随着 LLM Agent 在智能客服、个人助理、社交陪伴和医疗辅助等场景中的应用拓展,其交互模式正从单轮问答走向长周期、多任务的持续协作。
在这一过程中,Agent 的记忆模块不仅需要存储跨会话、多类型的信息,如对话内容、用户意图、实体状态和事件脉络,还需要在复杂查询中提供准确、可追溯且低延迟的证据支撑。
然而,当前主流记忆系统通常依赖向量数据库、图数据库和关系型存储的异构组合,容易造成记忆表示碎片化、跨库查询开销高;同时,其检索机制多采用 RAG 式的被动相似度匹配,容易引入噪声、遗漏关联线索且缺乏 Token 预算控制,导致检索质量不稳定。
针对这些挑战,中国科学院软件研究所等机构的研究团队提出了 Mandol:一种凝聚式内存原生分层记忆系统,其核心思想是将碎片化的记忆表示与异构存储凝聚为统一的内存原生架构。

论文标题:Mandol: An Agglomerative Agent Memory System for Long-Term Conversations
arXiv 论文链接:https://arxiv.org/pdf/2606.29778
项目地址:https://github.com/AgentCombo/Mandol

Mandol 通过分层记忆模型、统一内存语义数据结构和智能量化检索机制三方面协同设计,将碎片化的记忆表示与存储凝聚为统一架构,为 Agent 提供兼顾表示能力、检索效率与上下文质量的记忆底座。
在 LoCoMo 和 LongMemEval 两项公开长对话记忆评测基准上,Mandol 在所比较的代表性开源记忆系统中取得最优总体准确率;在以 GPT-4.1-mini 作为回答生成模型的设置下,其整体准确率分别达到 92.21% 和 88.40%。在 10 QPS(即每秒接收 10 个查询请求)并发负载下,Mandol 的平均检索延迟为 82.2 ms,相比最快基线实现约 5.4 倍加速;平均插入延迟为 39.7 ms,相比最快基线实现约 4.8 倍加速。并且,在消费级笔记本硬件上,Mandol 的延迟仍低于现有系统,展现出优异的端侧部署潜力。
从「碎片化存储」到「被动检索」:核心瓶颈在哪里?
实际应用中,Agent 面临的记忆查询复杂且多样,从简单的事实提取到需要多跳推理的复杂问题。尤其是以下三类查询,对记忆系统带来了严重挑战:
强时序性检索:如「去年暑假我去北欧旅行期间订了哪些酒店,总花费多少?」,系统需精准回溯用户在不同城市的多次住宿记录、准确关联时间与花费信息,并进行汇总。这要求系统具备对长周期内多个时序事件的精确提取与聚合能力。
