公众号记得加星标⭐️,第一时间看推送不会错过。

随着晶体管密度缩放速度放缓,先进封装已成为主要的扩展途径。然而,人工智能加速器体积庞大,且需要极高的互连速度,导致封装本身也面临极限。圆形中介层限制了封装尺寸和晶圆利用率,HBM4E 技术在提高速度的同时使 I/O 数量翻倍,而多千瓦级封装则使传统的冷却架构难以承受。
ECTC是业界首屈一指的封装技术盛会。今年的发布内容与即将上市的商业产品密切相关。英特尔概述了EMIB-T集成、封装尺寸缩放以及未来的发展路线图。Marvell展示了如何通过定制HBM将接口逻辑从加速器中移除,同时缩短封装布线。台积电和微软将冷却剂直接集成到硅片中,而Marvell和Lightmatter则将光互连集成到封装中。
本次综述涵盖了 ECTC 2026 中最有可能在未来几年内塑造 AI 加速器方案的技术。
英特尔 EMIB-T
英特尔是ECTC展会上规模最大的企业演讲者。其重点展示的是EMIB-T。这是采用硅通孔(TSV)技术的下一代EMIB芯片。在最初发布之后,英特尔进一步完善了该架构和路线图,包括更小的凸点间距、更大的封装尺寸以及桥接功能。他们的展示表明,EMIB-T有望应用于谷歌的TPU v9,并且是大型封装AI加速器领域中,台积电CoWoS平台最可靠的替代方案。
EMIB-T 扩展测试芯片,硅含量为光罩的两倍。俯视扫描电镜图像显示,凸点间距分别为 110、55 和 36 微米。

英特尔已在采用两倍光罩尺寸硅片封装的芯片上验证了 EMIB-T 技术,其凸点间距为 36/35 微米。相比 Granite Rapids 封装中使用的 45 微米间距,凸点密度提高了 65%。Granite Rapids-AP 是一款大型封装,尺寸为 70 毫米 × 105 毫米,面积略小于 9 个光罩。目前,针对 36/35 微米凸点间距的验证工作正在扩展到 4.5 倍光罩尺寸的硅片封装,目标是在 2026 年底前完成认证。

下一个间距步骤也正在进行中,英特尔正在测试 25 µm 凸点间距,该间距基于一个由两个 1 个光罩硅芯片通过单个 3 毫米 × 18 毫米 EMIB-T 桥连接的芯片。
进一步缩小尺寸将变得更加困难。小于 25 µm 时,每个焊球中的焊料体积会变得非常小。短路、开路以及组装过程中导致的良率损失的可能性大大增加。EMIB-T 可以继续缩小尺寸,但限制因素从桥接布线密度转移到了焊球形成、布局精度和组装良率。

英特尔还展示了EMIB-T封装的尺寸极限。虽然可以实现全面板尺寸的封装,但英特尔将四分之一面板封装作为实际目标。他们展示了一个240毫米×240毫米的测试样品,面积大约相当于67个光刻掩模。然而,我们观察到展位上的样品出现了严重的翘曲。在这个尺寸下,桥接只是问题的一部分。基板处理、翘曲、套刻精度和面板级图案化都成为首要的限制因素。英特尔也在评估先进的光刻技术,以确保在四分之一面板甚至全面板尺寸下,这些大尺寸基板的套刻精度足够高。

虽然凸点间距和封装尺寸很重要,但桥接电路同样至关重要。EMIB-T 比目前产品中使用的 EMIB 复杂得多。它增加了 TSV、更多金属层、电源网格和 MIM 电容层,使桥接电路能够同时传输高密度信号和垂直供电。英特尔展示了一个横截面图,其中包含 10 层金属层(包括 4 层布线层)以及位于 M1 和 M2 之间的 MIM 电容。英特尔重点介绍了其针对 HBM4E 的改进。

EMIB-T 中的“T”代表 TSV(硅通孔)。它们的作用是供电。在传统的 EMIB 中,非桥接区域的电源通过基板垂直传输,而桥接区域附近的电源则必须横向扩散到封装和芯片侧布线中。通过在桥接区域使用 TSV,电源可以直接通过桥接区域传输,从而显著缩短电流路径。英特尔声称,使用这些 TSV 可以将直流电压降降低 68% 到 80%。
HBM4E 的难点在于互连必须同时提升信号密度和供电能力。HBM4 的引脚数量是 HBM3 的两倍,并且 PHY 需要额外的电源轨,例如 VDDQ 和 VDDQL。这些电源轨会占用部分信号布线空间,从而提高剩余空间的信号密度。
为了解决这个问题,英特尔并没有对所有HBM通道采用相同的布线方式。它将最长的信号路径放置在布线更简洁的层上。在M9层,只有约28%的最长通道长度穿过布线最密集的区域,而在M3等较低层,这一比例上升至约84%,但这些通道的长度更短。这样可以避免串扰和插入损耗主要由布线最差的区域造成。

