作者 | 叶子先生 编辑 | 大模型之心Tech
原文链接:
https://zhuanlan.zhihu.com/p/19341570384
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
1.概览
CLIP(Contrastive Language-Image Pre-training)即语言-图像对比预训练模型,是OpenAI在2021年提出的一种多模态预训练模型,它通过对比学习将文本和图像进行关联匹配,通过向量的模式将其投射在同一个向量空间内,以完成检索、识别、分类方面的工作。
★CLIP:连接文本和图像-openai(https://openai.com/index/clip/)
对于标准的CV模型,它往往只在小范围内任务和目标内work,对于分类问题,他需要基于高昂成本创建的数据集进行训练,以擅长这类数据内的分类工作,而对于新任务,例如不存在于训练数据中的物体,往往没有较好的泛化能力(zero-shot),CLIP的提出旨在解决这类问题。
它使用互联网上搜集的各种自然语言监督对各类图像进行训练,再根据自然语言提示对其进行分类。
简单来说,传统CV分类模型的能力是由数据集决定的,在预先构造好的数据集中进行分类,而对于数据集外的类别,基本不存在泛化能力。可以理解为,传统CV决定模型分类能力的基准是在确定数据集分类的类别时决定的,而CLIP的思路不同,他通过自然语言提示来进行分类匹配。
这里要确定的一点是,CLIP对标的是 图像分类模型 ,而不是 目标检测模型 ,这是两个概念。
2.CLIP是如何工作的
2.1.结构
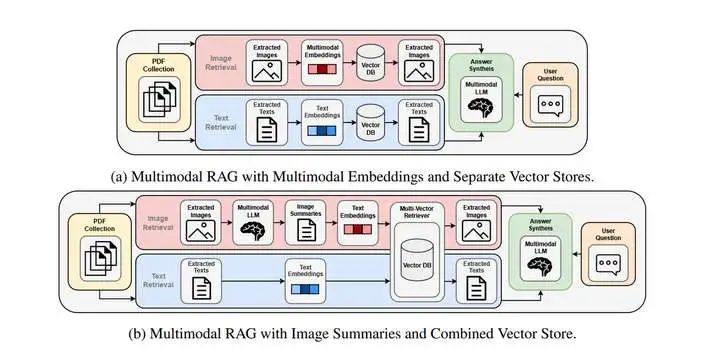
CLIP主要由两个模型构成,一个图像编码器Image Encoder和一个文本编码器Text Encoder。(可见2.2图)其中Text Encoder使用的是Transformer,而Image Encoder可以是Resnet也可以是Vit模型。通过将输入的图片和文本转化为向量来进行进一步操作。
2.2.如何训练(Train)
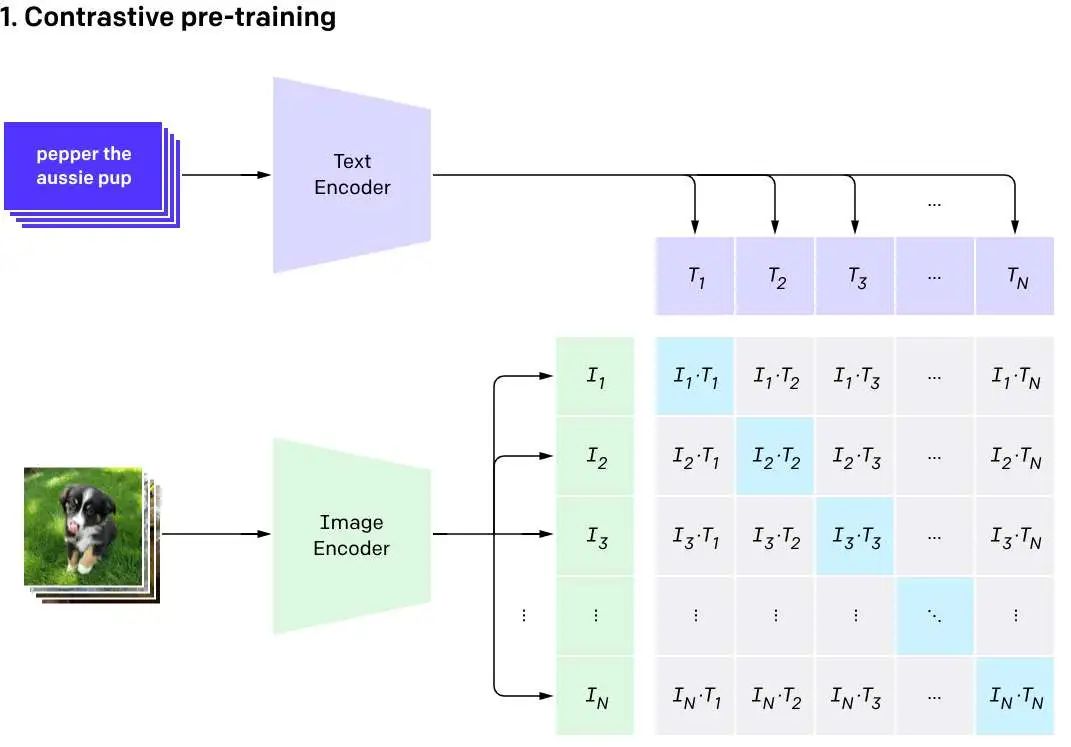
图中的Ix和Tx分别代表由图像编码器生成的编码和由文本编码器形成的编码,通过输入N对图像和文本的数据集,我们回得到N个图片编码和N个文本编码。对比学习需要正样本和负样本,而在这里,相互匹配的样本即为正样本,在图上表现为对角线的一串,Ii和Ti,而负样本则是出对角线外的其他样本。而预训练的目标,是最大化样本对的余弦相似度,最小化负样本的余弦相似度。
CLIP使用的是InfoNCE(Noise Contrastive Estimation)损失函数。