跨会话多跳推理:如用户在一次会话中提及「我对海鲜过敏」,几天后又在另一会话中描述「吃完晚饭后皮肤起了大片红疹」。系统需将过敏史与当前症状进行跨会话的逻辑拼接与推理,得出可能的过敏反应结论,而非孤立地检索关键词。
动态状态更新与去噪:如用户的购房偏好从「郊区大户型」变更为「市区学区房」。系统必须准确跟踪状态变化,在回答「根据我的最新需求推荐几个楼盘」时仅依据最新约束条件,自动覆盖陈旧偏好,避免对当前决策的干扰。
面对上述需求,当前主流 Agent 记忆系统(如 Mem0、Zep、MemOS 等)在架构和检索机制上存在三个主要问题。
第一,记忆信息难以统一表示。向量嵌入支持语义相似性匹配,却难以显式表达逻辑结构与时序关系;知识图谱拥有结构化表达能力,但其固定模式对动态语义和演化支持不足。二者缺乏统一表征框架,导致记忆信息分散在不同结构中,查询时难以获得完整视图。
第二,跨库查询开销大。复杂的混合查询需要在向量数据库、图数据库和其他存储之间进行跨库编排,会产生高昂的序列化与 I/O 开销,难以满足低延迟交互要求。
第三,查询精度与 Token 消耗难以兼顾。传统 RAG 式「被动相似度匹配」检索存在两个突出问题:检索结果易引入噪声、冲突或遗漏多跳推理线索;Token 消耗缺乏有效约束,简单查询可能浪费上下文窗口,复杂查询的关键证据链却常因截断而丢失。
Mandol 的三项核心设计:表示、存储与检索的一体化设计
针对上述挑战,Mandol 从记忆模型、存储架构和检索机制三个维度进行了系统性设计。
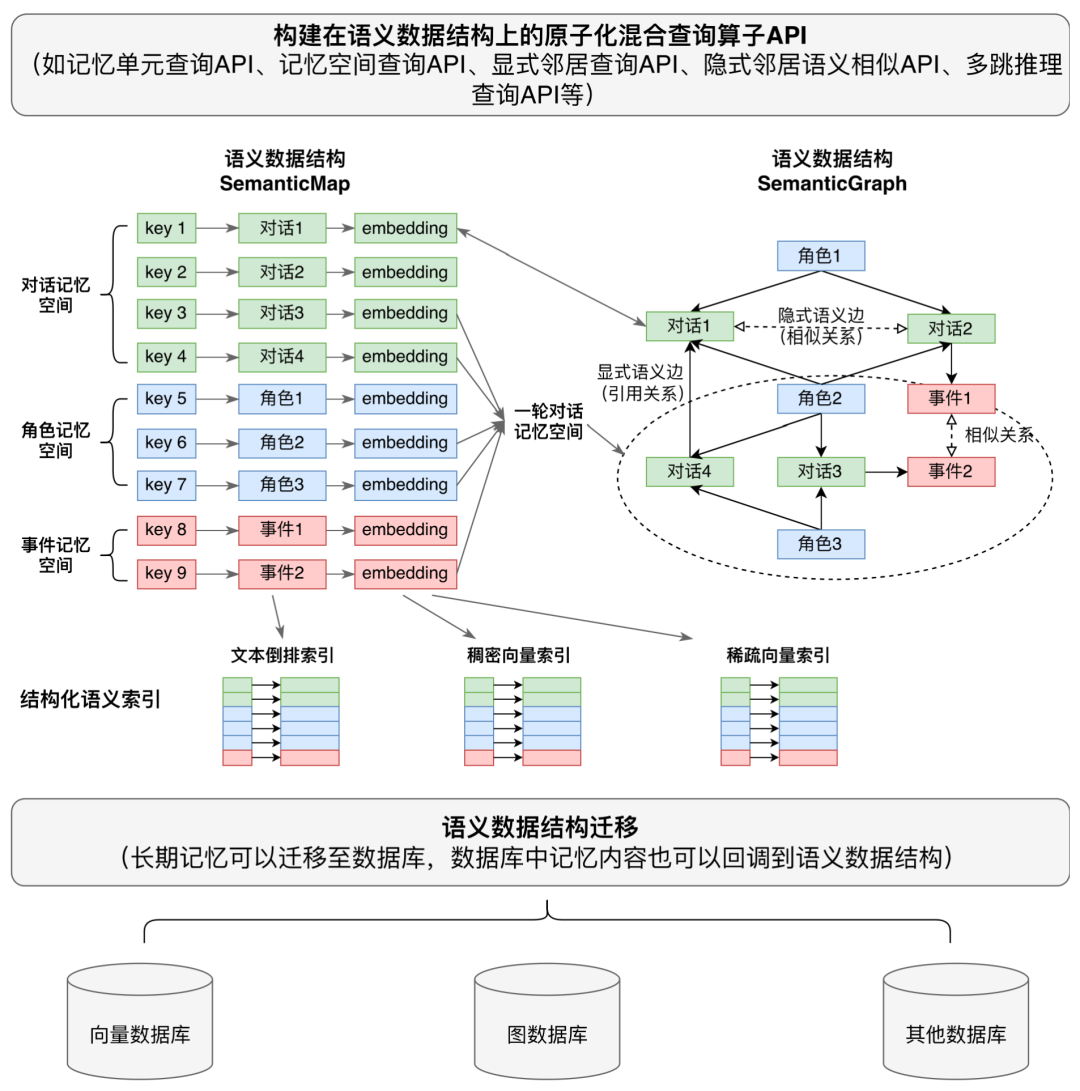
设计一:分层记忆模型 —— 以结构化语义图实现统一表征
Mandol 将记忆组织为两个层次:
基础记忆层负责直接存储原始交互信息,以记忆单元(封装原始信息与语义向量)、记忆空间(提供多粒度逻辑隔离)以及显式关系(时序、引用、状态更新等)和隐式语义关系,构建统一的结构化语义图。
高阶抽象记忆层则由大模型自动从基础记忆中提炼出情景记忆(事件链)、语义记忆(实体关系图)和情感记忆(用户偏好演化链)等抽象知识。
两层之间通过可追溯链接保持双向关联,确保任何抽象推理结论均可溯源至原始对话证据。这一设计既保留了基础层的完整信息,又提供了支持推理的高阶抽象视图,针对统一表示问题给出了一种系统化方案。
在结构化语义图中,基础层的记忆单元以节点形式存在,显式关系边通过规则解析直接建立,隐式语义边则在查询时按需从向量索引中获取。高阶层在此基础上进一步抽象:事件链以时序和因果边连接事件节点,实体图以引用和属性边组织实体关系,偏好演化链以状态更新边追踪用户偏好的变化轨迹。