电源传输也转移到了桥接层。EMIB-M 在 M1 和 M2 之间引入了金属-绝缘体-金属 (MIM) 电容,而 EMIB-T 则在此基础上进行了改进。英特尔公布的电容密度为 500 nF/mm²,与英特尔 18A 的 MIM 电容大致相当。英特尔声称,与没有桥接 MIM 电容的 EMIB-T 封装相比,这些桥接电容可将电源传输网络 (PDN) 的交流阻抗降低 82% 以上。
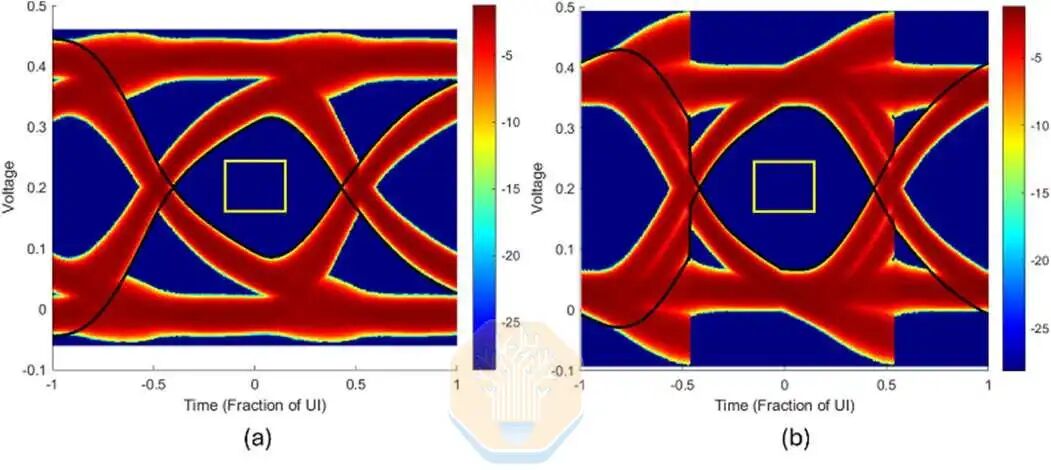
英特尔还对采用 HBM4E 的 EMIB-T 进行了仿真。在 12 Gb/s 的速率下,未采用接收均衡时,英特尔的 UI 眼图宽度约为 67%。采用单抽头判决反馈均衡器 (DFE) 后,该值可提升至约 72.5%。DFE 是一种接收端电路,用于降低信号通过封装通道后先前比特的干扰。
英特尔还模拟了更高的传输速度,分别为 12.8 Gb/s、14 Gb/s 和 16 Gb/s。在所有测试速度下,用户界面视口宽度均保持在 60% 以上,焊盘电容略有下降。
英特尔的EMIB路线图超越了仅包含布线和电容的被动桥接技术。未来的版本将包括更高密度的桥接MIM电容、更大尺寸的高纵横比桥接芯片、小于25微米的凸点间距、主动桥接以及集成在EMIB芯片内部的电压调节器。英特尔还公开了基板核心嵌入式深沟槽电容(DTC)的概念以及嵌入在基片下方的>2500 nF/mm² eMIM-T电容,尽管我们尚未在已出货的EMIB产品中看到这些技术。
EMIB-T在多个方面仍落后于台积电的CoWoS平台。台积电已实现DTC/eDTC集成,并在集成电压调节器和有源局部硅互连(LSI)方面走得更远。EMIB-T缩小了差距,但英特尔仍在追赶一个已大规模运行多年的生态系统。
Marvell 定制 HBM
在 Marvell 2024 年的行业分析师日上,Marvell 宣布推出定制 HBM。当时,这只是一个模糊的说法,缺乏技术细节。HBM的设计一直围绕 JEDEC 兼容性展开:内存供应商提供的标准 DRAM 堆栈、加速器上的标准 HBM PHY,以及它们之间固定的宽接口。在 2025 年 Hot Chips 大会上,Marvell 展示了定制基础芯片的布局图。

在 ECTC 大会上,Marvell 最终提供了定制 HBM4E 的封装级细节。
JEDEC规范固定了HBM堆栈与主机之间的接口。这有利于互操作性:任何内存厂商的HBM都可以与任何兼容的主机配对。然而,这不利于功耗、性能和面积。主机ASIC必须实现标准的HBM PHY,并采用标准化的焊盘布局和分线规则,布线一个非常宽的并行接口。随着封装尺寸的增大和HBM速度的提升,这种固定的边界使得优化海岸线、布线密度、电源供应和信号完整性变得更加困难。

定制化HBM技术无需对DRAM核心芯片进行任何改动。取而代之的是,采用先进的逻辑工艺制造一个具有优化芯片间接口的定制基础芯片。该定制基础芯片可集成HBM控制器、管理和监控功能、定制逻辑以及扩展接口。

Marvell 声称,这使得用于 HBM PHY 和相关逻辑的主机 ASIC 占用空间减少了约 60%,从而直接释放出更多空间用于计算、缓存或 I/O。这种定制接口将大部分内存端接口移到了 HBM 基体芯片中。
Marvell 的示例使用了 1024 个通道,速率为 32 Gb/s,达到 4.1 TB/s,相当于 2048 位 JEDEC HBM4(E) 接口,速率为 16 Gb/s。
该封装的布线也变得更加容易,定制接口将中介层通道长度从 6.5 毫米缩短到 1.5 毫米,使 Marvell 能够在保持相同 9 个布线层和 2/2 微米线/间距 (L/S) 的同时增加带宽。
Marvell 的示例中使用有机重分布层 (RDL) 中介层代替硅,从而降低了封装成本。有机 RDL 的线宽/线宽比远小于 CoWoS-S 中的硅中介层或 CoWoS-L 和 EMIB-T 中的硅桥,这增加了布局难度。Marvell 依靠不同部分的定制屏蔽和布线模式来最大化带宽密度,同时控制串扰。

