一水 发自 凹非寺
量子位 | 公众号 QbitAI
当AI公司还在读论文,Bio公司已经让AI做完了实验。
没错,又一热门AI赛道,被国产玩家率先跑通了——
AI for Bio,生命科学领域。

时至今日,这个赛道几乎挤满了最不缺算力的一批硅谷玩家:
OpenAI发GPT-Rosalind,专攻药物发现和基因组学;谷歌推Co-Scientist和ERA,把多Agent系统塞进科学推理流程;Anthropic上线面向科研流程的Claude Science工作台。
虽然大家想的都是让大模型读完论文后,写个「完美」的实验方案,再真正走进实验室,但奈何现实很骨感:
真正让AI接管实验室并跑通实验的?约等于无。
就拿最接近终点的OpenAI和Ginkgo Bioworks的合作来说,GPT-5在那个项目里负责的是实验设计和参数探索,真正在实验台上执行的Catalyst protocols,全部由Ginkgo的人类工程师编写。
换句话说,强如OpenAI,模型也没有真正接触到「做实验」这一层。

△图源:OpenAI官网
不过现在,全球第一个补上这关键一步的来了。
华大智造子公司涌生智能×上海人工智能实验室,联合发布两项新成果:
ProtoPilot:一款由真实实验室场景驱动的自进化多智能体系统; BioLab Bench:生命科学领域首个从用户需求到设备可执行的全流程Agent评测体系。
从自然语言实验意图到湿实验物理执行,完整闭环,真实验证。
这一次,让AI「真正走进实验室」的不是哪家AI巨头,是一家跨界做AI的中国Bio公司。
这事估计连老黄都没想到:
年初他在CES上说,「Physical AI的ChatGPT时刻」到了,说的是机器人和自动驾驶。
但是现在,第一个在生命科学实验室交出Physical AI答卷的,来自深圳。
AI for Bio,到底卡在哪了
为什么硅谷这帮最不缺算力的玩家,集体卡在了实验室门口?
要回答这个问题,其实只需要弄清楚一件事:
从模型到实验室,这中间到底缺了什么?顶尖模型在手,怎么就跨不过这道坎呢?

让我们从AI for Bio这个赛道的真实进展说起。
过去几年,AI在生命科学领域的应用多聚焦于「理解」和「分析」。
文献阅读、知识问答、序列比对、蛋白质结构预测,模型确实博学,但它本质上是个坐在屏幕后面的助理。
它能帮你理解世界,但还没真正进入世界。
Agent时代来了之后,事情开始变了。AI不再只满足于回答问题,它开始「设计和行动」。
应此潮流,以OpenAI、Anthropic为代表的前沿AI玩家,开始把目光投向更下游、更主动的方向:
假设生成、实验设计、参数空间探索、药物发现、蛋白工程、自动化实验。
听起来是不是已经很接近「让AI进实验室干活」了?
但现实情况是——还差得很远。
当下AI for Bio最真实的现状就一句话:能出方案,出不了结果。
能力达到博士级水平的顶尖AI,确实能写出一段看起来专业的实验方案,但写得好≠跑得通。
 △图片由AI生成
△图片由AI生成
这中间几乎隔着一整条转换链。ProtoPilot的论文拆得很清楚:
一个实验意图要变成湿实验台上的真实操作,需要穿过五层——科学意图、Protocol(方案设计)、SOP(标准操作流程)、设备代码,再到物理执行和反馈修正。
而每一层都要解决不同的模糊性,比如Protocol要表达生物逻辑、样本谱系和质控结构;SOP要把逻辑落到可操作的体积、浓度、耗材和温控条件上;设备代码要绑定deck布局、孔位映射、液体处理动作和厂商SDK指令……
就这一套下来,只要有任一环节出错,实验就可能失败。
所以,当AI for Bio的竞争从「模型能不能回答生命科学问题」转向「模型能不能走完从屏幕到实验台的全链路」时,行业真正缺的也就浮出水面了。
一块是「铲子」,能接住模型输出、连接专家、设备和湿实验反馈的Bio Agent Harness。
没有这个,方案再漂亮也只能停在屏幕上。
一块是「尺子」,能评价Bio Agent真实实验链路能力的benchmark。
不是考它做选择题,是看它生成的流程能不能在真实设备上跑得通。
现在公开的benchmark,比如ProtocolQA,考的还是阅读理解。
需要提醒,这两件事都不是坐在屏幕前就能凭空设计出来的,它们必须来自真实实验室:
真实任务、真实设备、真实约束、真实失败和真实专家判断。
所以现在你明白,为啥两家国产团队选择联手了吧(doge):
坐拥全栈生命科学设备、自动化实验平台、AI4Science经验和丰富真实实验场景的涌生智能,把最难被复制的「物理底座」和「场景底座」带了进来。
它不仅提供湿实验验证能力,更从真实用户需求、实验室约束和自动化执行逻辑出发,参与定义什么样的Protocol才算可用、可评、可执行。
上海人工智能实验室则基于其在大模型训练、评测标准和Agent框架上的积累,提供生成实验Protocol的模型基础,并与涌生智能共同构建Design2Protocol和Protocol2Code的benchmark、评分标准与评测工具。
两边一合,沉淀出了ProtoPilot和BioLab Bench。
Bio Agent,第一次真正走向了可评测、可执行、可迭代的真实实验闭环。
ProtoPilot和BioLab Bench,如何填补行业空白
ProtoPilot和BioLab Bench,具体如何填补行业空白?
我也去仔细扒了扒论文。
ProtoPilot:第三方测评超越OpenAI最强旗舰GPT-5.6 Sol
先说多智能体系统ProtoPilot。
目前AI for Bio赛道上,能打通Design2Protocol、Protocol2Code、设备执行与湿实验反馈验证的系统仍然极少,大多还停留在分段优化阶段,而ProtoPilot是少数已经实现全链路贯通的代表之一。
怎么个「全链路贯通」?举个例子:
当你用自然语言对ProtoPilot说「构建8个GLuc突变体」,它就能把这句话拆解成科学合理的Protocol,识别可用设备,转化为可执行的工作流代码,下发到物理设备执行,并根据湿实验反馈持续修正和进化。