例如,当一个简短的对话片段「预订了一间胡同民宿」被增强为带有时空上下文的事件节点后,Mandol 不仅将其与同一次旅行的其他事件(如「航班延误」 「参观故宫」)建立时序边,还通过语义索引与之前会话中的「计划预订王府井酒店」建立跨会话的隐式关联,并在此基础上抽象出一条状态更新边,完整刻画住宿偏好从「王府井酒店」到「胡同民宿」的演化过程。所有抽象节点均保留指向原始基础单元的引用,为后续的精确检索提供了既细粒度又可推理的数据基础。

设计二:内存原生语义数据结构 —— 消除跨库查询延迟
异构多库架构是查询延迟的主要来源。针对这一问题,Mandol 提出了基于内存语义数据结构的统一存储架构,设计了 SemanticMap 与 SemanticGraph 协同工作的原生内存数据结构,在单一地址空间内实现键值存储、向量索引与图结构的原生融合。
SemanticMap 融合传统键值存储和向量结构,解决记忆单元的多模态数据存储与语义查询问题,并支持通过记忆空间标签进行上下文逻辑隔离;SemanticGraph 负责统一管理显式记忆关系与隐式语义关联:显式关系以结构化边直接存储在图中,隐式语义关联则依托 SemanticMap 中的向量索引按需检索并动态返回相似邻居,从而避免预先枚举和物化所有潜在语义边。两者相互关联,在物理层面实现结构化语义图的统一存储视图。
在此基础上,Mandol 提供了一套原子化混合检索算子,覆盖记忆单元查询、空间查询、关系查询和多跳查询等操作,将向量匹配、图遍历等操作统一封装为内存内的高效执行单元,显著减少了异构存储带来的高 I/O 延迟。此外,活跃记忆层通过异步分页机制连接嵌入式持久化后端 DuckDB,用于冷数据或长期存储。
设计三:智能量化检索机制 —— 在 Token 预算内构建高质量上下文
Mandol 将检索任务重新定义为「在有限 Token 预算下构建高质量上下文」,并构建了无需大模型介入的量化检索流程。
其核心方法是:首先通过查询自适应的智能路由进行预算分配与多源并行召回(即根据查询特征选取部分高阶记忆和基础记忆进行检索),确保记忆信息的完整覆盖;随后对召回结果进行记忆源内部量化去噪与跨记忆源冲突消解,去除噪声与冗余信息;最终在 Token 预算约束下完成上下文的精简与生成,兼顾相关性与多样性,从而在有限开销内获得高信息密度的证据上下文。

实验:总体准确率领先,效率大幅提升,部署友好
研究团队在 LoCoMo 和 LongMemEval 两项长对话记忆评测基准上对 Mandol 进行了全面验证。
在检索质量上,以 GPT-4.1-mini 作为生成模型、GPT-4o-mini 作为评估模型的设置下,Mandol 在 LoCoMo 和 LongMemEval 上分别取得 92.21% 和 88.40% 的整体准确率,在所比较的代表性开源记忆系统中取得最优总体结果。尤其在多跳推理、时序推理与知识更新等复杂查询类型上,Mandol 展现出较强优势。