在GTC大会上,英伟达宣布Feynman将采用定制HBM。英伟达的理由可能与Marvell类似:更高的带宽、更低的功耗以及更少的HBM加速器芯片面积。我们估计,Rubin GPU芯片面积中约有16%用于HBM相关的逻辑和PHY。定制HBM可以让英伟达将大部分负担转移到HBM基础芯片上。
定制化HBM还支持标准HBM链路之外的扩展接口。基础芯片可以充当辅助内存控制器,并将流量扇出到额外的内存,而不是强制所有内存流量都通过有限的加速器芯片边缘通道。这些额外的内存可以是容量更大、带宽更低的LPDDR,甚至是第二层HBM。这使得加速器能够在不占用外部I/O所需的宝贵芯片边缘通道的情况下扩展内存容量。这对于AMD即将推出的MI450和未来的MI500 GPU尤为重要,因为它们将支持LPDDR以增加内存容量。
三星HBM中介层
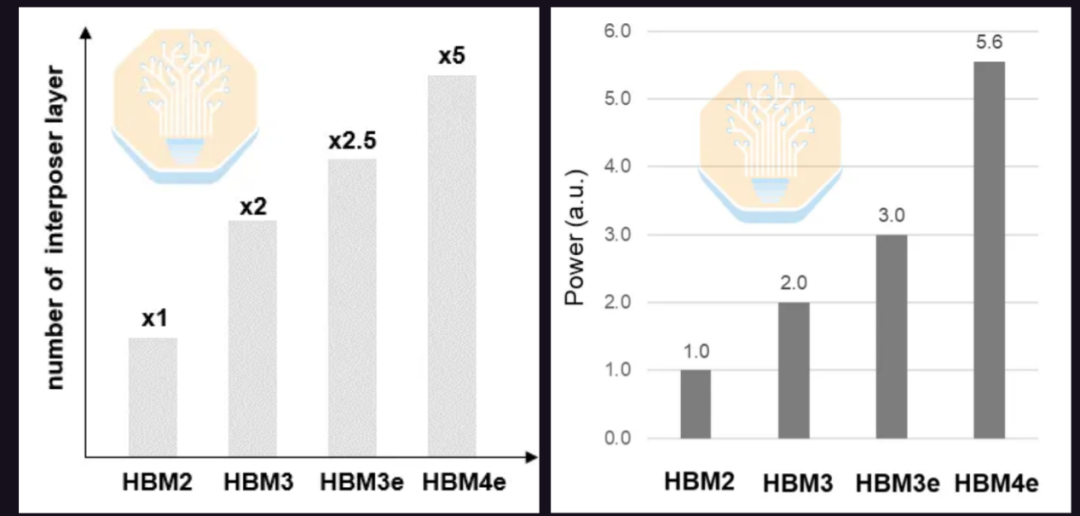
三星还展示了其基于中介层的 HBM4E 解决方案。HBM4E 将数据传输速率提升至 12 Gb/s 及以上,并将 I/O 引脚数量翻倍,从而增加了布线复杂性。HBM4E 所需的中介层数量可能是 HBM3E 的两倍,是 HBM2 的五倍。由于 I/O 引脚数量增加和数据传输速率提高,预计其功耗也将比 HBM3E 增加 86%,比 HBM2 增加 5.6 倍。

三星提出了一种8层硅中介层方案,据称与预估需求相比,层数减少了20%。该中介层采用重复的双信号/单地交错排列方式来屏蔽高速信号,其中75%的层用于信号布线。

中介层的另一个关键特性是超高密度电容(UHC)。三星并未明确说明具体的电容结构,但它们可能类似于英特尔EMIB-T MIM电容或台积电CoWoS DTC电容。UHC电容只能放置在M1层,而M1层也主要用于信号布线,因此可用面积有限。
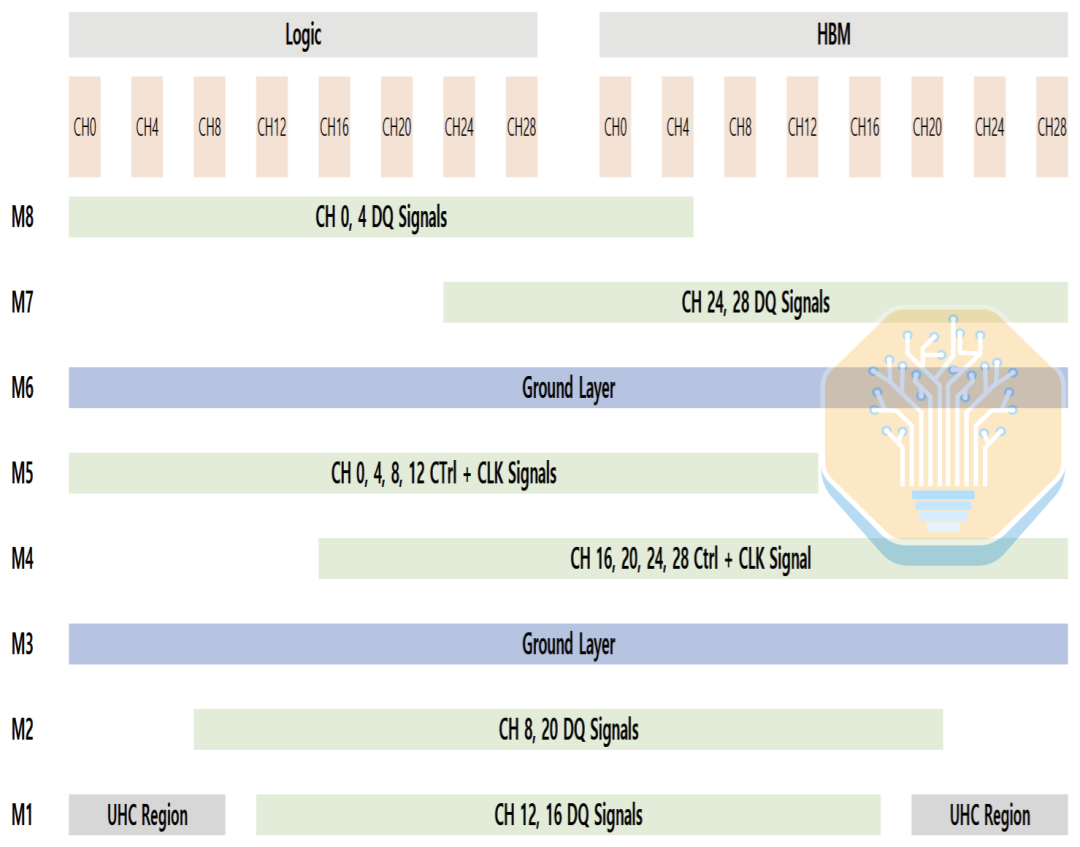
如果布线不平衡,电容会被推向接口的一侧,导致逻辑侧和HBM侧之间的电源分配网络(PDN)性能不均衡。三星的布局将布线重新分配到M1层和其他层,从而使超高电容(UHC)能够更均匀地分布在整个接口上。这在保持布线密度可控的同时,降低了PDN阻抗和电压噪声。
三星 HBM 混合键合热学