注意,这不是聊天机器人,也不是单一设备的脚本生成器。
ProtoPilot背后是多个Agent在协同发力:
Orchestrator Agent统筹全局工作流状态,Protocol Expert Agent生成实验方案和SOP,Coding Agent将方案转化为设备可执行代码。三个Agent各司其职,逐层推进。
通过这种行业主流的「多Agent协同工作」方案,它成功解决了三个过去卡死行业的「老大难」。
第一个,需求模糊。
做过实验的都知道,很多时候你脑子里的实验意图往往只有个大概方向。
怎么将这种模糊意图转化为下一步具体行动?这便是Orchestrator Agent首先登场的原因。
Orchestrator本质上干的是实验室主管的活:
先把你的大目标拆成几个模块,每个模块单独细化成可操作的SOP,做完一个确认没问题再做下一个,最后拼成完整流程。
这样做的好处是,不会一上来就从头写到尾,写到后面发现前面的参数跟后面打架。
第二个,写得好≠跑得通。
Protocol写得再漂亮,真实执行还涉及孔位、体积、slot、耗材、温控、设备SDK、安全边界,一堆硬约束。
ProtoPilot的Protocol2Code环节,就是专门来啃这块硬骨头的。
怎么啃?Coding Agent拿到SOP之后,会根据你实验室里实际用的设备,把每一步操作翻译成那台机器听得懂的SDK指令。同一个「移液100μL」的动作,在MGI Prepall/AlphaTool上怎么写、在OpenTrons上怎么写、deck怎么排、孔位怎么映射,它都替你对齐。
翻译完还不算完,内置的验证器会逐条检查代码的安全性和可执行性,过不了gate的直接打回重写。
第三个,没有反馈闭环。
模型生成完方案就撒手不管了,错了也不知道错在哪,下次还犯。
ProtoPilot不一样,失败原因、专家判断、实验结果统统回流到系统,形成运行时技能学习。
换句话说,它越用越强。
就这几招下去,ProtoPilot能交出下面这份硬核成绩单,我是真不意外了。
做实验第一步,你得真懂实验。
别的不说,行业公认「试金石」ProtocolQA总得挑战一下吧。
ProtocolQA由AI4S领域的顶级机构FutureHouse推出,是专门考察AI对实验流程理解与故障排查能力的第三方独立benchmark。OpenAI家目前最顶的GPT-5.6 Sol的系统卡中也收录了该benchmark结果。
结果呢?
在开放式问答上,GPT-5.6 Sol得分43.5%,距离人类专家54%还有明显差距;而ProtoPilot拿到了52.38%,已经逼近专家水平。
在非开放式问答上, ProtoPilot更是取得了85.18%的成绩,已经超越专家水平。
在行业公认的第三方考卷上,跑赢OpenAI目前最强的旗舰模型,ProtoPilot的实力不言自明。
P.S. 归根到底,这背后其实是两条完全不同的技术路线在较量,先埋个钩子,后面详细揭晓。

