
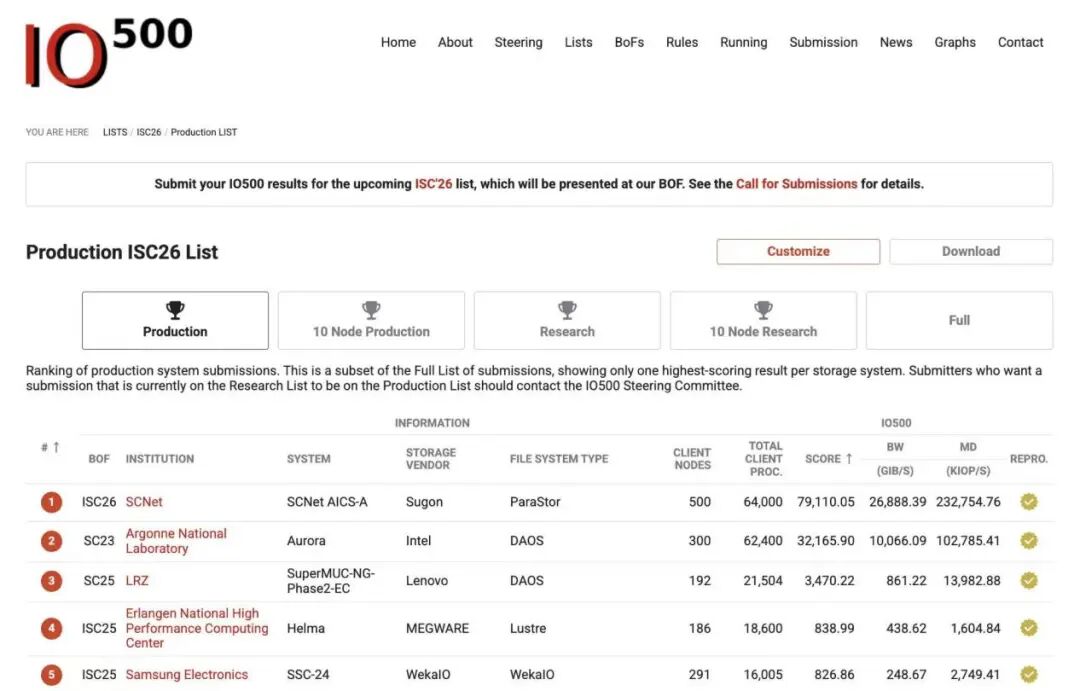
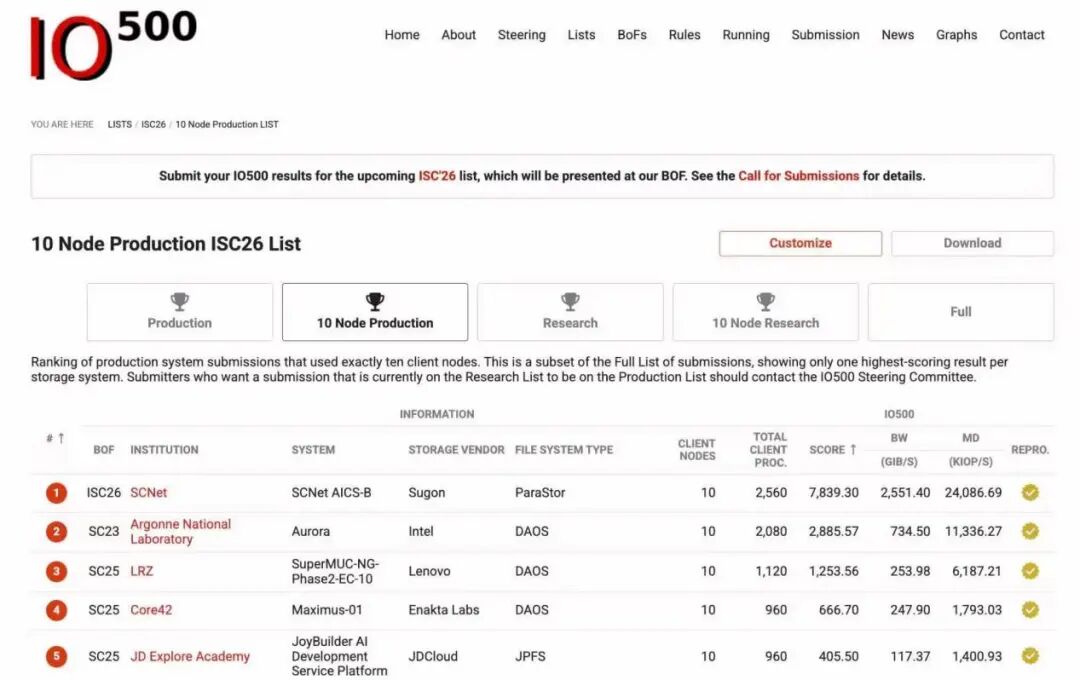
2026年6月24日,中国存储在高性能计算与 AI 存储领域迎来了一次里程碑式的技术亮剑。在最新发布的国际权威存储排行榜 IO500 中,中科曙光凭借全国产自研的分布式全闪存储系统 ParaStor F9000,一举斩获生产型10节点与全节点双榜第一。
这是中国存储厂商在全球顶级榜单中首次同时包揽这两项冠军。不同于允许数据驻留内存、不考虑实际业务可靠性的“研究型榜单”,IO500 “生产型榜单”要求参选系统必须在真实业务中稳定运行一年以上,且打榜时不能中断其他混合负载。中科曙光这一成绩,不仅打破了国际巨头在高端存储领域的长期垄断,更宣告了国产存储系统在多元复杂业务均衡性、极致性能释放以及大规模扩展性上,已经具备了全球顶尖的硬核实力。
记者采访了中科曙光北京公司总裁助理、分布式存储产品部总经理石静,中科曙光高速网络互联产品部总工程师万伟以及中科曙光分布式存储总工程师袁清波,试图揭开这次历史性突破背后的技术全貌。
生产型双榜第一,含金量不在“跑分”
理解这次成绩的含金量,首先要理解IO500榜单的分类。
石静介绍,IO500包括研究型榜单和生产型榜单,每一类又分为10节点和全节点。10节点榜单,主要考察存储系统能否把10个计算节点的理论峰值发挥出来;全节点榜单,则主要考验整个存储系统和计算系统的整体I/O能力。
相比研究型榜单,生产型榜单更接近真实业务环境。石静解释,研究型榜单更多是看技术在不考虑实际应用时可以跑到什么程度,例如数据可以放在内存里,不一定下刷到磁盘,也可以暂时不考虑分布式存储中常见的纠删码、数据冗余和节点冗余。
但生产型榜单不同。它要求存储系统真正能够在实际业务中应用,而且系统运行时间要超过一年。不超过一年,不能参选。
这也是ParaStor F9000此次拿下生产型双榜第一的难点所在。
石静提到,生产系统在跑测试时,集群里的其他应用不能停。也就是说,不能为了打榜专门把原有业务停掉,而是在原有业务继续运行的情况下,再叠加测试负载。
这就涉及到一个核心问题:在多重业务、混合负载同时存在时,存储系统如何平衡不同业务之间的资源需求,并且在长时间测试过程中保持稳定。
“我们在真正去落实的时候,就会遇到怎么去匹配多重业务之间的混合负载,怎么更好地去平衡。”石静说。
在她看来,这背后体现的是ParaStor F9000在多元复杂业务承载、性能均衡和稳定性设计上的能力。
ParaStor F9000的底层支撑:软硬件一体化设计
石静认为,ParaStor F9000与其他产品形成差异化的第一点,是软硬件一体化设计。
“我们的分布式存储,是软硬件一体的设计。”她表示,中科曙光既有专属设计的硬件平台,也有与硬件深度协同的软件平台。软件和硬件之间做了大量协同优化,这也是整体性能能够做到较高水平的重要原因。
在硬件层面,ParaStor F9000采用了2U2N的特殊形态。石静介绍,市面上2U24盘位NVMe全闪机型并不少见,但F9000在2U空间里集成了两个物理节点,每个物理节点都有独立的主板、CPU、内存、网卡和SSD。这两个节点在同一个机箱中,业内也称为“双子星”架构。这种设计的好处在于,每个节点内部,CPU一侧连接NVMe介质,另一侧连接高速网卡。F9000在连接过程中没有使用PCIe Switch转换,而是让网卡和SSD都直接连接CPU。