三星还讨论了HBM的热问题,特别是混合键合技术。HBM堆叠层数越来越多,速度也越来越快,而其下方的逻辑芯片的功耗也越来越高。对于16层HBM来说,其热阻尚可接受,但随着未来几代产品向20层和24层HBM发展,就需要新的解决方案了。

三星对比了热压键合 (TCB) 和混合铜键合 (HCB) 在 2.5D GPU 封装(包含 2 个 GPU 芯片和 8 个 HBM 堆叠,类似于 Nvidia Blackwell 架构)中的 HBM 散热性能。结果表明,风冷可使内部 HBM 热阻降低 12.2%,液冷可降低 12.9%。总 HBM 热阻在风冷下可降低 3.5%,在液冷下可降低 7.7%。
由于HCB仅针对部分散热网络,因此改进效果并不均衡。三星将散热路径分为内部热阻、系统级热阻和GPU到HBM的串扰。内部热阻和串扰分别降低了约12.5%和9.8%,但包括导热界面材料和散热在内的系统级热阻却增加了约2.3%。

随着更多功率转移到HBM基片上(例如在内存密集型工作负载中),散热瓶颈会发生转移。这对于定制HBM尤其重要,因为其内存控制器和更多逻辑电路都集成到了基片上。GPU到HBM的串扰在总热阻中所占的比例会降低,从基片功耗增加1倍时的13%下降到基片功耗增加3倍时的5%。
三星表示,采用HCB技术可以提高进气温度或提高封装功率。据其估计,采用HCB技术后,在封装功率保持不变的情况下,进气温度可升高1-2°C;或者在温度保持不变的情况下,封装功率可提高约4%。三星还估计,散热功率将降低约7%。

三星还单独研究了HCB在堆叠层面的影响。这里的改进幅度更大:与TCB相比,基准HCB可将堆叠热阻降低约19%。增加HCB焊盘数量,焊盘密度增加2倍时,热阻降低幅度可达22.3%;焊盘密度增加4倍时,热阻降低幅度可达29.1%。
微流体冷却


台积电在CoWoS-R芯片上展示了直接硅冷却技术,该芯片应用于类似GPU的大型测试平台。CoWoS-R与CoWoS-S的区别在于前者采用的是有机材料而非硅基中介层。选择CoWoS-R是因为它具有更好的翘曲容差和工艺兼容性。该测试平台采用3.3倍光罩的中介层,包含4个SoC芯片和8个HBM堆叠层。每个SoC芯片由4组SoC加热器组成,这些加热器共同覆盖了大约一半的中介层面积。

台积电对比了三种方案:传统的带盖冷板封装、无盖冷板封装以及其微柱直接硅封装设计。带盖和无盖方案仍然采用传统的冷板和导热界面材料(TIM)。而最后一种方案则是在SoC芯片背面直接形成微柱。
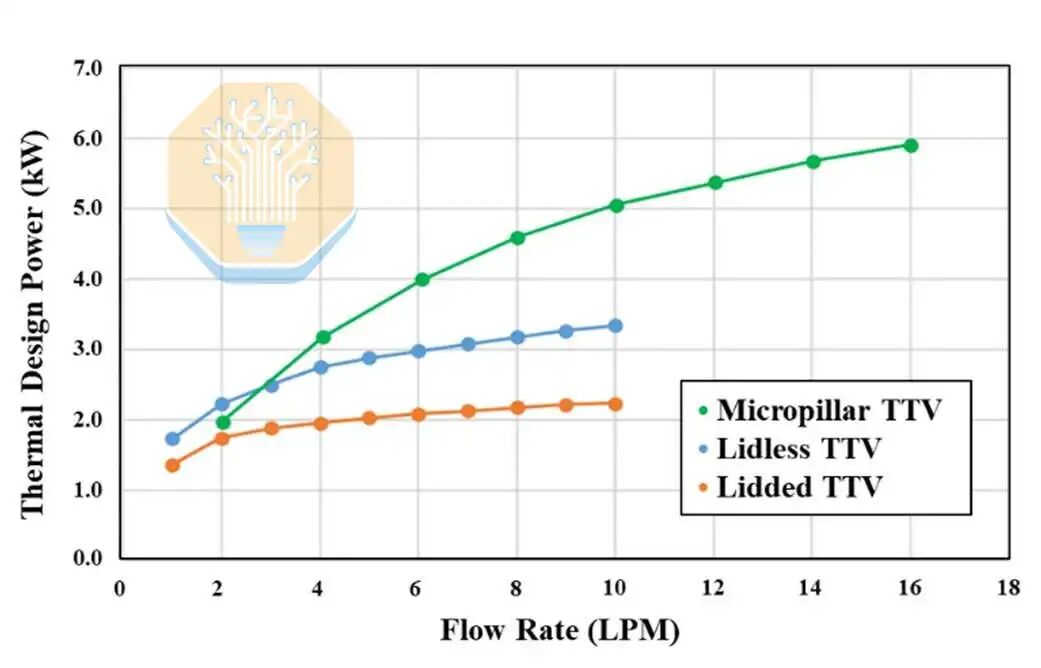
采用常规冷却方式,流速为 1-2 升/分钟 (LPM) 时,带盖封装的散热量为 1.9-2.3 kW,而无盖封装的散热量为 2.5-3.0 kW,冷却水温度为 40 °C 的去离子水。两种方案在流速超过 4 LPM 后均达到饱和,因为导热界面材料 (TIM) 成为瓶颈。
微柱式测试车( test vehicle )在2升/分钟(LPM)的流速下与无盖冷板的测试结果相当,随后在高流速下表现更佳,在4升/分钟时散热功率为4千瓦,在8升/分钟时为5.3千瓦。台积电报告称,在整个测试车上,散热功率均匀地超过了5千瓦。微柱式结构使液态冷却剂更靠近热源,从而促进了散热性能的提升。
然而,微柱结构并非完美无缺。台积电必须在芯片封装(CoW)工艺完成后形成微柱,同时还要避免损坏CoWoS-R结构,并开发新型密封材料,以确保在封装翘曲和热膨胀系数不匹配的情况下,冷却剂仍能保持密封状态。测试样品通过了湿度敏感等级4(MSL4)测试,未出现氦气泄漏或密封剂分层现象。