有了这个大脑,方案生成自然能打。
在Protocol任务上,ProtoPilot综合评分94.7(满分100),在所有8个评估维度上几乎全线领跑。参数合理性98.9、方法学一致性97.7、内容完整性98.4,全部碾压通用大模型和专用Bio Agent。

盲评中,三位独立湿实验科学家在不知道系统身份的情况下,70.6%的情况将ProtoPilot排在第一,90.2%的情况将ProtoPilot排在前三。
从下图也能一眼看出,ProtoPilot生成的方案普遍更受科学家喜爱。

更关键的是,这个大脑能搞定最难的事。到了L3(最高复杂度) 任务这一档,差距变得极其夸张:
ProtoPilot的通过率依然有60%,而作为行业标杆的OpenTrons-AI直接归零。
如下图右侧的紫色柱子,OpenTrons-AI只能在自家设备使用,且完成不了复杂任务。

但光有脑子还不够,还得手脚利索。
考查代码转化和设备执行(图b)。Protocol2Code代码质量中位数95.5,Gate Pass Rate达到96.6%。
什么概念?第二LabScript-AI的通过率是64.6%,Grok-4.3只有35%,GPT-5.5只有17.7%,再往下基本是个位数。

跨设备迁移更猛(图c)。在MGI AlphaTool、Hamilton STAR、OpenTrons OT-2、Tecan EVO四个主流平台上,Gate Pass Rate波动仅5.9个百分点(pp)。作为对比,LabScript-AI的波动则高达47.1个百分点。
这里有个特别有意思的细节:
在OpenTrons OT-2上,ProtoPilot通过率88.24%,而OpenTrons官方自己的AI只有32.35%。
也就是说,ProtoPilot不仅在技术上实现了通用,而且赢了别人接近三倍。

BioLab Bench:首个从实验意图到设备执行的全链路评测体系
说完了选手,再说考场。
现有的第三方benchmark,比如刚才提到的ProtocolQA,考的还是实验理解和知识问答。
但AI for Bio真正要回答的问题,从来不是「你懂不懂实验」,而是「你能不能把实验跑出来」。
这就是BioLab Bench要填的坑,它衡量的核心只有一件事:
系统能不能在真实自动化设备上跑得通。