OpenAI构建了一个从互联网搜集的拥有4亿文本-图像对的数据集,称之为WebImage Text。
2.3.如何推理(Inference)
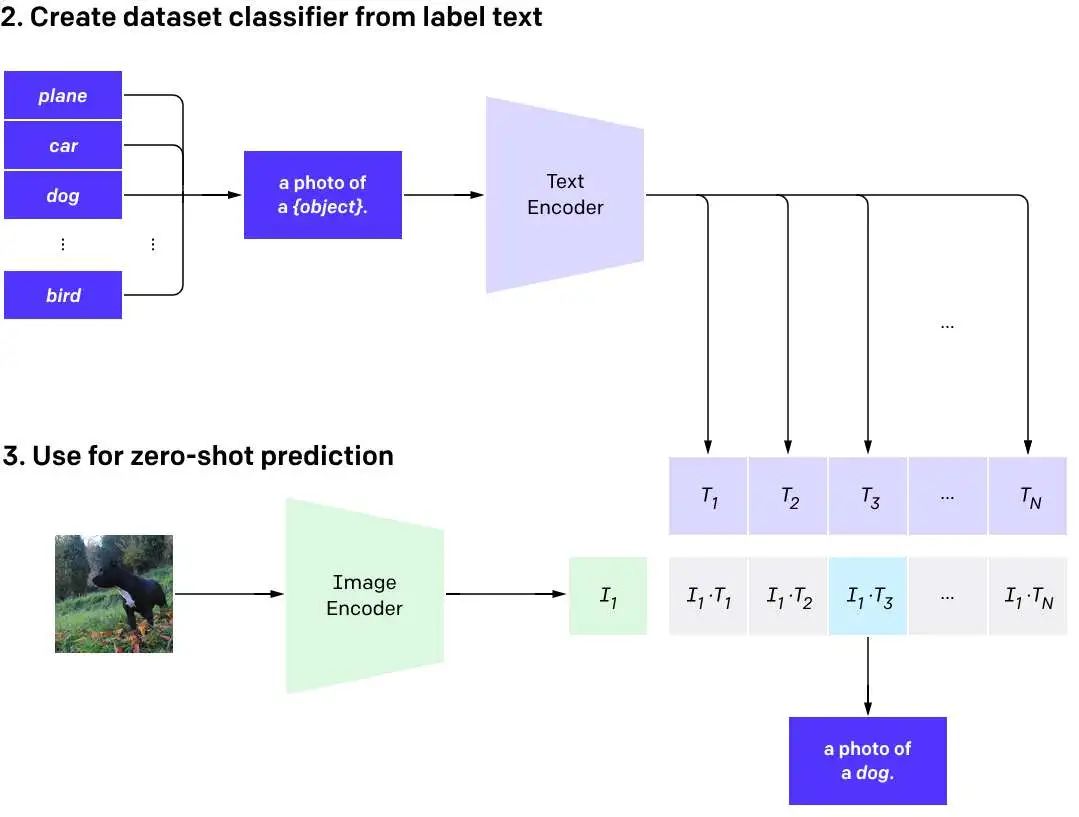
推理阶段,针对提供的文本输入集合通过文本编码器构造一个Tx的编码集合,再对提供的图片通过图片编码器构造一个I1的编码。通过计算I1和Tx中每个元素的余弦相似度,来得到最相似的那个描述类别。
实际上这里给出的推理是对图片分类的一个实例,CLIP模型的灵活性实际上还可以做到通过单个文字去分类多个图片,也就是文搜图,当然,也可以做到图搜图,文搜文。由于结构的灵活性,他在跨模态任务中能做的很多,因为它把输入都投射到了同一个向量空间内。
3.优势
3.1.跨模态
CLIP本身与传统CV分类模型最大的区别就是它是一个跨模态模型,因为他不要求输入的格式类型,它的输入可以是图片也可以是文字,通过将两者投射到同一个向量空间内进行操作。
传统的CV模型,它只能接受图片作为输入,结果输出一系列预设的标签和概率值。
3.2.Zero-shot能力
Zero-shot能力是指为模型在面对训练阶段从未见过的概念或类别,依旧拥有一定的准确性和处理能力,可以简单理解为极端的泛化能力(可以在完全没有见过的数据上完成任务和保证准确)。
CLIP的Zero-shot能力可以理解为它不再依赖于预设好的类别标签信息,而是面对从未见过的图像输入或文本输入,一样能够完成需要匹配相似度来进行的任务,例如分类,搜索。
但实际上这个Zero-shot有些投机取巧,一方面是预训练使用的数据集规模极大,另一方面是它是依赖文本作为提示输入的,并不能非启发性的输出结果。
3.3.开放性
CLIP的思路十分巧妙,与其说是提出了模型倒不如说是提出了框架,因为它的核心不在两个编码器内部的结构上(虽然结构会影响具体的性能),而是在于投射向量后计算余弦相似度得到输出。
顺着这个思路,实际上可以将任意两种模态作为输入,只要能够被编码为期望格式,例如把图编码器换成视频编码器、音频编码器,然后使用对应数据进行训练。
另外,对于编码器本身也有充足的灵活性,不需要一定是Vit编码器,也可以是ResNet,也可以是其他的网络结构。因此,实际上CLIP模型的大小可以按需调控(训练前),通过控制编码器的大小,来灵活控制模型大小。
3.4.轻量级
CLIP模型的结构极其简单,而模型参数量直接跟编码器的选择挂钩,因此模型可以做到轻量级(相较于生成式模型),模型的参数量级一般在1B以下,最小的可以接近100M左右。
4.缺陷
4.1.语言局限性