微软的散热方案与台积电的不同之处在于散热结构。台积电采用的是硅微柱,而微软则采用了蚀刻在GPU硅片上的直线微通道。微软没有使用热测试平台,而是直接在Nvidia GH200 GPU上进行了测试。这可能使微软能够更准确地捕捉到真实的散热分布和热点区域。微软在GPU上测试了多种工作负载,例如HPCG和HPL,每种工作负载都具有不同的计算和内存压力特性。

在这些工作负载下,微软报告称,在 1 LPM 的流速下,GPU 的结到入口热阻降低了 51-60%。HBM 的改进幅度较小,仅为 27-37%,因为它仍然通过冷板和导热材料进行冷却。总体而言,这使得封装的热阻降低了 50%。
微软还展示了一些初步的可靠性数据。虽然散热性能很重要,但数据中心部署也需要高可靠性和低停机时间。在6个月的时间里,微软在约4370次观测中仅记录到9次潜在的堵塞事件。堵塞率随时间推移而下降,表明安装初期存在不稳定情况,随后进入较为稳定的运行阶段。即使6个月后,微通道中也没有可测量的硅腐蚀。在节点层面,GH200成功完成了为期3周的重复基准测试,随后又在稳定的封装功率下连续运行了1周。微软仍在测试集群层面的平均故障间隔时间(MTBF)和可用性。
Marvell 光互连
ECTC的另一个主要主题是光互连和共封装光学器件。Marvell在该领域发表了多篇论文,主要内容是其光多芯片互连桥(OMIB)和光子结构,这两项技术都是该公司今年早些时候收购Celestial AI后获得的。
虽然光子中介层技术已讨论了数年,但 Marvell 在 ECTC 上展示了一种更局部化的版本。制造多掩模光子中介层可能会对良率构成挑战,尤其是在掩模拼接方面。Marvell 还指出,光子中介层可能缺少传统硅中介层所具备的一些功能,例如高密度电容器。

Marvell 的方案是在有机 RDL 中介层中仅在需要的地方嵌入光子集成电路 (PIC)。在其他不需要光互连的区域,可以使用电桥代替。
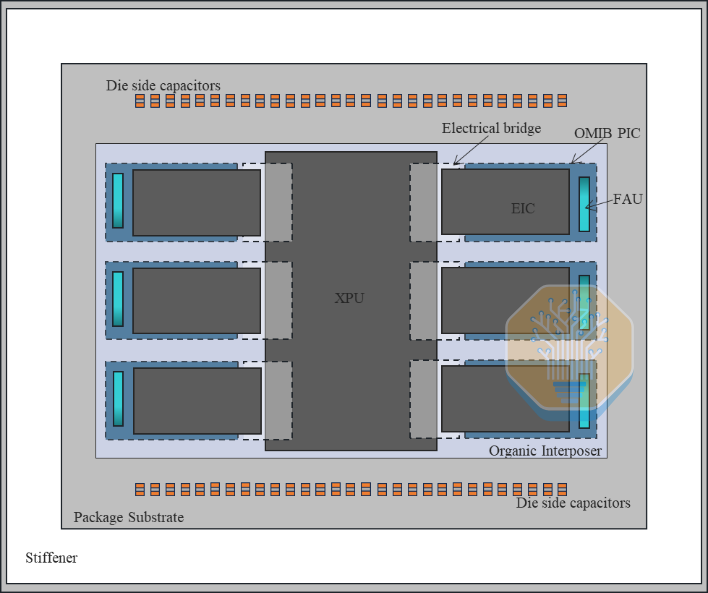
由于光子集成电路 (PIC) 嵌入在 RDL 中,其光栅耦合器通常会在包覆成型后被遮挡。Marvell 在成型前会在光栅区域上方放置一个硅/玻璃光学模块,以保持通往顶部的光路,从而将光纤阵列单元 (FAU) 连接到顶部。

