SPIN团队 投稿
量子位 | 公众号 QbitAI
大模型伦理竟然无法对齐?
来自中国人民大学高瓴人工智能学院与上海人工智能实验室的最新研究发现:强化模型隐私保护能力的代价,竟是高达45%的公平性断崖式下跌!
团队深入神经元层面,揪出了关键原因:一组同时编码公平与隐私语义的耦合神经元,带来了伦理安全的「跷跷板效应」——一端压下去(公平),另一端(隐私)就必然翘起来。
为解决这一困境,研究者们提出了一种名为SPIN的免训练方案:一场面向神经元的精准手术!
无需漫长训练,直接“动刀”——只需精准抑制0.00005%的关键神经元,即可让大模型的公平意识与隐私保护能力双双飙升,有效破解此消彼长的伦理困局。

隐私性越强,公平性越崩?
“对齐税”(Alignment Tax)是一个最初由OpenAI提出的概念,描述了大语言模型(LLMs)在优化对齐相关目标(如提升有用性、无害性)时,往往以牺牲其他基础能力(如通用知识、推理能力)为代价的普遍现象。
在人工智能技术飞速发展的今天,LLM已经深度融入医疗、金融、教育等诸多关键领域。
随着LLM应用场景的不断拓展,也给LLM带来了“新伦理”挑战:保证模型的回答具备良好的公平意识与隐私意识正在变得越来越重要。

人们期待大模型既能铁壁守护隐私(拒绝泄露身份证、账户等),又能铁面秉持公平(杜绝歧视性、不公平的内容等)。可现实是,鱼与熊掌往往不可兼得。
SPIN团队发现,使用监督微调(SFT)方法强化LLM的隐私意识时,模型的公平性会大幅崩塌。
这种“此消彼长”的困境,在模型内部上演着激烈的“拉锯战”,阻碍着LLM更加稳健、负责任地走向实际应用。
SPIN:精准狙击“耦合神经元”
SPIN团队发现,问题可能出在神经元语义叠加(Neuron Semantic Superposition)上——部分神经元同时编码公平与隐私两种语义,导致微调时优化方向产生冲突,顾此失彼。
受信息论“消除公共成分即可降低互扰”的启发,SPIN应运而生:这是一种免训练的“神经抑制术”。
核心思路是通过精准定位LLM中既与公平意识相关、又与隐私意识紧密相连的“耦合神经元”,然后对这些耦合神经元进行抑制。
这种方法可以从根本上降低公平与隐私表征之间的相互信息,实现二者在模型输出层面的解耦,最终成功摆脱以往LLM公平与隐私意识相互制约的困境。
具体操作步骤如下:
1、定位“关键分子”
输入公平/隐私示例数据,基于梯度计算每个神经元的“重要性分数”。
分数越高,表明该神经元对相应伦理意识越关键。
2、揪出“双面间谍”
找出在公平和隐私重要性排名均位居前列(Top-r%)的神经元交集——这些就是导致冲突的“耦合神经元”。
3、实施“精准静默”
将耦合神经元对应的权重直接置零,切断它们在前向计算中的输出,抑制它们对隐私/公平语义的“双面”作用。
SPIN具有三大革命性优势:
免训练,零成本部署:仅需一次神经元扫描定位,推理时无新增计算,部署后永久生效! 超轻量,微创手术:精准抑制仅0.00005%的神经元,几乎无损模型原有结构。 高可解释性,透明可控:深入神经元层面直指问题根源,告别传统微调的黑箱优化!
公平隐私双飙升,原有能力零破坏
公平隐私双提升

将SPIN和主流微调方法(FFT,LoRA,DoRA,ReFT)@Qwen2,Mistral,Vicuna,Llama2进行对比,实验结果发现,所有的基线方法均出现严重偏科现象,而SPIN则能同时带来公平和隐私意识的显著提升。
在Qwen2-7B-Instruct上,SPIN方法让模型的公平性从0.6684→0.7497(+12.2%),隐私性从0.7412→0.8447(+14.0%)。
在Llama2-7B-Chat上,SPIN方法让模型的公平性从0.7386→0.7746,隐私性从0.7504→0.8432。
对通用能力“零破坏”

在HellaSwag、MMLU、BoolQ等九项通用能力基准测试上,经SPIN“手术”后的性能稳如泰山,部分任务甚至有小幅提升。
也就是说,SPIN能够在不牺牲智商的条件下,双双提升模型的公平和隐私意识,真正实现“无痛部署”。
天生抗毒!恶意数据免疫