同时,在硬件设计时,中科曙光也尽量保证SSD和高速网卡占用的PCIe Lane数量均衡,避免出现SSD侧性能很高、网络成为瓶颈,或者网络侧能力很强、介质侧供给不足的问题。
袁清波进一步解释,这种硬件设计并不是简单堆料,而是来自中科曙光多年对存储系统数据通路的理解。他表示,存储系统经过20多年发展,中科曙光对数据通路已经有了很多积累。团队发现,标准服务器硬件会影响存储系统性能发挥,因此几年前就按照自身对存储系统的理解,重新定制了ParaStor F9000这样的硬件系统。
“这个是第一点,就是我们的一个很大的创新,它最大的作用是给我们提供了两倍的PCIe Lane数量。”袁清波说。
在此基础上,中科曙光重新排布了网络和NVMe设备。
袁清波提到,做标准服务器的人可能会把网卡和NVMe看作平等设备,但对于存储系统来说,它们并不一样。读的时候,数据从盘上读上来,再从网卡发出去;写的时候,数据从网卡收进来,再下到盘上。二者在整个硬件数据流动中的方向正好相反。
这种理解,成为ParaStor F9000进一步优化硬件和软件协同的基础。
“数据直通”与QoS:让每一笔I/O有序流动
在软件层面,石静介绍,中科曙光围绕CPU核心,把与数据相关的内存、网卡和SSD做成一个I/O子域。这样可以保证每一笔I/O都在各自的I/O子域中传输,从而实现混合业务之间的隔离和灵活调配。
袁清波对这一点作了更具体的说明。他说,从计算节点、计算节点网络,到ParaStor F9000存储系统网络,再到CPU、内存、NVMe,所有这些数据通路都进行了排布。用户发出的每一次I/O,从发出那一刻起,系统就知道它要走哪个网卡、用哪块内存、用哪个核,最后下到后端哪块盘。
“通过这样的布局,我们在对硬件性能的发挥上已经做到了极致。”袁清波表示。他还提到,目前系统已经能够把内存带宽跑到峰值状态。后续如果网卡等硬件能力继续提升,系统性能也可以相应提升。
除了超级隧道,ParaStor还具备QoS调控机制。石静介绍,系统可以针对不同文件系统、目录或计算节点,分别设置最低带宽或最低IOPS,也可以支持类似Burst的突发能力。
这意味着,在生产系统中,即使10节点测试业务和全节点测试业务同时对存储施加压力,系统也可以通过较细粒度的QoS机制进行资源分配,尽量保证不同业务之间互不影响。
这正是生产型榜单测试中非常关键的一点。
scaleFabric:为存储性能释放提供高速通路
除了存储本身,此次ParaStor F9000登顶,也离不开中科曙光自研高速互联产品scaleFabric。
万伟介绍,scaleFabric是中科曙光面向大规模AI计算集群推出的400G原生无损RDMA高速网络产品,具备高带宽、低时延特点,全面对标英伟达InfiniBand NDR一代主力量产产品。
其中,scaleFabric单卡芯片可以做到400G带宽,交换芯片可以做到80口400G或40口800G,双向交换容量可达到64T。
“高速互联是整个AI集群或者说AI Infra的算力和存力能够完全释放出来的重要基础。”万伟说。
