智谱发布GLM-4.5,又一个高效且顶尖的 AI 模型。
在 Meta 的 Llama 模型显得黯然失色的这一年,中国的开源 AI 模型却大放异彩,其光芒足以挑战美国在人工智能领域的霸主地位。
作者:PATRICK MCGUINNESS
日期:2025 年 7 月 30 日
图 1. GLM-4.5 一次就写出了一个打砖块游戏,上手体验很棒。
新一轮中国开源 AI 模型浪潮
中国的 AI 实验室最近可以说是火力全开。仅仅在 7 月,就涌现了多个杰出的 AI 模型:
月之暗面 发布了 Kimi K2。 阿里 Qwen 团队 更新了 Qwen-3 2507 系列模型。 智谱 AI 发布了 GLM-4.5 和 GLM-4.5-Air。
Kimi K2 是一款很不错的模型,尤其在编程任务上,几乎达到了业界顶尖水平。
而 Qwen-3 系列,包括它的代码模型,表现更胜一筹。现在,GLM-4.5 的出现,又将标准提到了新的高度。
它是一款极为出色且高效的 AI 模型,在编程、推理、智能体任务等多个方面都游刃有余。

图 2. GLM-4.5 专注于在智能体、推理和编程等关键领域做到最好,并成功跻身顶级模型之列。更关键的是,它仅用 320 亿活跃参数就实现了这一点,运行效率极高。
GLM-4.5 的核心特性与实力
智谱 AI 的 GLM-4.5 是一款能力广泛的细粒度混合专家模型。
旗舰版的 GLM-4.5 模型拥有 3550 亿总参数和 320 亿活跃参数。同时发布的还有一个更小巧的 GLM-4.5-Air 模型,活跃参数仅为 120 亿。
这些模型都能在处理复杂任务的「思考模式」和用于快速聊天的「非思考模式」之间灵活切换。
GLM-4.5 专为智能体任务优化,效率奇高。它的使用成本甚至比 DeepSeek 还低,每百万输入 token 仅 11 美分,输出 token 仅 28 美分。
这个价格不仅低于 DeepSeek,甚至可以对标谷歌的 2.5 Flash-Lite。
但关键在于,你用几乎和 Gemini 2.5 Flash-Lite 一样的价格,却能享受到 Gemini 2.5 Pro 级别的顶级性能。
在各项专业基准测试中,GLM-4.5 的表现足以证明其实力,其分数与 o3、Claude 4 Opus、Gemini 2.5 Pro 等业界顶尖模型不相上下。
当然,是骡子是马还得拉出来遛遛,GLM-4.5 需要在真实世界中接受更多检验。
但从团队公布的覆盖编程、推理、智能体等多个维度的全面测试数据来看,他们并非在玩选择性营销的把戏。

"图 3. AI 分析基准指数高达 67.7,优异的基准分数让 GLM-4.5 稳居顶级 AI 模型的第一梯队。")
尤其值得关注的是 GLM-4.5 在编程和作为智能体方面的表现。智谱 AI 团队提到:
GLM-4.5 是一个为智能体任务优化的基础模型,它支持 128k 的超长上下文和原生的函数调用能力。在两大权威智能体能力基准测试中,GLM-4.5 的表现与 Claude 4 Sonnet 并驾齐驱。
随着 AI 智能体的大规模应用,token 消耗量暴增,成本控制成为关键。
智能体应用迫切需要一款高性价比的 AI 模型。一个成本低廉、工具调用能力又强的模型,可能会彻底改变这个领域的游戏规则。
同样,最近这三款来自中国的 AI 模型,在编程方面的表现都堪称惊艳。
在 SWE-bench 代码能力测试中,它们的得分都非常接近当前该领域的领导者 Claude 4 Sonnet。
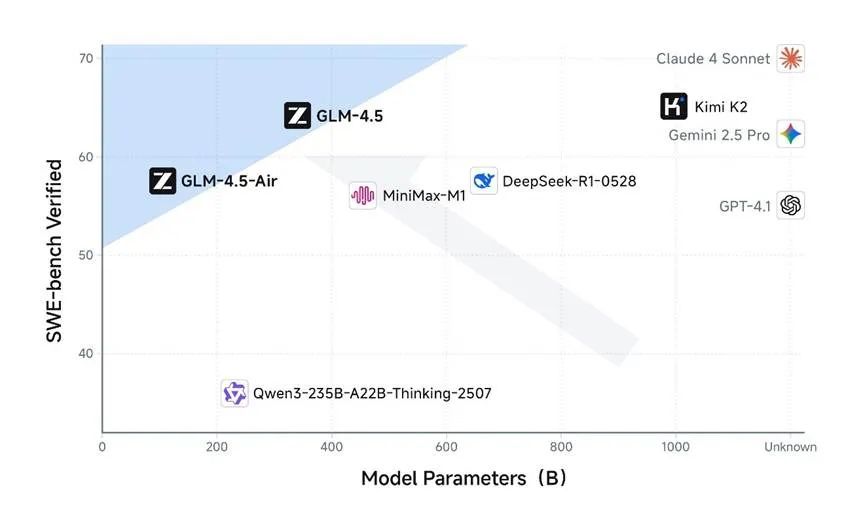
"图 4. 在同等规模下,GLM-4.5 和 GLM-4.5-Air 是最强大的开源代码模型,其综合实力已非常接近业界标杆 Claude 4 Sonnet。")
一位开发者 Daniel Vila Suero 在 X 平台上分享了他的体验:「在我的动画 SVG 上手测试中,它比 Kimi K2 好太多了。」
GLM-4.5 模型已经开源权重,可以在 HuggingFace 和 ModelScope 上找到。
虽然作为大型混合专家模型,普通电脑跑不动,但你可以在一台配备 128GB 内存的 M4 MacBook 上顺畅运行 GLM-4.5-Air。
你也可以通过 Z.ai 的官方 API 或 OpenRouter 等第三方平台来体验它。截至本文撰写时,OpenRouter 上的 GLM-4.5-Air 模型可以免费试用。
智谱 AI 的技术传承
智谱 AI (Z.ai) 脱胎于清华大学的知识工程实验室,这是一个在 AI 领域深耕多年的顶尖团队。
这个实验室自 2021 年起就开始打造 GLM 系列模型,并开源了大量代码、模型和数据。
在今年 4 月,他们发布的 GLM-4 32B 模型,性能就已经可以和 OpenAI 的 GPT 系列及 DeepSeek 的模型相媲美。