用于训练CLIP的数据为WebImage Text数据集,是一个以英文-图像对为主体的数据集,实际上原生的CLIP模型对语言是敏感的,在英语上的表现是明显优于其他语种的,当然,数据集中也含有其他语言类型的数据对,例如法语、中文、日语等,这使得其在一些通用的其他语种上也能一定程度的工作,但效果要差于英语。
因此,一般针对不同语种会有专用的CLIP模型,它们都基于各自语种的专用数据集进行训练。不过当前也有一些支持多语言的CLIP模型,例如jina-clip,它在非英文的语言上做过基准测试。
模型:https://huggingface.co/jinaai/jina-clip-v2
报告:https://jina.ai/news/jina-clip-v2-multilingual-multimodal-embeddings-for-text-and-images/
4.2.数据局限性
训练方面
CLIP使用的数据集是一个4亿对的图像-文本数据对,OPENAI也在报告中提到过之所以选择自己构造数据集,实际上是目前现存的开源数据集很大一部分都不能满足它们的需求(量级方面),所以如果自己做预训练的话,对数据的要求还是很高的,而又不像chat类模型那样,可以走无监督(意味着只需要文本进入,不需要传统意义上的“标记”),所以构造这样一个数量上符合要求的文本-图像对是要花很大成本的。推理(使用方面)
在实际的使用中,由于模型的架构,也有一些数据上的限制。
输入阶段,因为CLIP文本侧使用的是经典的Transformer设计,所以也有token的限制,在论文中有提到,数 值是77,也就意味着超过77的部分将会无效或截断,但实际测试下来,似乎在20左右的token,CLIP就会变得不敏感,所以实际上对输入的要求是很高的,对于长而复杂的输入,很可能会无效。
这个缺点可以通过工程上的手段进行修复,例如分词,去停止词等,但这个数值还是太短了。当然,CLIP的开放性使得其可以更换Text Encoder的模型类型,不同参数量级的模型也支持不同长度的token。
在数据的构造阶段,尽管CLIP有着不俗的zero-shot能力,但在面对领域数据的时候,还是远远不足以达到稳定可用的地步,例如对于飞机型号的分类等任务,这类任务可能还是需要进行领域数据的微调,才能使得CLIP真正可用。
4.3.复杂任务不敏感
一个比较重要的问题是,CLIP对复杂任务类型并不是那么擅长。
什么对CLIP算是复杂类型的任务呢,具体的prompt中含有明显的关系,方位,数量这类的信息时,CLIP往往对其不是很敏感。
对于这些类型的任务,通俗的举个例子:
以Chinese-CLIP为例,实际展示几个case:

以上六张图,从左到右、从上到下依次是:“猫在草坪上”,“猫在水泥地面上1”,“猫在水泥地面上2”,“两只猫”,“旗子在人左边”,“旗子在人右边”。