值得注意的是,即使采用更轻量的检索后端模型(Qwen3-Embedding-0.6B 与 bge-reranker-v2-m3),Mandol 仍在总体准确率和多数关键任务上超过使用更大检索模型的对比系统,同时将 Token 消耗降低了 17.4%–20.0%。这一结果说明,其性能增益主要来自记忆组织与检索机制的结构性优势,而非单纯依赖更大规模的嵌入或重排序模型。

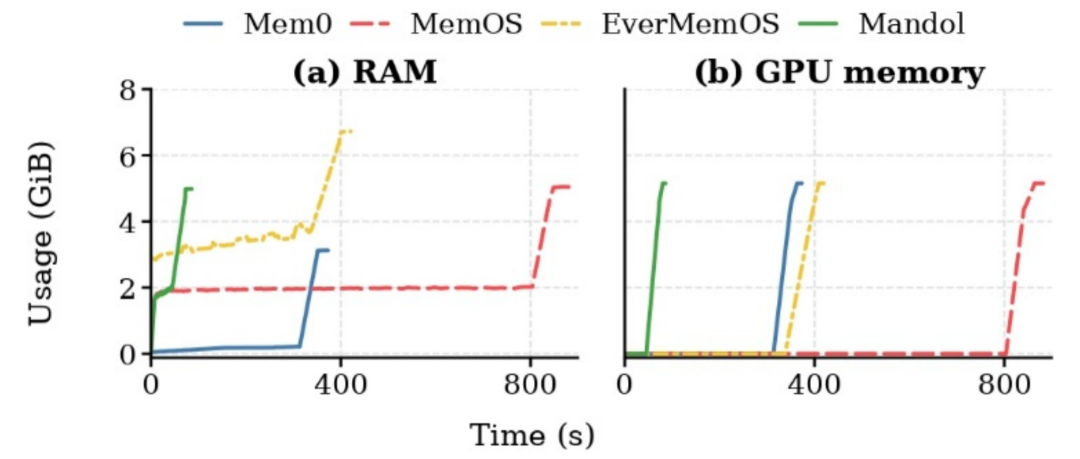
在系统性能方面,在 10 QPS 并发负载的服务器环境中(NVIDIA H800 GPU),Mandol 的平均检索延迟仅为 82.2 ms,相比最快基线实现约 5.4 倍加速;平均记忆插入延迟为 39.7 ms,相比最快基线实现约 4.8 倍加速。
值得注意的是,在本地消费级设备(笔记本 NVIDIA RTX 5090)的补充实验中,Mandol 的延迟仍低于现有系统,显示出优异的本地部署潜力。这种显著的效率优势,根源在于其进程内内存原生架构彻底避免了数据库往返和跨库协调开销。

在资源消耗上,Mandol 同样表现良好。其内存占用适中,且因消除了对外部数据库服务及其网络通信的依赖,完成标准长对话负载的整体耗时仅为对比系统的 1/4.2 至 1/9.9,展现出良好的本地部署潜力。
结语
Mandol 通过凝聚式的分层记忆模型、内存原生统一存储与智能量化检索三项核心创新,为 Agent 提供了一个兼顾高精度、低延迟和轻量化部署的记忆系统解决方案。该系统已在 GitHub 开源,便于研究者复现、试用和进一步开发。得益于内存原生架构,Mandol 无需依赖外部数据库服务,可在消费级设备上高效运行,为端侧 Agent 的记忆管理提供了新的可能。
对于正在构建需要可靠长期记忆的对话 Agent、推荐 Agent 或陪伴 Agent 等的研究与工程团队而言,Mandol 提供了一个兼具精度、性能和工程实用价值的选择。
【ICML 2026首尔 · 云帆AI Talent Meetup】最后报名中,快来晚宴现场Pick你感兴趣的同行者🍻~
7月9日晚,首尔ICML会场旁,上海人工智能实验室、上海科技大学、上海创智学院、阶跃星辰、Sharpa Robotics等20余家上海顶尖AI单位现场设展,开放100+岗位。专场招聘、学术分享、圆桌交流、自由Networking、晚宴一站式搞定。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com