他用一句更通俗的话概括其意义:“要想富,先修路。”在他看来,高速互联对于集群系统来说,就类似高铁这样的交通基础设施对于城市发展的作用。即使计算芯片有再高算力,存储有再高存力,如果高速互联能力不足,不能把计算或存储数据快速传出去,也无法发挥最大性能。
scaleFabric采取的是类InfiniBand技术路线,同时针对大规模AI集群做了扩展优化。万伟介绍,InfiniBand本身性能和稳定性被业内认可,但目前全球厂商中主要只剩英伟达一家,带来价格和自主可控问题。RoCE生态参与度更高,但基础能力在万卡、十万卡等大规模扩展场景下并不能完全满足需求。
因此,中科曙光自主研发scaleFabric芯片,希望为用户提供类似InfiniBand的原生无损RDMA能力,同时满足自主可控要求。scaleFabric还兼容现有InfiniBand生态,应用可以无缝迁移,不需要修改代码。
在这次IO500测试中,scaleFabric不仅提供了高带宽和低时延,也与存储系统进行了协同设计。
万伟举例称,RDMA通信需要通过QP,也就是Queue Pair通道。面对十万卡集群规模,最极端情况下,一个存储节点可能要面向所有计算节点访问。按照一个进程两个QP计算,可能至少需要20万个QP规模。现有InfiniBand难以直接做到,只能通过其他方式规避。
而中科曙光在设计scaleFabric网卡时,就考虑到了存储部门提出的需求,相比InfiniBand将QP规模扩展了一倍。
“正是因为我们跟存储之间的这种紧密配合,才能取得在IO500上这样的成就。”万伟说。
AI存储三级协同:存储不再只是数据搬运工具
在AI场景下,ParaStor F9000的另一个重要特点,是中科曙光提出的AI存储三级协同方案。
石静介绍,所谓三级协同,是指一笔数据I/O从计算节点流通到存储节点,会经过三个层级:计算节点侧、网络层和存储节点侧。中科曙光在这三个层级上都设计了不同的加速技术。
在计算节点侧,ParaStor可以把计算节点本地内存利用起来,作为第一层Cache;也可以把计算节点本地SSD池化,形成Burst Buffer,用于训练数据集预热。这样后续GPU或CPU访问时,不必每次都跨网络访问后端存储。
同时,ParaStor还支持GPU Direct Storage(GDS/XDS)相关能力,让数据可以绕过CPU内存,直接进入GPU HBM,从而提升训练效率。
袁清波解释,传统路径下,GPU需要的数据要先从存储读到CPU内存,再从CPU内存拷贝到GPU HBM,这会严重受限于内存性能。通过直通能力,数据可以从网卡直接进入GPU HBM,突破客户端侧内存带宽限制。
“这个XDS对于带宽的提升,比过内存的标准版本I/O通路,优势非常明显。”袁清波说。
在网络层,ParaStor支持InfiniBand、RoCE以及中科曙光自主研发的scaleFabric。石静表示,在实际方案中,中科曙光更加推荐使用scaleFabric,通过无损RDMA网络、网卡和交换机能力,把整体性能发挥出来。
在存储节点侧,中科曙光也在AI推理场景下围绕KV Cache做优化。
石静介绍,无论是PD一体化部署,还是PD分离部署,ParaStor都可以将KV Cache在CPU DRAM、HBM、本地SSD和后端存储之间进行协同,并兼容主流推理框架,根据KV Cache算法在不同层级之间流动。