每张图片下方是针对输入prompt的概率(这里的概率做了归一化,并不能直接理解为相似度),测试如下:
1.否定关系


2.位置


5.衍生
5.1.多语种的CLIP模型
中文CLIP,Chinese-CLIP:https://github.com/OFA-Sys/Chinese-CLIP
英文CLIP,openai-clip-large:https://huggingface.co/openai/clip-vit-large-patch14
多语种CLIP, jinjia-clip:https://huggingface.co/jinaai/jina-clip-v2
5.2.BLIP系列
★BLIP论文:https://arxiv.org/pdf/2201.12086
BLIP(Bootstrapping Language-Image Pre-training)是脱胎于CLIP的一个新的多模态模型方案,直译应该是自举语言-图像预训练模型,BLIP1由Salesforce在2022年提出,后续还有迭代优化的BLIP2,BLIP在基于CLIP的架构上,设计了三个任务,分别是ITM、ITC、LM,可以说是之后多模态大模型的启发者之一。
LTC可以简单理解为就是CLIP本身,而他跟CLIP的最大不同其实就是两点:1.提出ITM,这是一个二分类任务,它能捕捉图像中更深层和细节的信息用于判断promp是否与图像Mapping,与ITC有相似,但不完全相似,理论上说,在分类任务上的精度应该会更高。2。融合LM,能够进行生成类的任务,可以进行文本生成来描述图像本身。
具体的技术实现、训练就不过多分析,这里只说一个比较核心的模型结构:
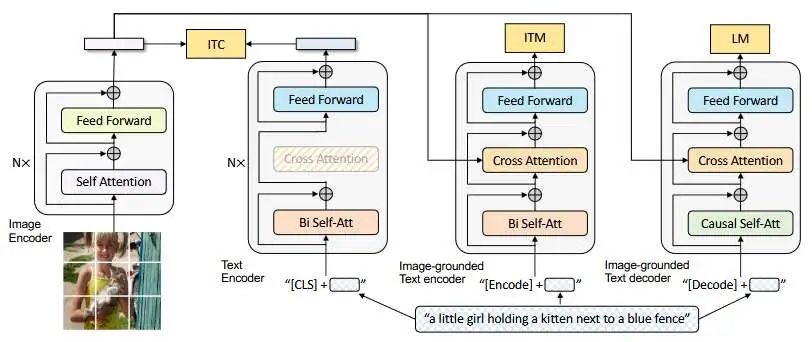
最左边就是ImageEncoder,右边三个分别是ITC、ITM、LM任务,相同颜色的部分共享参数。
ITC就是CLIP中,两个Encoder进行匹配,训练,投射向量进行相似度计算。 ITM意为Image-Text Mapping,它学习图文输入更细粒度的特征,它是一个二分类任务,它通过Cross Attention来对齐文本和图片中更细粒度的信息,以输出二分类的结果。 LM就是文本生成任务,使得模型学习如何通过给定图片生成连贯的描述。
后续的还有BLIP2和一系列衍生,这里不过多赘述。
6.与RAG结合的思考
6.1.可行性
首先,可行性方面,CLIP与RAG的结合场景应该是与图片有关的多模态召回过程,而CLIP的流程设计也是通过向量化来计算相似进行检索的,可以说跟RAG一模一样,只是数据形式上有区别。
CLIP模型本身的开放性又强,理论上通过更换Encoder可以实现几乎任意模态的数据召回,但前提是有足够的数据来训练或者有存在的预训练模型。