"图 5. 从 2021 年 3 月的初代模型到 2024 年 6 月,GLM 系列模型的演进之路。")
架构与技术细节揭秘
智谱 AI 和其他中国实验室的历史表明,他们在短短两年内取得了惊人的进步。
他们已经从模仿和追赶,转向在 AI 架构、训练和推理方面做出重要的原创性创新。
当美国的顶尖 AI 公司对前沿技术越来越讳莫如深的时候,中国的实验室却依然保持着开放和分享的态度。
在智谱 AI 的技术报告中,他们分享了 GLM-4.5 训练过程中的诸多细节。
这些新一代的中国模型,普遍采用了更高效的细粒度混合专家架构。
在训练阶段,模型首先学习了 15T token 的通用知识,再用 7T token 的代码和推理数据进行强化。
随后,团队通过一个被称为「中期训练」的阶段,用海量的代码、合成推理数据和智能体数据,对模型的专项技能进行精雕细琢。

"图 6. GLM-4.5 的预训练数据量不算巨大,但通过“中期训练”环节,精准地强化了核心能力。")
他们还大规模地应用了强化学习技术来突破模型的能力边界。
为此,他们开发了一套创新的两阶段训练后方法:先分别训练出推理、智能体、通用任务三个「专家模型」,再通过「自蒸馏」技术将所有能力融合回一个模型中,最后再进行多轮强化。

"图 7. 先分头培养专家,再集众家之长于一身,最终锤炼出全能的 GLM-4.5。")
“快速追随者”与中国 AI 的独特赛道
GLM-4.5 的强大实力,因其开源而更具价值。它让我们有机会一窥顶级模型的内部构造和训练方法,而这些正是那些闭源开发者从不分享的秘密。
这一系列发布不禁让我们思考:美国 AI 实验室的核心优势到底是什么?
如果说是算力硬件,DeepSeek 已经证明了中国团队能用更少的资源办更多的事。如果说是人才,全球各地涌现的优秀模型表明,顶尖人才并非少数公司所独有。
即使中国曾是追随者,他们也已成为最快的追随者。
更重要的是,通过更加开放地分享,整个 AI 领域得以加速前进,形成了一个良性的创新飞轮。每个团队都能从他人的成果中学习,从而更快地进步。
这种发展速度意味着,就算 OpenAI 的 GPT-5 未来技惊四座,或许只需 6 个月,我们就能看到来自中国的、成本更低、速度更快、性能同样出色的开源模型。
当 AI 智能体进入大规模生产应用,成本将成为王道。
低成本、高效率、在代码和智能体任务上表现卓越——这正逐渐成为中国 AI 的独特优势和赛道。在一个由数十亿智能体构成的未来世界里,这样的模型将至关重要。
因此,中国的 AI 实验室及其最新模型,不仅是全球 AI 用户的福音,也对 OpenAI、谷歌和 Anthropic 等传统巨头构成了日益严峻的挑战。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