Marvell 的 OMIB 测试平台包含一个主 XPU 芯片和位于其上的六个 EIC 芯片。嵌入在中介层中的芯片包括六个 PIC(蓝色大矩形)、六个电桥(蓝色细矩形)和十二个 DTC 芯片(蓝色小正方形)。该 RDL 中介层采用四层结构,线宽/层厚为 2/2 µm,尺寸约为 2× 光罩。

Marvell 还展示了一款概念性的多芯片 XPU,该 XPU 采用光芯片间互连技术,以降低延迟和跳数。Marvell 声称,OMIB 技术消除了海岸线限制,因为同一桥接器可以同时路由封装内的芯片间链路和外部光互连。Marvell 表示,采用这种方法可实现 1.8 Tbps/mm² 的带宽密度。

Marvell 展示的工艺流程是芯片后置的,类似于台积电的 CoWoS-L。Marvell 构建了一个有机 RDL 中介层,其中包含嵌入式桥接器、OMIB PIC、DTC 和其他组件,并通过 C4 凸点将其连接到封装基板。桥接 TSV 和高铜柱连接到 RDL,ASIC 芯片和 EIC 最后贴装。

短期内,像台积电的 COUPE 这样的垂直堆叠式光引擎比 OMIB 式连接或全光子中介层更容易实现。Marvell 使用间距为 50 µm 的微凸点连接 EIC 和 PIC,然后将由此形成的光引擎安装到封装基板或中介层上。
衬底结构可采用间距为 130 µm C4 的类似 UCIe-S 的并行总线,而中介层结构可采用间距为 ~40-45 µm 的更紧凑的 UCIe-A 接口。Marvell 更倾向于衬底方案,因为它结构简单且隔热性能更佳。

Marvell 测试了一种采用 5 纳米(可能是台积电 N5)EIC 的光引擎,该引擎包含四对 56 Gb/s 的收发器,每个方向的传输速率均为 224 Gb/s。该设计采用电吸收调制器 (EAM)而非其他公司常用的微环调制器 (MRM),理由是 EAM 具有更好的热稳定性和更宽的工作波长范围。虽然这些优势确实存在,但我们认为 EAM 的大规模生产将面临挑战。

Marvell 还比较了通过 UCIe-S 连接到衬底上的光引擎以及通过 UCIe-A 连接到硅中介层和硅桥上的光引擎的热特性。在 XPU 满载的情况下,衬底上的 PIC 温度升高不到 5 °C,而中介层上的 PIC 温度升高约 25 °C,桥上的 PIC 温度升高约 20 °C。有机衬底的低导热性和相对较大的毫米级空气间隙隔离了 PIC。在两种 UCIe-A 配置中,靠近 XPU 的细间距硅提供了一条低电阻的热通路。此外,空气间隙也小得多,仅约 100 µm,这会导致 PIC 发热。

XPU 电源状态改变后约 30 毫秒内会发生热瞬变。PIC 在有机衬底上的升温速率约为 10 °C/s,而使用桥接电路时约为 100 °C/s,使用中介层时约为 120 °C/s。Marvell 认为,EAM 偏置电压可以通过电子方式快速调节以跟踪这些变化,而环形调制器则需要加热器和反馈回路,这些回路受到较慢时间常数的限制。
Lightmatter M1000
Lightmatter此前已详细介绍了Passage M1000的架构和光互连,并概述了其制造工艺。在ECTC展会上,该公司更深入地探讨了多光罩光子中介层与ASIC芯片集成的组装工艺、光纤连接和封装结果。

该测试芯片采用晶圆级芯片组装技术,将15个ASIC芯片单元连接到一个四单元M1000中介层上。我们估计该中介层的面积约为2100平方毫米,约为Hot Chips 2025展会上展示的4000平方毫米八单元配置的一半。M1000可根据产品需求高度灵活地配置成不同的尺寸和单元数量。
四个芯片单元均包含 32 个间距为 127 µm 的光波导。电信号和功率从衬底经由间距约为 176 µm 的 C4 凸点、两层背面 RDL 层以及深度为 126 µm、宽度为 10 µm 的 TSV 从衬底传输到 ASIC 芯片,最终通过微凸点到达 ASIC 芯片。面积约为 2100 mm² 的中介层仅占 7200 mm² 有机衬底面积的不到三分之一。该比例更接近于逻辑区域与封装尺寸的比例,而非等效硅或有机 RDL 解决方案中跨越封装的中介层面积。目前尚不清楚这是光学架构的固有特性,还是针对此测试芯片的特定设计选择。

将这种尺寸的硅中介层贴装到有机基板上会造成严重的翘曲。在 260 °C 的回流焊温度下,模块的翘曲度达到约 59 µm,冷却至室温后约为 56 µm。由于中介层厚度为 118 µm,且 C4 凸点间距约为 176 µm,这样的翘曲度足以影响连接结构的形成。Lightmatter 公司使用磁性夹具在贴装过程中保持基板平整,并报告称其电气组装良率超过 95%,且整个封装的微凸点和 C4 连接均保持良好。