当然召回是召回,具体到理解生成就是另一回事了,大体上CLIP是可行的,但依旧能遇见到一些比较显著的问题。
这里需要注意的一个点,也是传统RAG的一个很重要的点,就是召回内容是 “相似” 而非 “正确” ,也就是说通过这种手段检索到的数据仅仅是它们很相似,但不代表他们就是问题的答案或者正确的相关信息。这一问题可能在图片的召回过程中更显著一些,因为跨模态的语义相似肯定是要比单模态的语义相似偏差更大的(图像的语义模糊性和多义性更大)。
另外,如何有效的召回数据也是一个问题,文本类的数据可以通过现有的一众rerank模型进行精排,但针对图片这种多模态数据要如何处理,还是个问题,因为目前还没发现支持图片+文本的多模态rerank模型。
6.2.存储
存储方面,存储图像和向量本身不是一件难事,有太多的方式存储图像和向量以及他们之间的关系了。
主要的问题是如何设计存储的结构,因为文本嵌入得到的向量表示和CLIP得到的向量表示首先在实际的向量空间上就不共享,其次是他们的维度也可能不相同长度(如CLIP默认是1024维,文本嵌入一般是768或者1536) ,实际到召回中,也要用各自的嵌入方法进行相似度匹配,这更像是一个并行的流程。所以是否共用一个向量数据库,如何设计召回时的逻辑,就成了一个问题。
6.3.如何有效召回
如何确保图像的召回数据有效呢?召回这个流程在总体上一定是可行的,但是如何与文本的多路召回融合呢?如何进行rerank呢?如何触发图像召回呢?
目前针对text的rerank模型已经有很多很多了,无论是开源还是闭源的,但多模态的rerank模型好像迟迟没有身影,等不到消息,因此目前也没法断言图片+文本能否一起进行rerank,那么如何构成结果集呢?无论是条件控制还是固定比率之类的,都显得不那么优雅。
另外,如何触发图像的召回呢,对于文本数据,稀疏向量和稠密向量的混合检索在目前的设计中是一体的,但面对图像数据要如何确定这个比率,面对有条件限制的召回,图像召回这一条路径又要怎么处理,是一定需要这个图像的召回么,目前能想到的可能就是意图识别来触发了。
6.4.是否有效提升
有一篇论文实验针对纯文本RAG、纯图片RAG和多模态RAG做了基准测试和实验,也提供了设计的多模态RAG的结构以供参考,其中图像相关的就使用的是CLIP模型,以验证融合了多模态的RAG系统是否有实际意义上的提升。
★Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
论文中设计的结构为:

A,B两种结构分别是:
A在存储策略上,文本数据和图像数据分开存储,同时使用CILP这类的多模态嵌入来处理图片数据,存储到单独的向量数据库内,而文本数据正常使用text-embedding进行嵌入,存储在单独数据内。在处理query时,对两者进行召回,确保检索到图像和文本结果。 B在存储策略上,文本数据和图像数据共同存储在一个向量数据库内,对于图像的处理,使用多模态大模型对其进行描述总结后,再进行文本text-embedding进行嵌入。在处理qeury时,仅对一个向量数据库进行召回,直接检索最相关的文档,无论是图片还是文本。
对于结论,直接看这两幅图表即可:
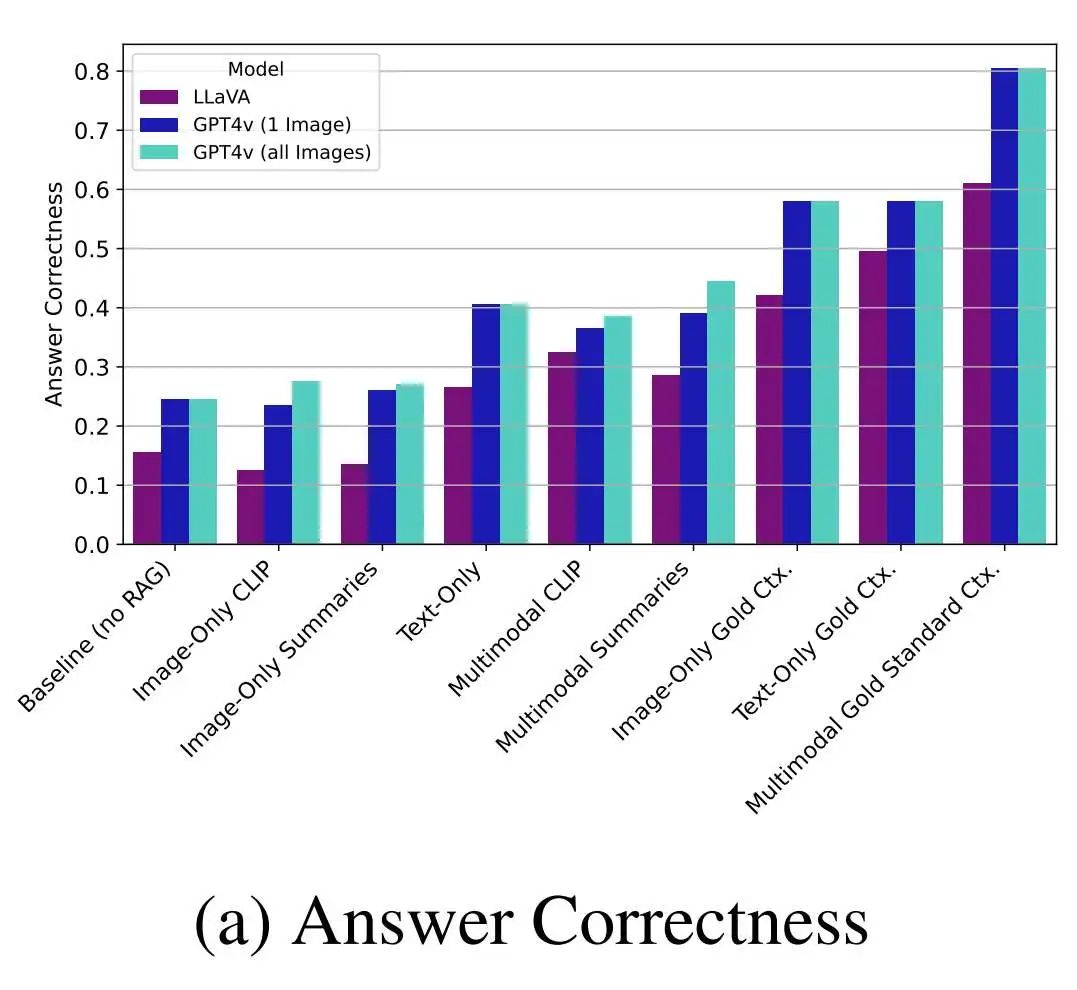

这里一共测试了六类,分别是Baseline(无RAG),Image-Only CLIP(仅图像CLIP模式,对应a结构),Image-Only Summaries(仅图像,总结多模态,对应b结构)Text-Only(仅文本,传统RAG),Multimodal CLIP(CLIP多模态,对于a结构),Multimodal Summaries(总结多模态,对于b结构),后面三类是金标准方法,是理论上限,作为对照。同时在LLaVA和GPT4v上进行测试,因为LLaVA仅支持单个图片输入,所以有了GPT4v的1 image对照组。
a图为回答的正确性,d图为回答的相关性,其中金标准方法是指在对应的模式下跳过rag阶段直接使用测试集的注释来进行回答的结果,可以理解为上限或者标准。
结论有两个:
多模态RAG确实能有效提升RAG回答的准确性,这个结论是通过金标准得到的,可以从a图看到金标准多模态远超单模态的准确性的效果,在具体的实验中,有GPT4v在多图的总结多模态情况下的表现超越了其他,但提升不明显,相较于金标准中的差距。作者的观点是多模态检索的方法有待提高,换言之就是ab这两种设计并不能激发真正多模态RAG的上限。 总结多模态要比使用CLIP召回的多模态准确性更高,这个结论可以对比同是多模态召回的数据,除了LLaVA在CLIP多模态的情况下超越了其他,GPT这边,总结性多模态的效果要比CLIP好。但个人觉得工程角度来看,这种流程太长,还要多额外的token消耗,实际表现也就好那么一两个点,还需要prompt工程来给大模型提供总结提示词,性价比不见得比CLIP高到哪去。
简单来说,理论上限非常高,实际表现很一般。
不过这里的实验数据不一定有广泛性,因为作者使用的测试数据集是一个工业数据集,不能确定在其他专业领域或者更大范围的数据上有相同的结论或有效,但目前看起来文中提到的这两个模式,CLIP多模态或者是总结多模态的模式,都不够优秀。另外,这里只是讨论多模态融合RAG的场景,测试的是生成结果的质量。实际的工程或产品角度上,提供图片的召回也可能是一个强需求。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











