🔥 摘要:本周 Hugging Face 论文热度榜单精彩纷呈!我们为您盘点了过去一周最受关注的 20 篇 AI 论文,并按照社区投票热度(点赞数)从高到低进行排序。来自快手和人大的 ARPO 论文以 118 票的绝对优势登顶,提出了一种全新的智能体强化学习范式。紧随其后的是腾讯混元团队的 HunyuanWorld 1.0,展示了从文本或像素生成沉浸式 3D 世界的惊人能力。专为本地部署而生的 SmallThinker 高效语言模型家族、字节跳动的定理证明神器 Seed-Prover 以及模块化多智能体前端代码生成框架 ScreenCoder 也都获得了极高的关注度。本期盘点将带您速览智能体进化、模型量化几何学、多任务学习、视频结构化理解等前沿领域的最新突破!
本文由 AI 生成,可能有误!!!
你好,AI 探索者们!
又到了激动人心的一周,AI 的世界再次以惊人的速度向前演进。从能够自我进化、更懂协作的“超级智能体”,到在普通电脑上就能流畅运行的“端侧大模型”,再到能将一句话、一张图瞬间变为可探索 3D 虚拟世界的“创世引擎”,每一个进步都在重新定义我们与数字世界的交互方式。
本周的 Hugging Face 论文热榜正是这些前沿探索的缩影。我们见证了研究者们如何通过新颖的强化学习范式,让大型语言模型在与工具的交互中变得更“聪明”、更高效;也看到了研究者们如何从底层架构出发,为资源受限的本地设备量身打造强大的语言能力。这不仅仅是模型的升级,更是对 AI 能力边界的又一次拓展。
在正式介绍本周热门论文 TOP 20 前,重磅宣布 https://paperscope.ai 重磅更新,全面高频实时同步 HF Daily Papers,并会生成 Intern-S1、Qwen3、GLM4.5、Kimi-K2 的论文解读,网站如下:
https://paperscope.ai/

接下来,就让我们一起深入本周最热门的 20 篇论文,看看这些顶尖的头脑正在思考什么,又为我们描绘了怎样一幅激动人心的未来图景。
(1) 智能体强化策略优化:更低预算,更高性能 (118 票)
论文原始英文标题:
Agentic Reinforced Policy Optimization
论文链接:
https://huggingface.co/papers/2507.19849
paperscope.ai 解读:
https://paperscope.ai/hf/2507.19849
简要介绍:
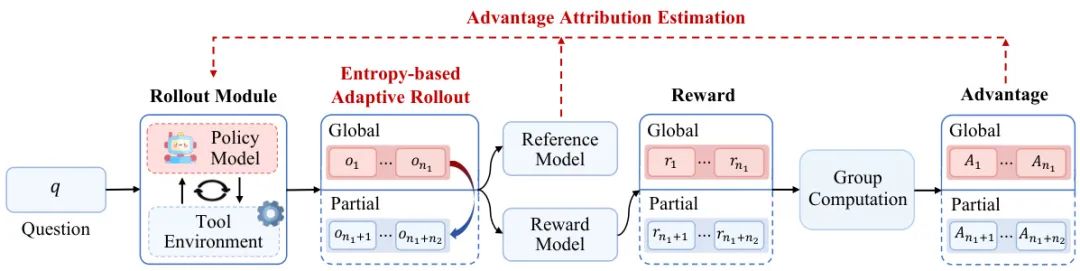
由人大和快手科技的研究者们共同提出了 Agentic Reinforced Policy Optimization (ARPO),一种专为训练多轮交互的 LLM Agent 设计的新型强化学习算法。研究发现,LLM 在与外部工具交互后,其生成词元的熵(不确定性)会显著增加。传统方法往往忽略了在这些高不确定性时刻进行探索。ARPO 针对性地设计了“基于熵的自适应部署机制”,在高不确定性的工具调用后,动态地增加采样,从而在探索更广泛的工具使用行为与维持全局轨迹学习之间取得了平衡。此外,通过“优势归因估计”机制,ARPO 能够让模型更好地理解和内化在工具交互中每一步行为的好坏差异。实验结果惊人,在13个涵盖计算、知识和深度搜索的基准测试中,ARPO 全面超越了传统的轨迹级强化学习算法,并且实现更优性能的同时,所需的工具调用预算仅为现有方法的一半,为构建更高效、更强大的 LLM Agent 提供了可扩展的解决方案。
核心图片:
(2) 混元世界 1.0:从文字或像素生成可探索的沉浸式 3D 世界 (98 票)
论文原始英文标题:
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
论文链接:
https://huggingface.co/papers/2507.21809
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21809
简要介绍:
由腾讯混元团队提出的 HunyuanWorld 1.0 是一个创新的框架,旨在解决从文本或图像创建沉浸式、可玩 3D 世界的挑战。该框架巧妙地结合了视频生成方法的多样性和 3D 生成方法的几何一致性。其核心是一种“语义分层 3D 网格表示法”,利用全景图像作为 3D 世界的代理,进行语义感知的世界分解和重建。这种方法不仅能提供 360° 的沉浸式体验,还能导出与现有计算机图形管线兼容的网格模型,并且通过解耦的对象表示增强了交互性。该框架首先生成全景图作为世界代理,然后通过智能体进行世界分层,将复杂场景分解为天空、背景和多个对象层,最后逐层进行 3D 重建。实验证明,HunyuanWorld 1.0 在生成连贯、可探索和可交互的 3D 世界方面达到了业界顶尖水平,并在虚拟现实、物理模拟和游戏开发等领域展现了广泛的应用潜力。
核心图片:

(3) Seed-Prover:用于自动定理证明的深度与广度推理 (80 票)
论文原始英文标题:
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
论文链接:
https://huggingface.co/papers/2507.23726
paperscope.ai 解读:
https://paperscope.ai/hf/2507.23726
简要介绍:
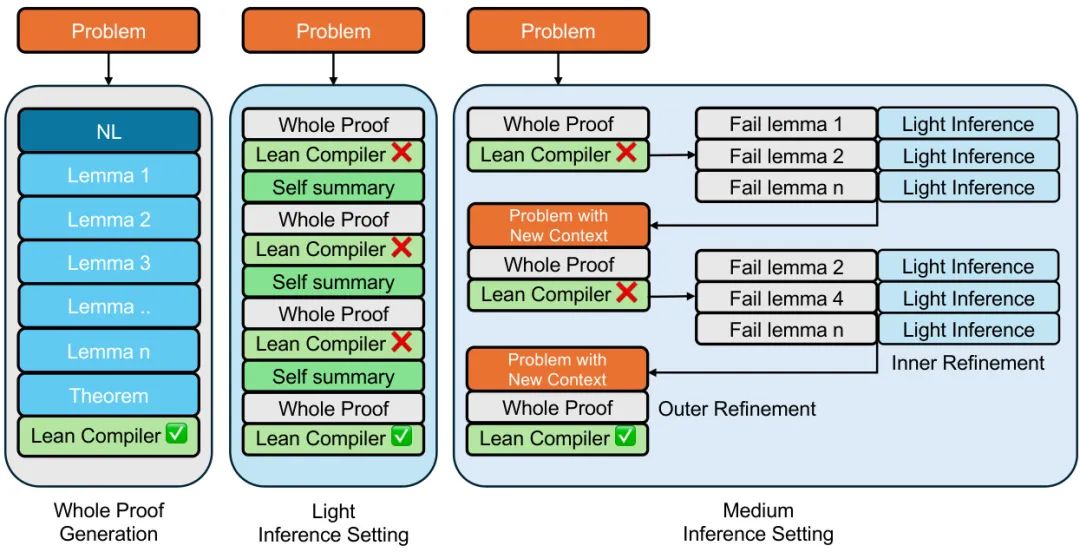
由字节跳动 Seed AI4Math 团队提出的 Seed-Prover 是一款专为自动定理证明设计的“引理式”全证明推理模型。传统的自然语言证明难以验证,而像 Lean 这样的形式化语言则能提供清晰的监督信号。Seed-Prover 正是利用了这一点,它能够根据 Lean 编译器的反馈、已证明的引理以及自我总结来迭代地优化和完善其证明过程。为了解决奥数级别的难题,该工作设计了三种测试时推理策略,使模型能够同时进行深度(深挖细节)和广度(探索性质)的推理。此外,由于 Lean 对几何学的支持不足,团队还推出了一个专门的几何推理引擎 Seed-Geometry。最终,Seed-Prover 在形式化的 IMO 历史问题中证明了 78.1% 的题目,并在多个基准测试中大幅超越了之前的 SOTA 模型。在 2025 年的 IMO 竞赛中,这两个系统联手成功证明了 6 个问题中的 5 个,标志着自动数学推理领域的一大步。
核心图片:
(4) ScreenCoder:通过模块化多模态智能体推进前端自动化 (75 票)
论文原始英文标题:
ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
论文链接:
https://huggingface.co/papers/2507.22827
paperscope.ai 解读:
https://paperscope.ai/hf/2507.22827
简要介绍:
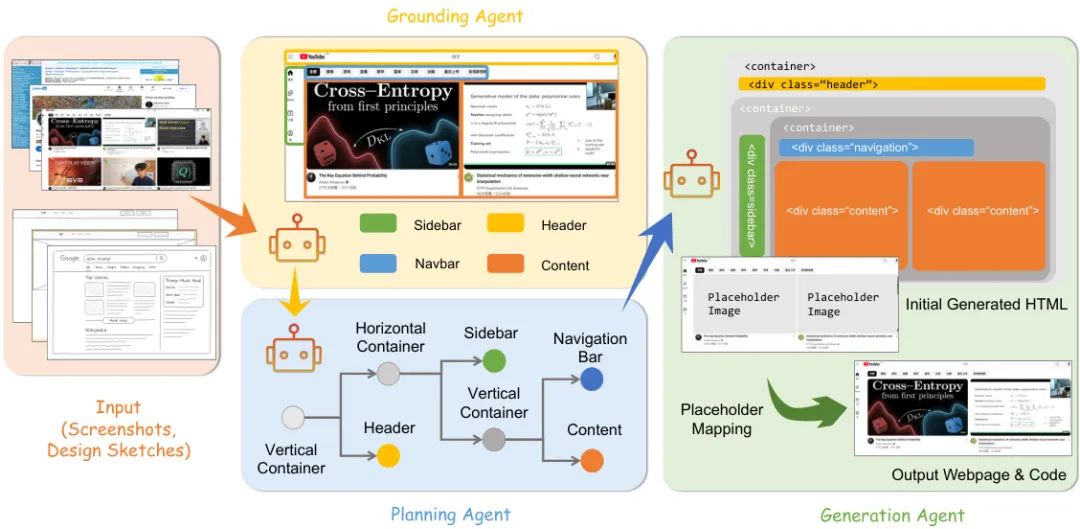
由香港中文大学 MMLab 等机构提出的 ScreenCoder,是一个创新的模块化多智能体框架,旨在解决将 UI 设计图直接转化为前端代码(HTML/CSS)的挑战。传统方法或仅依赖文本(难以描述复杂布局),或采用端到端的黑盒模型(容易出错且难以解释)。ScreenCoder 将这一复杂任务分解为三个清晰的阶段:1)定位智能体:利用视觉语言模型(VLM)检测并标记 UI 界面中的关键组件(如侧边栏、导航栏)。2)规划智能体:根据前端工程的最佳实践,将这些组件组织成一个层级化的布局树。3)生成智能体:基于布局树和用户指令,自适应地生成高质量代码。这种模块化设计不仅提高了代码的准确性和布局的保真度,还增强了可解释性。更进一步,该框架还能作为一个可扩展的数据引擎,自动生成大量的“图像-代码”配对数据,用于微调和强化开源 VLM,从而显著提升了模型对 UI 的理解能力。
核心图片:
(5) 自我进化智能体综述:通往人工超级智能之路 (70 票)
论文原始英文标题:
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
论文链接:
https://huggingface.co/papers/2507.21046
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21046
简要介绍:
这篇由普林斯顿大学、清华大学、上海交通大学等多家顶尖机构联合撰写的综述,首次系统性地全面回顾了“自我进化智能体”这一前沿领域。文章指出,尽管大型语言模型(LLM)能力强大,但其本质上是静态的,无法适应新任务或动态环境。自我进化智能体则代表了从“扩展静态模型”到“发展自适应智能体”的范式转变,是通往人工超级智能(ASI)的关键一步。该综述围绕三个核心问题构建了一个清晰的框架:进化什么?(模型、记忆、工具、架构)、何时进化?(测试时内部/外部)、以及如何进化?(基于奖励、模仿学习、基于种群等)。文章不仅系统梳理了现有技术,还深入探讨了评估自我进化智能体的指标和基准、在编码、教育、医疗等领域的应用,并指出了在安全、可扩展性和协同进化等方面的关键挑战与未来研究方向,为该领域的研究者和实践者提供了一份宝贵的路线图。
核心图片:

(6) Falcon-H1:重新定义效率与性能的混合头语言模型家族 (57 票)
论文原始英文标题:
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
论文链接:
https://huggingface.co/papers/2507.22448
paperscope.ai 解读:
https://paperscope.ai/hf/2507.22448
简要介绍:
Falcon LLM 团队推出了 Falcon-H1,这是一个全新的大型语言模型系列,其核心特点是创新的混合架构设计。不同于以往纯 Transformer 或 Mamba 架构,Falcon-H1 采用并行混合架构,巧妙地结合了 Transformer 注意力机制(擅长长距离依赖建模)和状态空间模型(SSM,以其长上下文记忆和计算效率著称)。该系列模型在数据策略、训练动态等多个方面都挑战了传统做法。为了适应不同部署场景,Falcon-H1 发布了从 0.5B 到 34B 的多种参数规模,并提供了基础、指令微调及量化版本。其旗舰模型 Falcon-H1-34B-Instruct 的性能可与 Qwen3-32B、Qwen2.5-72B 和 Llama3.3-70B 等更大规模的模型相媲美,而其尺寸仅为后者的一半左右。这种参数效率在小模型上更为显著,例如 1.5B-Deep 模型的性能可与 SOTA 的 7B-10B 模型竞争,0.5B 模型则达到了 2024 年主流 7B 模型的水平。
核心图片:

(7) ARC-混元-视频-7B:真实世界短视频的结构化理解 (56 票)
论文原始英文标题:
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
论文链接:
https://huggingface.co/papers/2507.20939
paperscope.ai 解读:
https://paperscope.ai/hf/2507.20939
简要介绍:
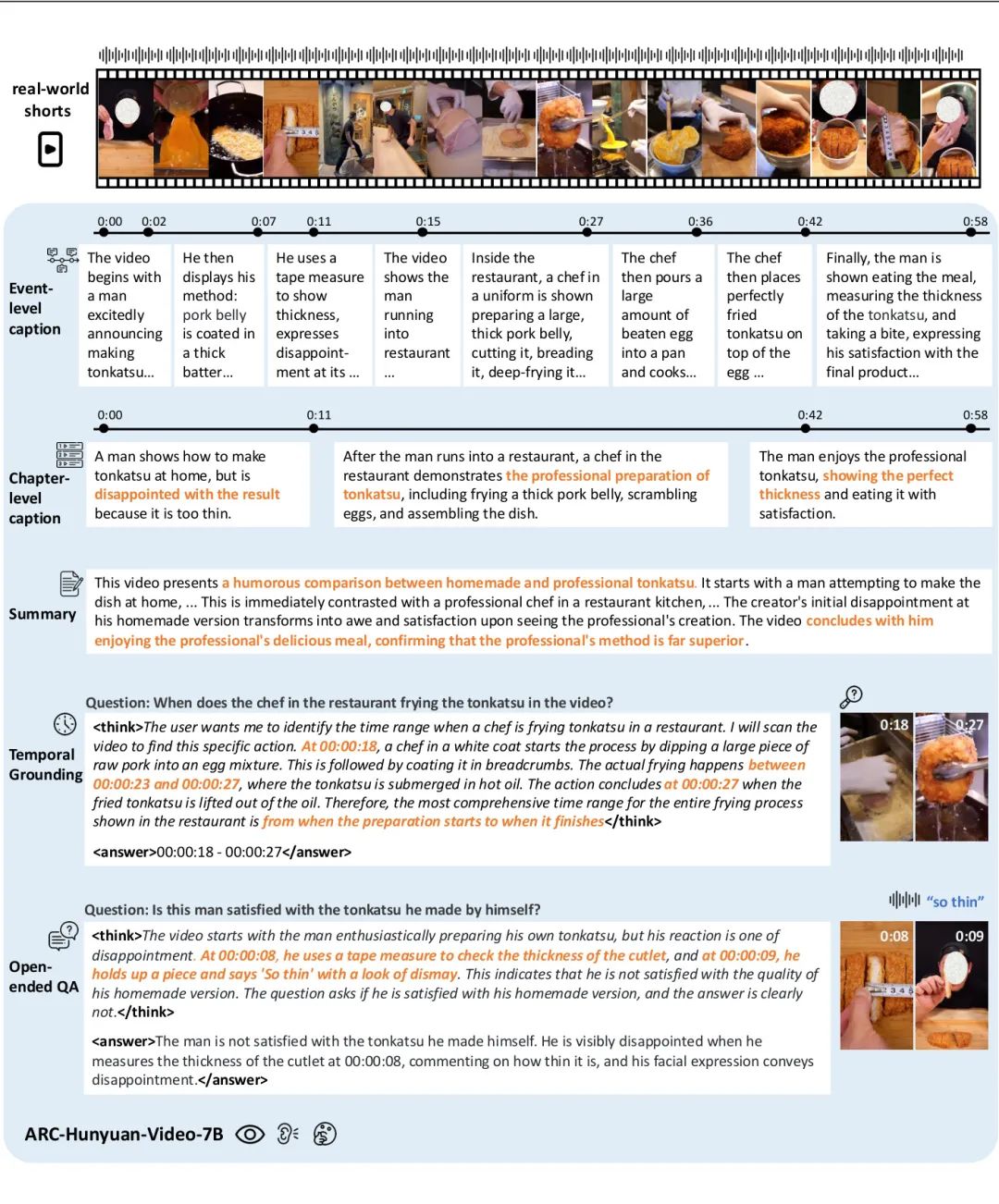
由腾讯 PCG 的 ARC 实验室等团队提出的 ARC-Hunyuan-Video-7B,是一款专为理解真实世界短视频(如微信视频号、抖音上的内容)而设计的多模态模型。这类视频信息密度高、节奏快,并夹杂着视觉、音频和文本等复杂元素,对现有模型构成了巨大挑战。该模型能够端到端地处理视频的视觉、音频和文本信号,实现“结构化视频理解”。具体来说,它能生成带有多粒度时间戳的视频字幕和摘要、进行开放式视频问答、时序定位和视频推理。这个仅有 70 亿参数的紧凑模型,通过一个包括预训练、指令微调、冷启动、强化学习后训练和最终指令微调的全面训练流程进行优化。在实际生产部署中,该模型已显著提升了用户参与度和满意度,并且效率极高:在 H20 GPU 上处理一分钟的视频仅需 10 秒。
核心图片:
(8) BANG:通过生成式爆炸动力学拆分 3D 资产 (55 票)
论文原始英文标题:
BANG: Dividing 3D Assets via Generative Exploded Dynamics
论文链接:
https://huggingface.co/papers/2507.21493
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21493
简要介绍:
由上海科技大学等机构提出的 BANG,是一种新颖的生成式方法,旨在模拟人类天生的“拆解-重组”能力,实现对 3D 对象的部件级分解。该方法的核心是“生成式爆炸动力学”(Generative Exploded Dynamics),它能为输入的三维几何体生成一个平滑、连续的“爆炸”过程序列,将物体的各个组成部分逐渐分离,同时保持其几何和语义的连贯性,最终形成一个类似工程图中的爆炸视图。BANG 利用一个预训练的大规模潜在扩散模型,并通过一个轻量级的“爆炸视图适配器”进行微调,从而能够精确控制分解过程。此外,它还引入了时间注意力模块以保证过渡的平滑性,并支持边界框、表面区域等空间提示进行可控生成。该框架不仅能生成精细的部件级几何细节,还能将部件与功能描述相关联,极大地促进了面向组件的 3D 创作、3D 打印和制造流程,让 3D 创作过程变得像组装拼图一样直观和有趣。
核心图片:

(9) 深度研究员与测试时扩散 (53 票)
论文原始英文标题:
Deep Researcher with Test-Time Diffusion
论文链接:
https://huggingface.co/papers/2507.16075
paperscope.ai 解读:
https://paperscope.ai/hf/2507.16075
简要介绍:
由谷歌云 AI 研究团队提出的 Test-Time Diffusion Deep Researcher (TTD-DR),是一个创新的深度研究智能体框架。该工作受到人类研究写作过程(搜索、推理、修订)的启发,将复杂研究报告的生成过程概念化为一个扩散过程。TTD-DR 首先生成一个初步的草稿,这个草稿如同一个可不断更新的骨架,指导着整个研究方向。随后,通过一个迭代的“去噪”过程对草稿进行精炼,每一步都通过检索外部信息来动态地提供新知。此外,该框架还对智能体工作流的每个组件(如规划、提问、回答)应用了自我进化算法,以确保为扩散过程生成高质量的上下文。这种以“草稿为中心”的设计,使得报告写作过程更加及时和连贯,同时减少了在迭代搜索过程中的信息丢失。实验表明,TTD-DR 在需要密集搜索和多跳推理的基准测试中取得了 SOTA 成果,显著优于现有的深度研究智能体。
核心图片:

(10) SmallThinker:为本地部署原生训练的高效 LLM 家族 (49 票)
论文原始英文标题:
SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment
论文链接:
https://huggingface.co/papers/2507.20984
paperscope.ai 解读:
https://paperscope.ai/hf/2507.20984
简要介绍:
由上海交通大学等机构提出的 SmallThinker 挑战了前沿大模型依赖云端 GPU 的现状,它是一个专为本地设备(计算能力弱、内存有限、存储慢)从头设计的语言模型家族。不同于压缩云端模型的传统方法,SmallThinker 将本地设备的限制转化为了设计原则。其核心创新包括:1)两级稀疏结构:结合细粒度的专家混合(MoE)和稀疏前馈网络,大幅减少计算需求。2)预注意力路由器:在计算注意力时,模型就能预测并预先从慢速存储(如 SSD)中提取所需的专家参数,从而有效隐藏 I/O 延迟。3)混合稀疏注意力:采用 NoPE-RoPE 混合机制,显著减少 KV 缓存需求。发布的 SmallThinker-4B-A0.6B 和 SmallThinker-21B-A3B 模型在性能上达到了 SOTA 水平,甚至超越了更大的模型。惊人的是,在消费级 CPU 上,这两款模型量化后均能达到超过 20 tokens/s 的推理速度,而内存占用分别仅为 1GB 和 8GB,几乎摆脱了对昂贵 GPU 的依赖。
(11) Rep-MTL:释放表征级任务显著性在多任务学习中的力量 (38 票)
论文原始英文标题:
Rep-MTL: Unleashing the Power of Representation-level Task Saliency for Multi-Task Learning
论文链接:
https://huggingface.co/papers/2507.21049
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21049
简要介绍:
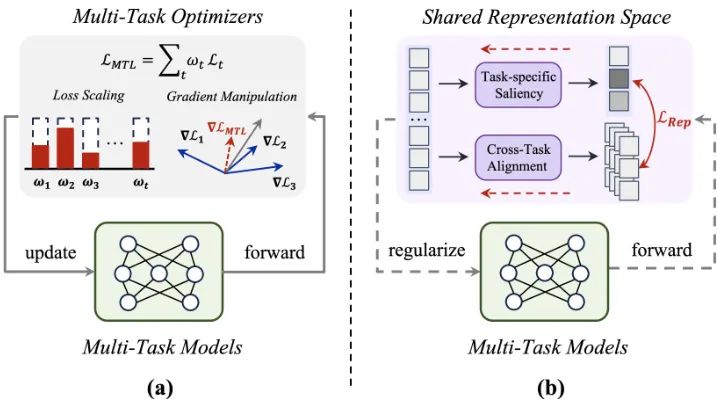
由香港科技大学和浙江大学的研究者们提出的 Rep-MTL 是一种新颖的多任务学习(MTL)优化方法。传统的多任务优化(MTO)技术主要通过调整损失权重或梯度来解决任务间的冲突,但效果并不稳定。该工作认为,任务交互发生的“共享表征空间”本身就蕴含着丰富的信息,可以用来补充现有优化器,特别是促进任务间的互补性。Rep-MTL 的核心是利用“表征级任务显著性”来量化任务优化与共享表征学习之间的相互作用。它通过两个模块实现:1)任务特定显著性调节(TSR):通过基于熵的惩罚,确保各任务的特定学习模式在训练中得以保留,从而减轻负迁移。2)跨任务显著性对齐(CSA):通过对比学习的方式,对齐不同任务在样本级别的显著性,明确促进互补信息的共享。实验表明,Rep-MTL 即使搭配最基础的等权重策略,也能在多个具有挑战性的 MTL 基准上取得显著性能提升和高效率。
核心图片:
(12) VL-Cogito:用于高级多模态推理的渐进式课程强化学习 (37 票)
论文原始英文标题:
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
论文链接:
https://huggingface.co/papers/2507.22607
paperscope.ai 解读:
https://paperscope.ai/hf/2507.22607
简要介绍:
由阿里巴巴达摩院等机构提出的 VL-Cogito 是一款先进的多模态推理模型,它通过一个新颖的“渐进式课程强化学习”(PCuRL)框架进行训练。由于多模态任务的复杂性和多样性,现有模型在不同领域和难度水平上表现不稳定。PCuRL 框架通过系统性地引导模型完成从易到难的任务,显著提升其在各种多模态情境下的推理能力。该框架有两大创新:1)在线难度软加权机制:在连续的强化学习阶段动态调整训练难度。2)动态长度奖励机制:鼓励模型根据任务的复杂性自适应地调整其推理路径的长度,从而在推理效率和正确性之间取得平衡。实验结果表明,VL-Cogito 在数学、科学、逻辑和通用理解等主流多模态基准测试中,其性能与现有顶尖的推理导向模型相当或更优,验证了该方法的有效性。
核心图片:

(13) LLM 量化的几何学:GPTQ 作为 Babai 的最近平面算法 (36 票)
论文原始英文标题:
The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
论文链接:
https://huggingface.co/papers/2507.18553
paperscope.ai 解读:
https://paperscope.ai/hf/2507.18553
简要介绍:
来自奥地利科学技术研究所(ISTA)和苏黎世联邦理工学院(ETH Zürich)的研究者们揭示了著名 LLM 量化算法 GPTQ 与经典格理论算法之间的深刻联系。GPTQ 是将 LLM 权重从 16 位量化到更低位宽的标准方法之一,但其工作原理通常被描述为一系列代数更新,缺乏几何直观性和理论保证。这篇论文通过严谨的数学论证证明:当 GPTQ 对一个线性层从后向前(从最后一个维度到第一个维度)执行时,它在数学上等同于用于解决经典“最近向量问题”(CVP)的 Babai 最近平面算法。这一等价性带来了两大理论成果:首先,GPTQ 的误差传播步骤获得了直观的几何解释;其次,在无裁剪条件下,GPTQ 继承了 Babai 算法的误差上界,从而为量化误差提供了理论保证。这一发现不仅为 GPTQ 奠定了坚实的理论基础,也为将格理论中数十年的研究成果引入到未来十亿参数模型的量化算法设计中打开了大门。
核心图片:

(14) X-Omni:强化学习让离散自回归图像生成模型重焕新生 (34 票)
论文原始英文标题:
X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
论文链接:
https://huggingface.co/papers/2507.22058
paperscope.ai 解读:
https://paperscope.ai/hf/2507.22058
简要介绍:
由腾讯混元 X 团队提出的 X-Omni,旨在通过强化学习(RL)重振离散自回归模型在图像生成领域的应用。尽管将“下一个词元预测”范式扩展到视觉领域很有吸引力,但早期自回归图像生成方法(如 DALL-E 早期版本)常因累积误差和信息损失导致图像质量不佳。这使得研究重心转向了扩散模型。该工作认为,强化学习可以有效缓解这些问题。X-Omni 框架包含一个语义图像分词器、一个统一的自回归模型(处理语言和图像)以及一个离线的扩散解码器。通过精心设计的奖励模型,强化学习能够自动优化生成模型,减少累积误差,并使生成的离散图像词元与扩散解码器的期望分布更加对齐。实验结果表明,一个 7B 语言模型大小的 X-Omni 在图像生成任务上取得了 SOTA 性能,不仅图像美学质量高,而且在遵循复杂指令和渲染长文本方面表现出色。
核心图片:

(15) Phi-Ground 技术报告:提升 GUI 定位中的感知能力 (34 票)
论文原始英文标题:
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
论文链接:
https://huggingface.co/papers/2507.23779
paperscope.ai 解读:
https://paperscope.ai/hf/2507.23779
简要介绍:
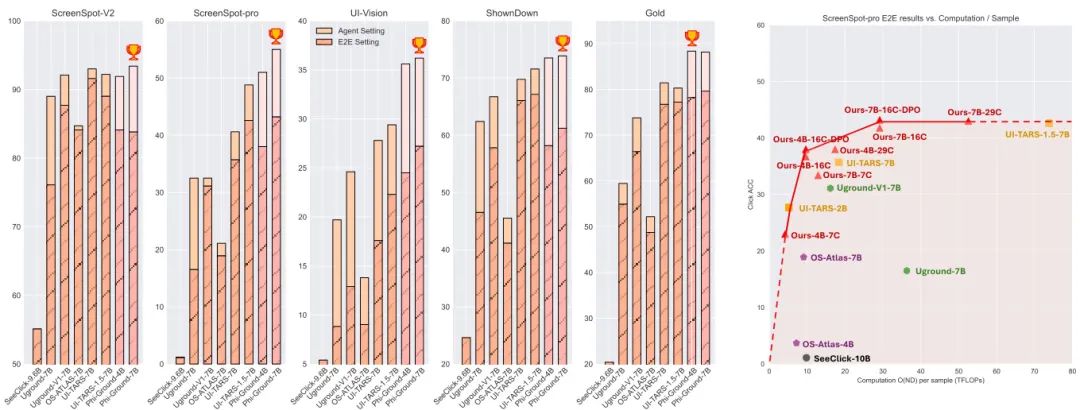
由微软团队发布的这篇技术报告,深入探讨了 GUI(图形用户界面)定位模型的训练。GUI 定位是计算机使用智能体(CUA)执行点击、输入等操作的核心感知能力,其准确性直接决定了智能体任务的成败。报告指出,尽管多模态模型发展迅速,但现有端到端定位模型在 ScreenSpot-pro 等高难度基准上的准确率仍低于 65%,远未达到可部署水平。为此,研究团队对定位模型的训练过程进行了详尽的实证研究,涵盖了从数据收集到模型训练的各个环节。他们发现,模态输入的顺序、特定类型的数据增强(尤其是在高分辨率场景下)以及领域内持续学习策略都对模型性能有显著影响。最终,他们开发了 Phi-Ground 模型家族,在 10B 参数以下的智能体设置中,于五个主流定位基准上均取得了 SOTA 性能。这项工作不仅阐明了构建高效定位模型的关键细节,也为其他多模态感知任务提供了宝贵的经验和启示。
核心图片:
(16) 重建 4D 空间智能:一篇综述 (33 票)
论文原始英文标题:
Reconstructing 4D Spatial Intelligence: A Survey
论文链接:
https://huggingface.co/papers/2507.21045