Lightmatter 使用了一款热测试芯片,该芯片具有四个独立供电的象限,每个象限耗散 170 W 的功率。这使得在 369 mm² 的有效面积上实现了 1.47 W/mm² 的功率密度。在此功率下,使用 25 °C 的冷却剂,流速为 1.8 LPM/kW,光子中介层的温度达到了约 100 °C。这验证了在设计用于承受超过 900 W 功率(覆盖近三个 ASIC 硅光刻层)的封装中,仅对集中测试芯片区域进行 680 W 的冷却效果。
其他亮点
一、混合键合
对于高性能计算 (HPC) 应用而言,混合铜键合依然能够提供最佳的引脚间距和最高的 I/O 密度。目前面临的挑战是如何在降低键合温度的同时,保持界面极其平整洁净。今年有两种材料方案脱颖而出。
第一种方法采用有机介电材料,其机械柔顺性提高了对颗粒和表面粗糙度的容忍度,同时降低了键合应力。三井化学和日月光电子(ASE)展示了在200℃和10µm间距下实现的无压铜/聚合物键合。TOK和纽约大学(NYCU)展示了在150℃下10秒即可完成的键合工艺。在可靠性测试中,200℃下键合的样品保持了稳定的电阻。

第二种方法采用细晶铜。其较高的晶界密度可加速低温下的铜扩散,随后的晶粒生长可提高导电性。英特尔将细晶铜与低温介电层相结合,在 175 °C 和 200 °C 退火后实现了均匀的晶圆键合。三个样品中有两个的电气良率约为 60%,但英特尔指出,由于测试平台和探测技术的限制,这些结果仅为下限。实验采用的是晶圆对晶圆 (W2W) 测试平台,而非该技术所针对的芯片对晶圆 (D2W) 工艺。
应用材料公司和EV集团的方案最具突破性,他们展示了间距为450纳米的晶圆间键合,在2000万个连接点组成的链上实现了98%的良率。失效分析表明,开路连接与铜界面处富碳苯并三唑(BTA)残留物有关。采用PVD TaN/Ta阻挡层显著提高了良率。CEA-Leti公司在未进行等离子体活化的情况下,经100℃退火后,也实现了超过97%的良率。
这些结果共同表明,要实现低翘曲、无裂纹的混合键合,需要对铜、介电层、化学机械抛光 (CMP)、表面处理和退火工艺进行协同优化。我们预计,从 2027 年起,材料供应商和设备厂商将持续改进工艺,以提高键合后的成品率。
二、中介层替代方案
随着封装尺寸超出圆形硅中介层的实际限制,越来越多的供应商提出了超越英特尔 EMIB-T 的无中介层集成方案。

英特尔和SPIL将一个SRAM芯片封装在扇出型嵌入式桥接(FO-EB)封装的嵌入式桥接层中,并通过25µm间距的微凸点将其垂直连接到逻辑芯片。测试芯片在0.24pJ/b的能耗下,读写速度超过265GB/s/mm²。
面板级有机中介层为突破硅的尺寸限制提供了另一条途径。Resonac公司展示了在320 mm × 320 mm面板上制备干膜嵌入式桥式中介层的各个工艺模块,其中包括5 µm微孔和2/2 µm线/空隙。ASE公司在600 mm × 600 mm面板上制造了RDL层,然后将其分割成四个300 mm × 300 mm面板,以便使用现有设备进行组装。其测试平台使用了三层RDL层,线/空隙为5/8 µm。

IBM 采用了一种更为局部化的方法,即直接桥接多芯片 (DBrM)。首先将芯片沿边缘连接起来,围绕 30 微米间距的硅桥形成一个机械刚性子组件。该子组件在弯曲测试中承受了超过 30 牛顿的力,而 IBM 之前仅使用底部填充的结构只能承受 0.2 牛顿的力。这对于减少翘曲变形来说是一个积极的成果。

Unimicron公司设计了一种更为简单的结构,既不需要中介层也不需要嵌入式桥接器。两个芯片通过安装在其下方并直接连接到基板上的薄硅桥连接。Unimicron公司的仿真结果表明,芯片和桥之间的底部填充对于控制微凸块应变至关重要。
尽管台积电的CoWoS-R和CoWoS-L仍受限于其RDL所采用的圆形晶圆,从而限制了封装尺寸和晶圆利用率,但这些替代方案将集成转移到面板级或重构格式,甚至完全取消了中介层。我们预计类似的架构将在未来几年内开始出现在ASIC中。
三、热界面材料
在先进散热解决方案领域,台积电及其合作伙伴继续占据主导地位。台积电的直接硅冷却技术完全无需导热界面材料(TIM1),但大多数近期系统仍需要在硅片和散热器之间使用性能更优的材料。台积电的OSAT合作伙伴SPIL在55 mm × 55 mm的FO-EB封装中测试了镓基液态金属(LM)复合材料、硅基高导热界面材料(HS-TIM)和碳纤维高导热界面材料(HCF-TIM)。测得它们的导热系数分别为5.7 W/m·K和10 W/m·K,且均低于商用硅基导热界面材料(4 W/m·K)的热阻。


两种导热界面材料(TIM)的可靠性表现截然不同。HCF-TIM在150℃下运行1000小时后仍保持95%的覆盖率,而HS-TIM由于硅基体硬化和部分分层,覆盖率降至75%。两种液态金属基TIM均降低了热阻,优于传统的硅基TIM,其中HCF-TIM的性能和可靠性最佳。
普渡大学、阿威罗大学和加州大学洛杉矶分校采用了不同的方法,将铜/锡微凸点嵌入纳米晶金刚石中。由此产生的互连层实现了500至600 W/m·K的有效面内导热系数,约为传统底部填充微凸点的20倍。这并非TIM1的替代品,而是一种将热量横向扩散到3D堆叠互连层的方法。该工艺仍处于早期阶段,论文中仅使用了单面测试结构,而非组装的3D堆叠结构。
另一方面,我们很少看到关于 SiC 作为 TIM1 或热解决方案一部分的讨论,这意味着距离成熟还有相当长的路要走。
三、玻璃基板
今年,玻璃领域的光芒有所减弱,ECTC会议上发表的创新论文数量有所减少。然而,SeWaRe问题依然悬而未决,即在RDL应力作用下,从切割玻璃边缘开始出现的横向裂纹。佐治亚理工学院通过实验表征了这种失效模式。康宁公司运用有限元分析(FEA)、近场动力学和解析断裂力学方法模拟了裂纹的扩展过程,结果表明,刚性铜层会将裂纹推向玻璃中面,而柔性聚合物层则会改变裂纹扩展路径。康宁公司还发现,低热膨胀系数(CTE)聚合物与合适的玻璃材料相结合,可以降低失效风险。