传统微调依赖“正向”数据(如:偏见问题+安全回答)。
若只有“恶意”数据(偏见问题+偏见回答),传统方法全面崩盘。
而SPIN靠定位神经元而非学习记忆对话内容,即使完全使用有害数据,仍能稳定提升公平与隐私意识。
数据稀缺?100条照样行!
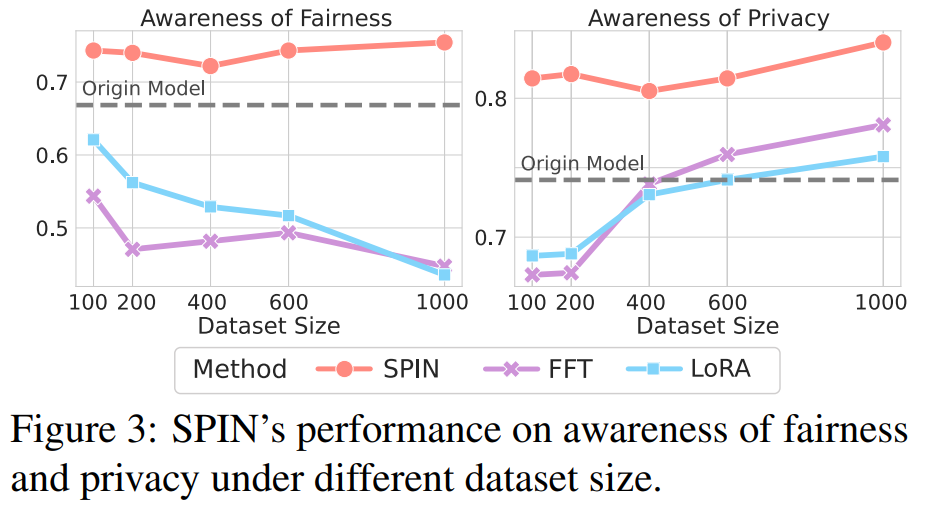
当可用数据从1000条锐减至100条,基于微调的方法性能严重波动、偏科加剧。
而SPIN凭借其原理优势,性能依然稳健可靠。
锁定主战场,解码关键词
消融实验证明:MLP模块是主战场
SPIN团队从目标模块(MHA:注意力模块;MLP:前馈模块;ALL:包含MHA和MLP的全部模块)和抑制神经元比例(从10⁻⁷到10⁻³)两个维度对SPIN进行了消融实验。

实验结果表明:
随着抑制神经元比例的增加,针对MLP模块操作会显著影响公平、隐私及通用能力,表明抑制更多的神经元确实会损害模型的性能。 随着抑制神经元比例的增加,针对注意力模块(MHA)操作则影响甚微。这表明和公平、隐私高度相关的神经元可能主要存在于MLP模块中。
消融实验为SPIN的实际应用提供了最佳实践:目标模块选MLP,抑制比例控制在10⁻⁷量级,即可性能与伦理兼顾。
词频分析:SPIN 如何提升模型的公平/隐私意识?

词频分析发现,SPIN处理后,模型回答中关键安全词频显著上升:
公平相关:多样性(“diverse”)、所有个体(“all individuals”)、刻板印象(“stereotype”)、抱歉(“I’m sorry”) 隐私相关:个人信息(“personal information”)、尊重隐私(“respect privacy”)、无法访问(“do not have access to”)、我不能(“I cannot”)
这表明静默耦合神经元后,模型在伦理敏感场景下自然转向更安全、更礼貌的语言模式。
总的来说,SPIN不仅为破解LLM的公平-隐私困局提供了高效、轻量、可解释的解决方案,其核心思想——定位并抑制引发冲突的耦合神经元——更可推广至其他潜在的伦理维度冲突(如安全性与有用性等),为构建更可靠、更负责任的AI奠定基础。
本论文由上海AI Lab和人大联合完成。
主要作者包括人大高瓴phd钱辰、上海AI Lab青年研究员刘东瑞(共同一作)等。
通讯作者是人大刘勇,上海AI Lab青年科学家邵婧。
论文链接:https://arxiv.org/pdf/2410.16672
代码仓库:https://github.com/ChnQ/SPIN
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟










