公众号记得加星标⭐️,第一时间看推送不会错过。

来源:内容来自groq,谢谢。
Moonshot 的 Kimi K2 最近在GroqCloud上发布了预览版,开发人员不断问我们:Groq 如何如此快速地运行 1 万亿参数模型?
传统硬件迫使人们做出选择:要么更快的推理速度,但质量会下降;要么更精确的推理速度,但延迟令人无法接受。这种权衡之所以存在,是因为 GPU 架构会针对训练工作负载进行优化。而 LPU——专为推理而设计的硬件——在保持质量的同时,消除了造成延迟的架构瓶颈。
无需权衡的准确性:TruePoint Numerics
传统加速器通过激进的量化来实现速度,迫使模型进入 INT8 或更低精度的数值,这会在整个计算管道中引入累积误差并导致质量损失。
我们使用 TruePoint 数值技术,改变了这一现状。TruePoint 是一种仅在不降低准确度的区域降低精度的方法。结合我们的 LPU 架构,这种方法能够在保持高精度数值的同时保持质量。TruePoint 格式存储 100 位中间累积——足够的范围和精度,无论输入位宽如何,都能保证无损累积。这意味着我们可以以较低的精度存储权重和激活函数,同时以全精度执行所有矩阵运算,然后根据下游误差敏感度选择性地量化输出。
我们的编译器策略性地应用精度:
FP32 用于 1 位错误传播的注意逻辑
混合专家 (MoE) 权重的块浮点,其中稳健性研究表明没有可测量的退化
容错层中激活的 FP8 存储
这种控制水平使速度比 BF16 提升了 2-4 倍,并且在 MMLU 和 HumanEval 等基准测试中准确率没有明显损失。随着 AI 推理和硬件需求的指数级增长,业界正在效仿 MXfp4 等格式,以减少模型占用空间。我们并非为了速度而牺牲质量,而是消除了导致这种权衡的架构限制。
内存架构:SRAM 作为主存储器
传统加速器沿用了专为训练设计的内存层级结构:DRAM 和 HBM 作为主存储,并配备复杂的缓存系统。DRAM 和 HBM 都会在每次权重提取时引入显著的延迟——每次访问数百纳秒。这适用于时间局部性可预测且运算强度较高的高批量训练,但推理需要按顺序执行层,运算强度要低得多,这暴露了 DRAM 和 HBM 带来的延迟损失。
LPU 集成了数百兆片上 SRAM 作为主权重存储器(而非缓存),从而显著降低了访问延迟。这种设计允许计算单元全速加载权重,通过将单层拆分到多个芯片上来实现张量并行。这对于快速、可扩展的推理而言,具有实际优势。
执行模型:静态调度
GPU 架构依赖于动态调度——硬件队列、运行时仲裁以及引入非确定性延迟的软件内核。在集体运算过程中,数百个核心必须同步激活张量,任何延迟都会影响整个系统。
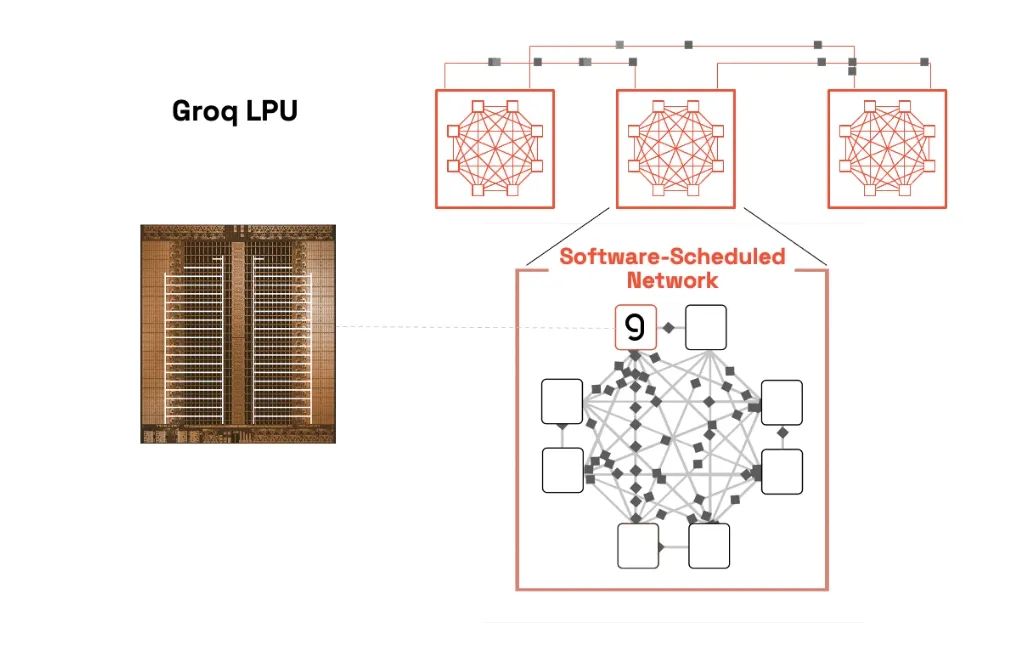
我们的编译器预先计算整个执行图,包括芯片间通信模式,直至单个时钟周期。这种静态调度可以消除:
缓存一致性协议
重新排序缓冲区
推测执行开销
运行时协调延迟
确定性执行可以实现动态调度系统上无法实现的两项关键优化:
无尾延迟的张量并行:每一层分布在多个芯片上,保证同步,消除困扰 GPU 集体操作的延迟。
张量并行之上的流水线并行:第 N+1 层开始处理输入,而第 N 层继续计算,这是 GPU 难以实现的,因为存在动态调度和无法有效平衡流水线阶段的问题。