STATS ChipPAC 对大型玻璃芯封装的组装和可靠性进行了研究。其 74 mm × 74 mm 的玻璃芯封装在未进行边缘涂层处理的情况下,所有测试环节均未通过;而进行边缘涂层处理的封装则顺利完成了组装和可靠性测试,未出现任何异常。与未涂层的玻璃芯封装相比,边缘涂层还将翘曲度降低了 33.5%。回缩技术和边缘涂层处理正日益成为可靠玻璃芯基板组装的必要条件。


值得一提的是,英特尔展示了业界首款510毫米×515毫米、24层玻璃芯面板,该面板采用全铜填充的玻璃通孔(TGV)、两个嵌入式EMIB桥接器以及在TGV之间共生的光波导。这款大型原型在英特尔展位展出。它采用现有的有机基板生产线制造,而单个单元在热冲击测试后未出现SeWaRe现象。
作为 OSAT 采用者,Amkor 和 STATS ChipPAC 测量发现,与有机参考材料相比,采用更薄的玻璃芯后,基板级翘曲降低了 30-40%,但组装缺陷和 TGV 填充问题表明该工艺仍不成熟。
玻璃技术正在取得实质性进展,但今年的数据仍然支持制造业发展,而不是大规模应用。
四、RDL缩放
最后,即使封装尺寸不断增大,RDL L/S 也持续缩小。主要驱动因素是 UCIe 3.0,它支持未来 ASIC 到 ASIC 和 ASIC 到 HBM 链路高达 64 GT/s 的速度。随着有机中介层尺寸和密度的增加,这些高速芯片间互连对信号完整性提出了更高的要求。
该路线图已从2015年左右的10/10微米线/间距发展到如今的2/2微米,而1/1微米正成为下一个目标。迈向亚微米时代需要对RDL布线架构和制造工艺进行重大变革。工艺正从半增材电镀转向用于2微米以下铜的镶嵌工艺,其中CMP平坦化和低收缩率介质成为关键的调控步骤。
Resonac公司采用聚合物镶嵌工艺和面板化学机械抛光(CMP)技术,在320 mm × 320 mm的玻璃面板上形成2/2 µm的线间距,其中包括四层通孔沟槽结构。imec和富士胶片公司在300 mm晶圆上将镶嵌工艺的线间距提升至1/1 µm。Ushio公司在18个光罩的范围内实现了1.5/1.5 µm的线间距,无需拼接,16次曝光即可覆盖整个510 mm × 515 mm的面板。住友电木公司和佐治亚理工学院展示了一种完全亚胺化的液态介质,在相对较低的200 °C温度下固化收缩率仅为4%,并实现了精细的2/2 µm线间距。

作为最先进的RDL制造商,台积电还与GUC合作,展示了其在8层RDL扩展方面的工作,这被认为是CoWoS-R平台近期的极限。GUC演示了一种基于STCO的设计和验证流程,用于集成在台积电N3工艺制造的64位UCIe-A接口,并将其集成到8层CoWoS-R RDL上。
其 STCO 框架采用地-信号-地交错传输线来控制串扰和偏移,而仿真结果表明,C4 侧 IPD 提供局部解耦并减少芯片微凸块处的电压波动。

该设计目标吞吐量为 16-36 GT/s,采用 64 位、10 列 UCIe-A 接口,凸点间距为 45 µm。信号走线以 2/2 µm 的间距跨越六层,第七层用于供电。测试芯片在 32 GT/s 吞吐量下测得的片上眼图宽度为 0.77 UI,而仿真结果显示,在 36 GT/s 吞吐量下,眼图宽度为 0.74 UI。结果表明,有机中介层能够满足异构芯片组系统的信号和电源完整性要求。
五、堆叠式内存

三星展示了一种完全避免使用硅通孔(TSV)的DRAM堆叠方案。垂直铜柱堆叠(VCS)通过嵌入封装化合物中的间距小于56微米、宽度小于30微米的高纵横比铜柱连接四个堆叠的内存芯片,而非通过硅蚀刻通孔,同时还用RDL取代了封装基板。与传统的引线键合堆叠相比,缩短互连线使功耗降低了41%,在相同速度下从0.646瓦降至0.384瓦。三星还报告称,该方案提高了信号传输性能,最大数据速率从8.6 Gb/s提升至11.8 Gb/s,而功耗仅增加了8%。

该器件的外形尺寸也得到了显著提升,封装高度和占地面积均减少了 40%,而带宽提升了 2.6 倍,I/O 数量提升了 6 倍。尽管三星目前专注于智能手机等移动平台,但这种方法对于高功耗工作负载也同样具有应用前景。我们相信,VCS 及类似技术能够帮助未来的 AI 加速器在更低的功耗和更小的占地面积下实现更高的带宽,同时还能支持服务器 CPU 所需的高密度内存模块,例如 SOCAMM。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4456内容,欢迎关注。
推荐阅读
★
★
★
★
★
★
★
★

加星标⭐️第一时间看推送