这意味着,存储正在更深地参与AI计算流程,而不仅仅是被动做数据搬运。
袁清波也提到,中科曙光有专门团队分析AI训练和推理对存储访问的行为。团队发现,AI训练对数据读取的带宽和延迟要求很高,一旦数据供给不到位,GPU就会停下来。
“要是数万卡运行停滞,那每1秒都是钱在燃烧。”袁清波说。
因此,ParaStor在AI时代的价值,就是通过更高带宽、更低延迟的数据流优化,让GPU卡充分发挥出来,尽量减少等待和停滞。
从科学计算到自动驾驶、具身智能,存储需求正在变化
在沟通会上,石静也谈到了自动驾驶、具身智能、网联汽车等新兴产业对存储提出的新需求。
她表示,这些场景首先对性能要求更高,不管是带宽、小文件IOPS还是时延,都比传统场景更严苛。
其次,它们希望同一个存储系统能够承接完整业务流程。因此,在实际方案中,中科曙光除了提供ParaStor F9000,也会配合高密混闪产品S6000等产品,满足不同业务环节的需求。
第三,这些行业对效率要求很高,也希望存储系统能够与应用做更深契合。比如自动驾驶行业对数据敏感性、权限控制、数据合规和安全要求更高,这些都比传统行业更复杂。
在石静看来,这些变化说明,存储不能再像过去那样只是计算的配套设备,而应该主动向前,与应用流程做更深结合。
未来,中科曙光存储仍会延续两大产品线:一条是ParaStor分布式存储,另一条是集中式全闪阵列FlashNexus。但在具体场景中,会围绕AI训练、AI推理、工作流、向量数据库、数据标注、数据归集等方向增加更多特性。
双榜第一之后,国产存储仍要面对全球市场考验
对于这次IO500双榜第一是否意味着拿到“全球通行证”,石静的回答比较克制。
她表示,这并不能算是拿到一张全球通行证,而是代表中科曙光具备这样的能力,算是面向全球的一次亮相。
石静也提到,中科曙光存储有拓展海外市场的规划。此次参加德国汉堡相关大会,也在寻找海外代理商、IT服务提供商和分销商,后续如果有具体规划和进度,会再进一步披露。
面对当前国际环境,石静认为,国产存储走出去既有机遇,也有挑战。
从技术角度看,ParaStor F9000此次拿下IO500生产型双榜第一,至少证明了国产高端分布式存储已经可以在真实生产系统中,与国际主流产品同台竞争。
从产业角度看,这次成绩的意义不只是一次排名突破,而是对国产存储长期研发路线的一次验证。
沟通会最后,当被问到如何总结这次成绩时,石静用了八个字:“行稳致远、长期主义。”
袁清波则表示,“我们这么多年的付出,终于在这一刻有了回报。”
这或许也是ParaStor F9000登顶IO500更值得关注的地方。
在AI和超智融合加速发展的背景下,高性能存储正在从计算系统的配套设备,变成影响算力释放效率的关键环节。对于大规模AI集群来说,存储、网络和计算之间的协同能力,正在变得越来越重要。
而这次中科曙光拿下IO500生产型双榜第一,至少说明国产存储已经在这一轮系统级竞争中,迈过了一个重要的生产级验证关口。
点这里👆加关注,锁定更多原创内容
*免责声明:文章内容系作者个人观点,半导体芯闻转载仅为了传达一种不同的观点,不代表半导体芯闻对该观点赞同或支持,如果有任何异议,欢迎联系我们。
推荐阅读

喜欢我们的内容就点“在看”分享给小伙伴哦~![]()











