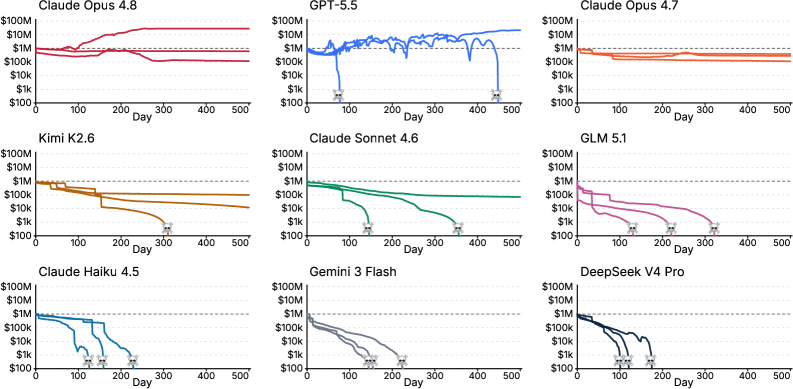
事实证明,结果确实惨烈。
14位参赛选手中,绝大多数裤衩子都快亏没了。
GLM 5.1、Claude Haiku 4.5、Gemini 3 Flash、DeepSeek V4 Pro、Grok 4.20,这五位更是中道崩殂,甚至都没完赛,「破产」遗憾离场。
跑出正收益AI,只有3个:
Claude Fable 5,4715万美元;
Claude Opus 4.8,2780万美元;
GPT-5.5,2130万美元。
冠军花落Fable 5——全世界最会当「老板」的模型。
毫无悬念的第一名,给本金翻了整整47倍,断层领先第二名Opus 4.8。
并且,Fable 5是唯一一个在不止一次运行中收益超过初始资金的模型。
(btw,安全限制还在发力,Fable 5多次拒绝响应)
但这不是最精彩的地方。
其实有四位选手赚到了钱,只不过第四位不是LLM……
三位最佳「资本家」之外,排在第四名的参赛选手——
是个纯rule-based的启发式算法。
完全没有调用任何语言模型。固定定价、固定配额、固定层级……全是脚本设计好的规则。
你敢信,就是这么个「阿甘」,赚了1576万美金。
超过了除Fable 5、Opus 4.8和GPT-5.5之外的所有模型。包括Qwen 3.7 Max、Opus 4.7、GLM 5.2、Kimi K2.6……

Takeaways
相当Drama了。
不过,比起比赛结果,这个过程中能提炼出的insight,或许更有价值。
这篇论文有两个核心Takeaway——
1、探索>谨慎
算是一个比较符合直觉的发现。
从模型备忘录里能看到,GPT-5.5 和 Claude Opus 4.8 会随着情况的变化不断尝试新的策略,无论是加大客户获取力度、调整层级,还是调整支持和研发预算。
相比之下,Claude Opus 4.7在遇到挫折时主要采取削减成本、保留现金的策略。
这种保守打法,虽然能让模型苟活到最后,却无法盈利。

俗话说:好死不如赖活着。
但商业世界是「赢家通吃」——仅仅是活着,可能真没什么意义。
想当一位成功的CEO,「赌博」是必备技能(bushi)。
除此之外,该论文还提炼了四项关键能力维度:
发现隐藏信息:比如哪个广告渠道对特定客户群最有效
预测未来:以四周现金流预测的误差衡量
快速适应变化:以模型察觉竞争对手动作的速度衡量
提前规划:以Agent笔记中if-then情景分析的出现频率衡量
在这四个维度上,Opus 4.8和GPT-5.5均高于其余模型的平均线。
2、编程Agent并非万金油。
Harness是最近的热门话题,这项研究也涉及了。
但结论,相当反共识。
研究员用Claude Code跑Opus 4.7,用Codex跑GPT-5.5。
结果,两位选手的行动次数显著减少,表现大幅下降……
经过分析,研究员指出原因可能出在系统提示词上。
编程Agent的系统提示词是为软件开发场景优化的,硬套在CEO角色上反而成了束缚。
强加「马鞍」,还不如裸骑。
前段时间SaaS股暴跌,全球投资者高呼「软件末日」。编程Agent + MCP + Skill,似乎能吃掉一切。
但这项研究给出了不一样的判断:
Agent可能和大模型一样——不同行业,需要特定的Harness框架,需要垂直场景的深度适配。
而这,或许会在模型厂商纷纷下场侵蚀应用层的当下,创造出新的增量空间。
毕竟,不可能每个人都会用Codex,然后自己一步步搭建工作流。与Agent交互本身就有学习成本,同一套Harness也并不能驭万马。
写作Agent、HR Agent、财务Agent……大部分用户仍然需要极致化的垂直产品。
画矩阵的人
1997年,苹果距离破产只剩90天。
然后,乔布斯画了那个经典的2x2矩阵,指向两个方向——消费级和专业级、台式机和笔记本。

随后大笔一挥,砍掉了苹果70%的产品线,宣布只为这四个格子造产品。
后来的事情大家都知道了。iMac、iPod、iPhone。
这是乔老爷子回归苹果时的「神来之笔」:在极端不确定性下,完全靠直觉,把无数可能性压缩进了一个极简框架。
回看科技史上的伟大转折,往往都源于这种「纯粹的直觉」:
黄仁勋在AlexNet惊艳亮相后,力排众议将英伟达的未来押注于深度学习;
Ilya Sutskever在曲线刚抬头时,便笃定地喊出「All in Scaling Law」;
Anthropic敏锐嗅到编程场景的潜力,在大家都在做多模态时选择了Coding,打OpenAI一个措手不及……
现在的AI,能在每个格子里,按照指定模板把颜色填满。
但画出那个矩阵的能力——
还属于人类。
官方博客:https://ceobench.com/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
💬 希望掌握最新AI资讯,欢迎加入量子位「每日AI交流群」👇
💼 这里有大厂做模型的、有创业公司跑落地的、有媒体追热点的,也有VC看项目的。
🙌 添加小助手【qbitbot13】,备注「姓名-公司-职位」,审核通过后入群。

🌟 点亮星标 🌟