并行策略:延迟优化分布
数据并行通过运行多个模型实例来扩展吞吐量。GPU 可以通过数据并行实现良好的扩展性——在不同的输入上运行同一模型的多个副本。这可以提高吞吐量,但如果您正在等待单个响应,则无济于事。
张量并行通过将单个操作分布在多个处理器上来降低延迟。对于实时应用来说,张量并行是关键的优化。我们的 LPU 架构专为张量并行而构建。我们将每一层划分到多个 LPU 上,这样单次前向传递就能更快完成,而无需并行处理更多请求。正是这种架构选择,让 Moonshot AI 的 Kimi K2 尽管拥有数万亿的参数,却依然能够实时生成令牌。
推测解码:在张量并行硬件上执行
推测解码是一种使用较小、较快的“草稿”模型来预测未来令牌序列的技术,然后在较大的目标模型的单次批量前向传递中验证这些令牌。虽然这种方法可以提高速度,但在 GPU 等传统硬件上,验证步骤通常会受到内存带宽的限制,从而限制性能提升。
我们的 LPU 采用独特的架构设计,能够通过流水线并行更高效地处理推测性 token 批次的验证,从而加快这些验证步骤的处理速度,并支持每个流水线阶段接受多个 token(通常为 2-4 个)。结合利用张量并行的快速草稿模型,这为推理带来了复合性能提升。
软件调度网络:RealScale芯片到芯片互连
Groq 使用准同步芯片间协议来消除自然时钟漂移,并将数百个逻辑处理器 (LPU) 对齐,使其充当单个核心。这样,软件编译器就可以准确预测数据到达时间,以便开发人员进行时序推理。周期性软件同步可以调整基于晶体的漂移,不仅支持计算调度,还支持网络调度。这使得 Groq 能够像单核超级集群一样运行,从编译器开始,从而避免了传统架构中存在的复杂协调问题。
基准测试:Groq 的表现如何
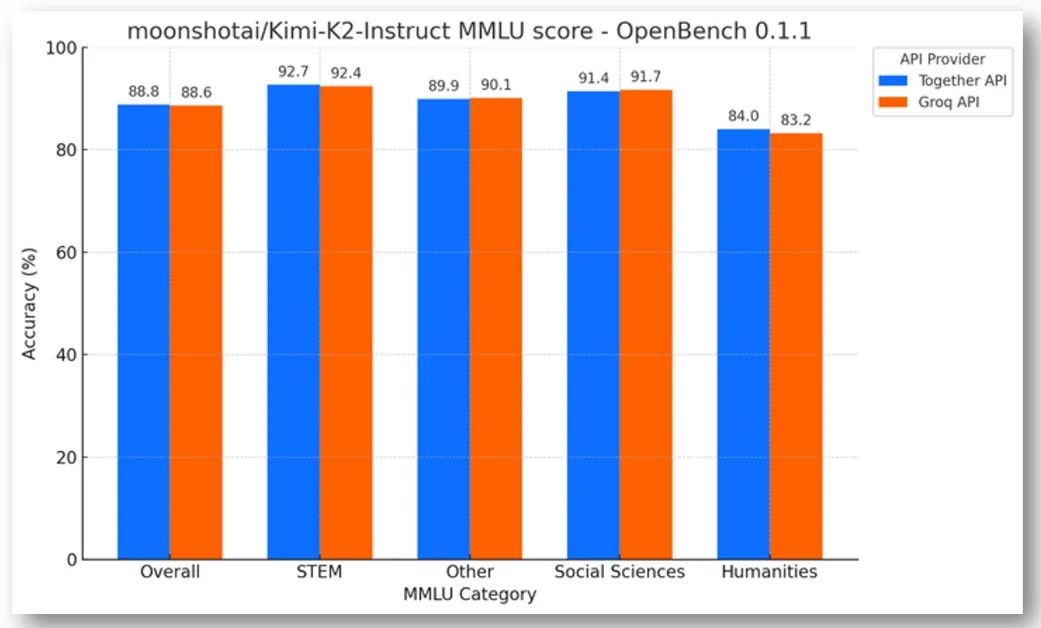
我们非常重视模型质量。昨天,我们发布了 OpenBench——一个与提供商无关的、面向 LLM 的开放评估框架。我们在 Groq 和基于 GPU 的 API 提供商上,在 Kimi-K2-Instruct 上运行了 OpenBench 0.1.1 的 MMLU 实现,您可以看到准确率得分很高——这充分展现了 Groq 堆栈的强大功能。了解更多关于 OpenBench 的信息,并亲自复现这些基准测试。
底线
Groq 绝不敷衍了事。我们从零开始构建推理,力求速度、规模、可靠性和成本效益。正因如此,我们才能在短短 72 小时内让 Kimi K2 的性能提升 40 倍。我们于 2019 年推出的第一代 LPU,采用 14nm 制程工艺,实现了如此优异的运行效果。我们高度重视开发者的反馈和实际性能,并结合行业领先的设计和严格的技术基准,致力于提供极致的 AI 推理体验。我们将继续加速硬件和软件的开发,使开发者能够专注于他们最擅长的事情:快速构建。
参考链接
https://groq.com/blog/inside-the-lpu-deconstructing-groq-speed
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4114期内容,欢迎关注。
推荐阅读

加星标⭐️第一时间看推送,小号防走丢