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21045
简要介绍:
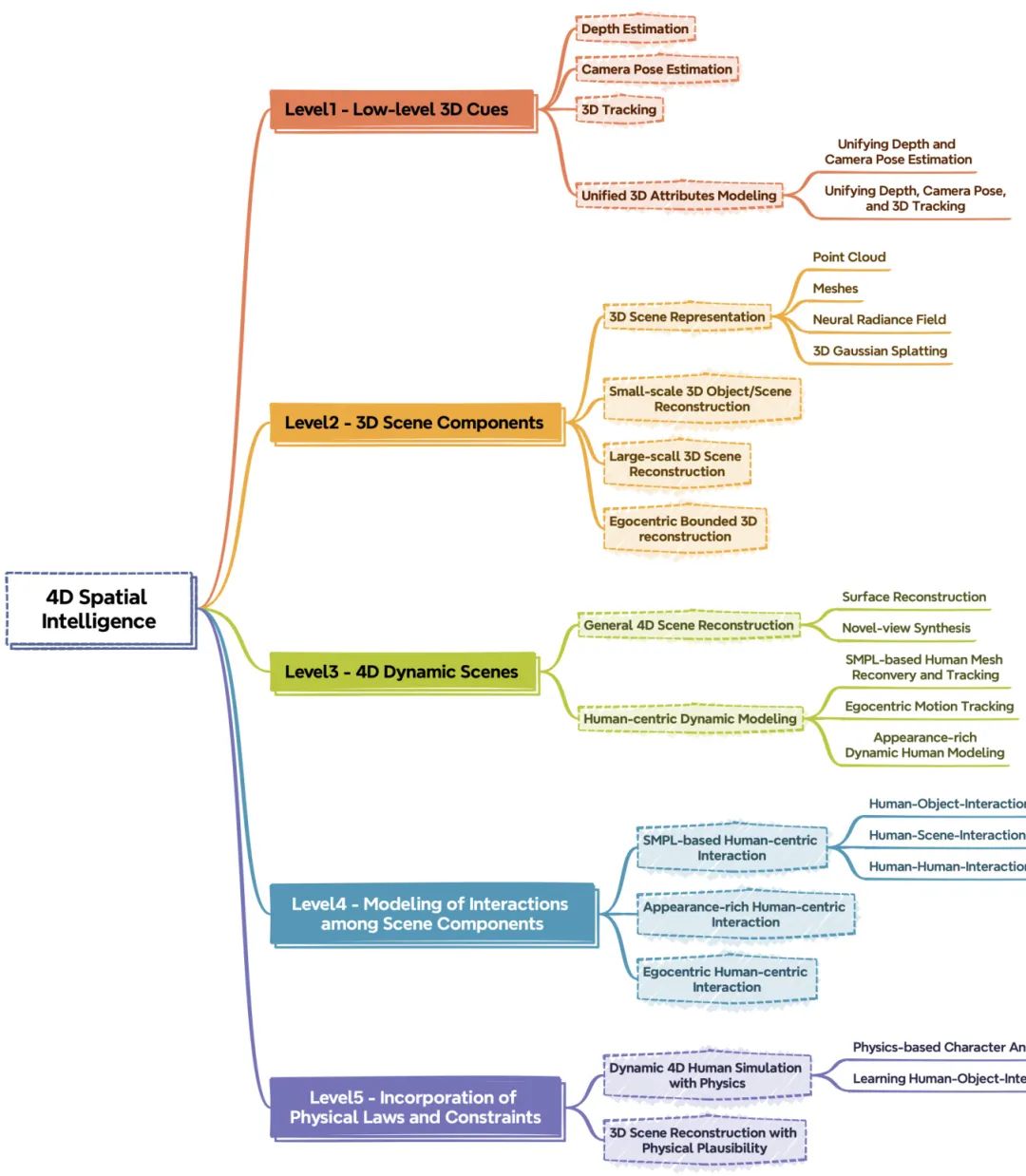
这篇综述为从视觉观测中重建 4D 空间智能这一复杂领域提供了全新的、层次化的视角。作者们认为,4D 空间智能的构建是一个渐进的过程,并将其划分为五个逐级递进的层次:层次 1 - 低级 3D 线索重建:包括深度、相机位姿、点云图等基础几何信息。层次 2 - 3D 场景组件重建:在基础之上,重建场景中的独立元素,如物体、人物和建筑结构。层次 3 - 4D 动态场景重建:引入时间维度,捕捉场景的动态变化,实现“子弹时间”等效果。层次 4 - 场景组件间交互建模:不仅重建动态,还模拟组件之间的相互作用,如人与物体的交互。层次 5 - 物理规律与约束的融合:将物理定律(如重力、碰撞)融入模型,使重建结果在物理上更加真实可信。 该综述系统地梳理了每个层次的现有方法,讨论了各层次面临的关键挑战,并为迈向更高级别的 4D 空间智能指明了未来方向,为该领域的研究者提供了一个全面而结构化的参考框架。
核心图片:
(17) 几何平均策略优化 (29 票)
论文原始英文标题:
Geometric-Mean Policy Optimization
论文链接:
https://huggingface.co/papers/2507.20673
paperscope.ai 解读:
https://paperscope.ai/hf/2507.20673
简要介绍:
由中国科学院大学和微软亚洲研究院等机构提出的 Geometric-Mean Policy Optimization (GMPO),是一种对现有 GRPO(Group Relative Policy Optimization)算法的改进和稳定化版本。GRPO 通过优化词元级奖励的“算术平均值”来提升大语言模型的推理能力,但在训练过程中,某些词元的重要性采样率可能出现极端值(离群点),导致策略更新不稳定。GMPO 的核心思想是用“几何平均值”替代“算术平均值”来聚合词元级奖励。由于几何平均值对离群点不敏感,这种方法能够天然地平滑极端奖励值的影响,使得重要性采样率保持在更稳定的范围内。理论和实验分析均表明,GMPO 带来了更稳定的策略更新、更低的 KL 散度和更高的词元熵,这意味着它在保持稳定性的同时,也增强了策略的探索能力。在多个数学和多模态推理基准测试中,GMPO-7B 模型相比 GRPO 取得了显著的性能提升。
(18) MMBench-GUI:用于 GUI 智能体的分层多平台评估框架 (27 票)
论文原始英文标题:
MMBench-GUI: Hierarchical Multi-Platform Evaluation Framework for GUI Agents
论文链接:
https://huggingface.co/papers/2507.19478
paperscope.ai 解读:
https://paperscope.ai/hf/2507.19478
简要介绍:
由上海人工智能实验室、上海交通大学等多家机构联合推出的 MMBench-GUI,是一个专为评估 GUI(图形用户界面)自动化智能体而设计的综合性基准测试框架。该框架具有三大特点:1)分层评估:它将 GUI 智能体的能力划分为四个递进的层级:GUI 内容理解、元素定位、任务自动化和任务协作,从而能够系统性地评估从基础感知到复杂协作的各项技能。2)跨平台覆盖:它是首个覆盖 Windows、macOS、Linux、iOS、Android 和 Web 六大主流平台的评估基准,填补了尤其是 macOS 在线评估的空白。3)效率与质量并重:该工作创新性地提出了效率-质量区域(EQA)指标,不仅评估任务成功率,还衡量完成任务所需的步骤数,鼓励开发更高效的智能体。通过该基准的全面评测,研究发现,精确的视觉定位是任务成功的关键,而当前所有模型在执行效率上都存在大量冗余操作,这为未来 GUI 智能体的研究指明了关键的优化方向。