具体而言,BioLab Bench作为该领域首个覆盖从用户需求到设备可执行的全流程Agent评测体系,覆盖理解用户实验意图→Design2Protocol→Protocol2SOP→SOP2Code→设备code→真实实验执行链路。
任务范围从基础操作到复杂多步骤流程,按L1到L3难度分层。
和传统的生物benchmark的区别在哪?
以前的考试是做阅读理解,看你懂不懂实验原理,而BioLab Bench考的是真上手——
从实验意图到方案、SOP、设备代码,一路到真实执行,全链路打通。
而且它还能跨平台检验。
同一个任务,换到不同自动化设备上,看Agent能不能适配。
说到底,ProtocolQA这类测评考的是「知不知」,BioLab Bench考的是「做不做得到」。
不是纸面分数,是实验台上跑出来的闭环
系统有了,考场也有了,剩下的问题只有一个:在真实实验台上,能不能跑出结果来?
忙着「搭桥修路」这么久,总得让人看到实际成果。
ProtoPilot用四组递进难度的湿实验给出了回答。(P.S. 湿实验指真实实验台操作,和纯计算模拟相对应)
第一组是最基础的活儿,在96孔板里接菌培养。
没什么花哨的,就是看机器能不能按照指令把菌液加到每个孔里、能不能养出东西来。
结果96个孔全部生长,OD600读数稳稳当当。基础操作,过关。
第二组加了点难度,做了24个菌落PCR。
简单说就是挑菌、扩增、跑胶,看能不能拿到对的条带。
24个克隆,全部扩增出预期条带。机器移液、温控、试剂分配,都没掉链子。
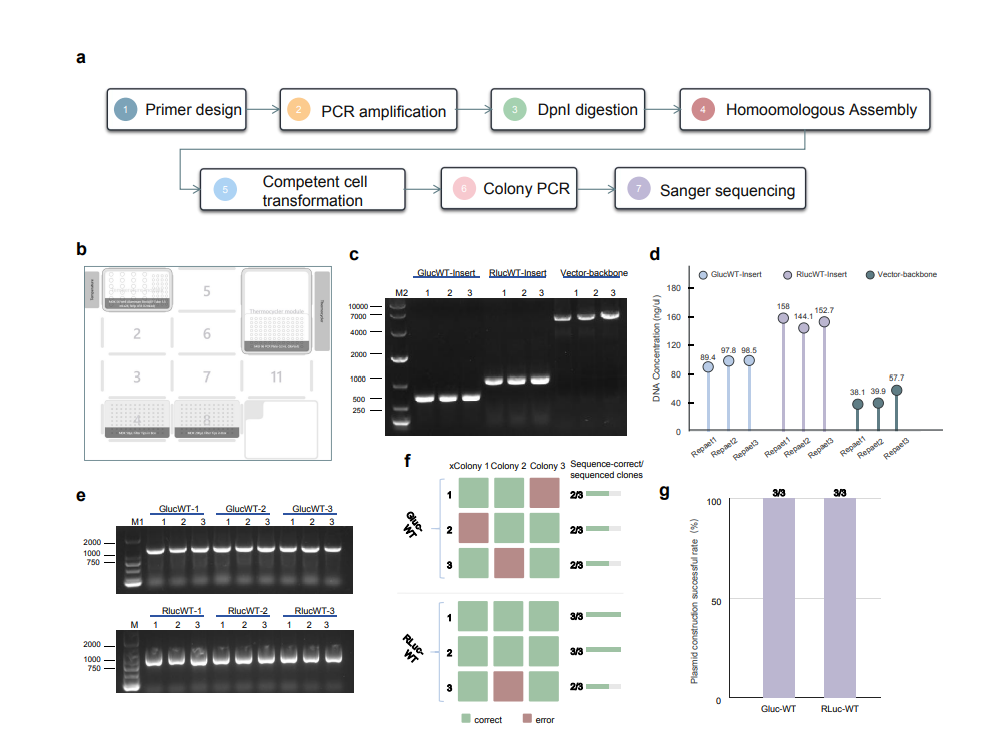
第三组是真正的分子克隆,质粒构建和定点突变。
说白了就是把一段目标基因装到质粒载体上,再精确地改掉其中某个碱基。
这里面涉及酶切、连接、转化、测序验证,每一步都得精准。
而ProtoPilot做的两个质粒,GLuc-WT和RLuc-WT,全部拿到Sanger测序确认。
往下再做酶的突变体质粒的构建,成功构建出15个sanger测序通过的突变体。
当然最能体现水平的还是第四组,基于PCA方法的DNA组装。
所谓PCA法的DNA组装,意思是你手头没有现成的完整DNA片段,而是要从一组短寡核苷酸开始,把目标序列一步步「组装」出来:设计引物、合成寡核苷酸、搭桥组装、纠错、扩增,再连到载体上、转化进细胞。
整条路七个步骤串下来,一步卡住全盘重来。
在菌落PCR实验一共挑选了96个候选克隆,93个阳性,初筛阳性率达96.9%,而Sanger测序结果也证明4条目标DNA序列全部构建成功。