核心图片:

(19) ChemDFM-R:用原子化化学知识增强的化学推理 LLM (23 票)
论文原始英文标题:
ChemDFM-R: An Chemical Reasoner LLM Enhanced with Atomized Chemical Knowledge
论文链接:
https://huggingface.co/papers/2507.21990
paperscope.ai 解读:
https://paperscope.ai/hf/2507.21990
简要介绍:
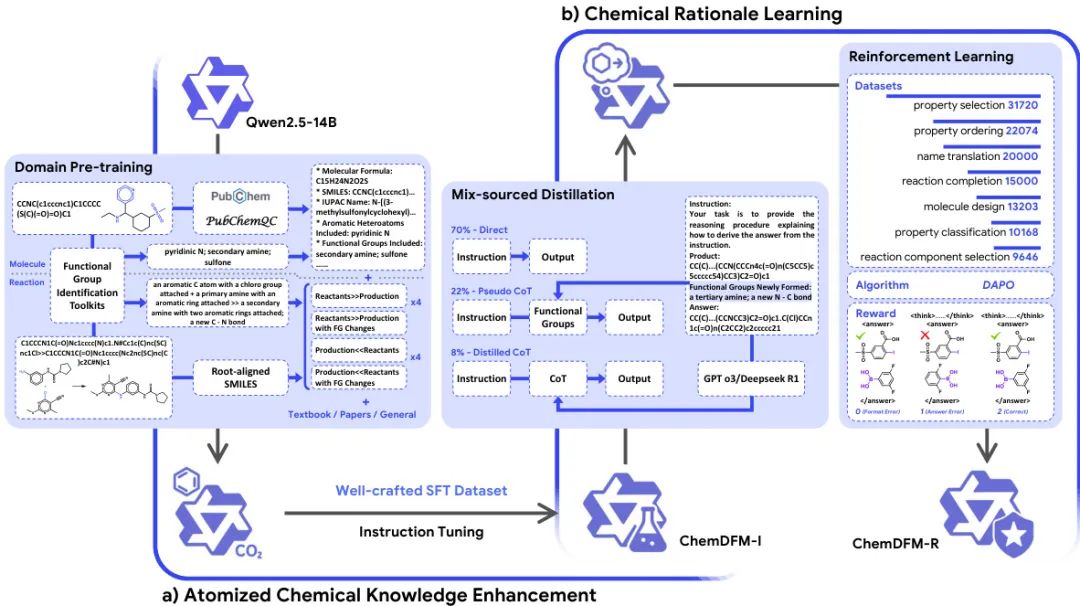
由上海交通大学 X-LANCE 实验室和苏州实验室共同开发的 ChemDFM-R 是一款专为化学领域设计的推理型大型语言模型。传统 LLM 在化学等科学领域的应用受限于其肤浅的领域理解和有限的推理能力。为解决此问题,该工作首先构建了一个包含“原子化”化学知识点的综合数据集,特别是分子中的官能团及其在反应中的变化,以增强模型对化学基本原理和逻辑结构的理解。随后,研究者提出了一种“混合来源蒸馏”策略,该策略巧妙地融合了专家策划的化学知识与通用领域的推理技能。最后,通过领域特定的强化学习进一步提升模型的化学推理能力。在多个化学基准测试中,ChemDFM-R 均取得了前沿性能,并且其输出具有可解释的推理链。案例研究表明,这种明确的推理过程显著提高了模型在真实人机协作场景中的可靠性、透明度和实用性。
核心图片:
(20) 多样性增强的主观问题推理 (22 票)
论文原始英文标题:
Diversity-Enhanced Reasoning for Subjective Questions
论文链接:
https://huggingface.co/papers/2507.20187
paperscope.ai 解读:
https://paperscope.ai/hf/2507.20187
简要介绍:
由香港科技大学提出的 MultiRole-R1,是一个旨在提升大型推理模型(LRM)在主观问题(如道德困境、观点性问题)上表现的框架。传统 LRM 在处理这类问题时,由于训练数据通常只有一个“标准答案”,其思维过程趋于单一。该工作受多智能体辩论的启发,认为引入多样的角色视角能改善这一问题。MultiRole-R1 框架首先通过一个无监督的数据构建流程,生成包含多种角色视角的推理链。随后,它采用带有奖励塑造的 GRPO 强化学习算法,将“多样性”(包括视角多样性和词汇多样性)作为一个额外的奖励信号,与答案的准确性一同进行优化。实验发现,提升推理的多样性与提升准确性之间存在正相关关系。有趣的是,该模型仅在主观问题上进行训练,却同时提升了在主观和客观(如数学推理)任务上的性能,展示了多样性增强训练在 LRM 中的巨大潜力。
结尾
从 ARPO 智能体对“不确定性”的精妙利用,到 HunyuanWorld 1.0 描绘的数字新世界,再到 SmallThinker 将强大 AI 带到我们身边的设备上,本周的论文热榜清晰地勾勒出一条主线:AI 正变得更加智能(Agentic)、更加高效(Efficient)和更加具身(Embodied)。
我们看到,研究者们不再满足于模型在单一任务上的静态表现,而是致力于构建能够主动学习、适应环境、甚至自我演化的智能系统。同时,对效率的极致追求正推动着模型架构的革新,让强大的 AI 不再是云端巨头的专属,而是有望成为人人可及的本地化工具。而 3D、视频、GUI 等领域的突破,则预示着 AI 正在从理解文本和图像,迈向真正理解并重构我们所处的三维动态世界。
这不仅是技术的迭代,更是思想的碰撞。当强化学习与人类认知过程相结合,当几何学原理被用来审视量化算法,当多样的视角被视为通往更准确答案的路径……我们正处于一个交叉融合、灵感迸发的黄金时代。
希望本期的盘点能为您带来启发。让我们共同期待,在下一波创新浪潮中,AI 又将为我们解锁哪些全新的可能。我们下周再见!