(
左右滑动
)
更关键的是,这个系统还会自我修正。
论文里记录了一个细节:
第一轮PCA组装转化,培养皿上的菌长糊了,几乎没有可挑的单克隆。
系统自己分析了失败原因,判断是抗性筛选出了问题,然后重新生成修正方案。
结果第二轮跑下来,成功出现了许多可挑取的单克隆菌落,最终成功拿到了测序确认的DNA产物。
显然,这就不是纸面分数了。
这是从需求理解、流程生成、自动化执行、结果验证到异常修正的完整闭环,在真实实验台上真刀真枪跑出来的。
一家跨界AI的中国Bio公司,比Claude更先交卷了
系统跑通了,数据打完了,湿实验也验过了。
问题只剩下一个:为什么交出这份答卷的,是一家中国Bio公司?
答案想必你已经猜到了,因为做AI for Bio,最稀缺的从来不是模型,是场景和设施。
AI发展到现在,这个判断几乎成了各行各业的共识。
放在AI for Bio赛道,真实设备、真实湿实验、真实失败、真实约束……这些理论上归属于「生命科学实验室Physical AI」的部分,才是一个玩家所拥有的最大护城河。
模型可以买、可以训,但真实道路只能自己修。
正是在这样的背景下,涌生智能这家公司的出现也就不那么让人意外了:
一家从设备侧生长出来的AI公司,天然比从模型侧空降的玩家,更懂物理世界的语法。
 △图片由AI生成
△图片由AI生成
涌生智能,是今年3月由华大智造成立的子公司,专注AI4S领域,聚焦搭建面向生命科学的干湿闭环基础设施。
掌舵人杨梦,华大智造首席AI官,涌生智能CEO,是华大智造AI战略的核心推动者。
在此之前,他带队在Nature子刊发过EvoPlay(用强化学习设计功能蛋白的AI智能体)和PrimeGen(干湿协同多智能体系统),还主导开发了AI全栈接入的闪速测序仪E25 Flash。
因此这个团队做ProtoPilot这件事,并非从零起步,而是在多年AI+Bio实战经验上的一次集中爆发。
当然了,一家成立仅几个月的公司能快速拿出新成果,底气无疑离不开其母公司华大智造。
华大智造是全球率先集齐「全读长测序(SEQ ALL)+智能自动化(GLI)+多组学(OMICS)」三大技术板块的生命科技上游企业,手握PrepALL、AlphaTool、AIO一体机等Agent-ready智能实验自动化产品,截至2025年末已积累全球超3800家用户,以及十余年生命科学设备的工程化经验。
当这些设备能被代码驱动,Agent才长出了手;当SOP数字化、机器可读,Agent才听得懂实验的语言;当湿实验结果能被采集、回流成数字信号,Agent才睁开了眼睛。
所以,一切都很清楚了:
涌生智能赢就赢在,他们不是从外部给实验室装一个AI,是从实验室内部长出AI。
这是一条和硅谷完全不同的路线。
头部AI公司选择scale compute,用更大的算力推高通用模型能力;
而涌生智能则从真实实验世界出发,基于国产开源模型,结合自研Bio Agent Harness架构,通过真实实验数据回流与Agent协同驱动系统进化,将任务执行、设备约束、专家反馈与湿实验结果统一纳入训练闭环。
路线不同,结果说话。

而这种差异,也很快体现在产品层面:
ProtoPilot和BioLab Bench的能力,已经在向涌生智能的整个产品体系回流,构建起真正的干湿闭环。
这次发布后,向上让αLab Brain从「实验室助手」升级为可评估、可修正、可持续进化的「实验室伴侣」;
向下让AlphaTool、PrepALL、AIO等硬件设备通过Protocol2Code接入Bio Agent生态,从预设执行变成智能节点。
SE-Fab的DBTL闭环也因此越转越顺,每一次真实任务、失败修复和专家反馈,都沉淀为下一轮训练材料。
一条真正的干湿闭环,就这么接上了。
有意思的是,Anthropic的Claude Science平台瞄准的下一站,正是干湿闭环。

而涌生智能和上海人工智能实验室这次联合发布的,已经是干湿闭环了。
一家跨界做AI的中国Bio公司,不仅抢在硅谷前面交卷,更用一条完全不同的路线证明:
Bio公司在自己的场景里用AI做AI,确实比AI公司从外部攻进来更猛。
这出戏本身,已经足够精彩。
回到开头。年初黄仁勋在CES上说,Physical AI的下一站是机器人和工厂,但物理世界还有一块他没圈到的版图:
全球每天运转的生命科学实验室。
Physical AI的强弱,不看参数大小,看它与真实世界交互的深度。自动驾驶的能力来自真实道路,机器人的能力来自真实动作,生命科学的智能也一样——必须在真实实验室里才能长出来。
涌生智能和上海人工智能实验室的这次联手,释放了一个明确信号:
AI for Bio的竞争,正在从「谁的模型更强」转向「谁的闭环更完整」。
这一次,Physical AI真正长在了生命科学实验室里,而不是聊天框里。
论文:https://arxiv.org/abs/2606.31763
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