智东西8月4日消息,刚刚,小米公司正式开源声音理解大模型MiDashengLM-7B。其声音理解性能在22个公开评测集上刷新多模态大模型最好成绩(SOTA),单样本推理的首Token延迟(TTFT)为业界先进模型的1/4,同等显存下的数据吞吐效率是业界先进模型的20倍以上。具体来看,MiDashengLM-7B基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。此前小米于2024年首次发布Xiaomi Dasheng声音基座模型,此次开源的7B模型是该模型的扩展。目前该系列模型在小米智能家居、汽车座舱等领域有30多个落地应用。小米称,音频理解是构建全场景智能生态的关键领域。MiDashengLM通过统一理解语音、环境声与音乐的跨领域能力,不仅能听懂用户周围发生了什么事情,还能分析发现这些事情的隐藏含义,提高用户场景理解的泛化性。MiDashengLM的训练数据由100%公开数据构成。https://github.com/xiaomi-research/dasheng-lmhttps://github.com/xiaomi-research/dasheng-lm/tree/main/technical_reporthttps://huggingface.co/mispeech/midashenglm-7bhttps://modelscope.cn/models/midasheng/midashenglm-7bhttps://xiaomi-research.github.io/dasheng-lmhttps://huggingface.co/spaces/mispeech/MiDashengLM
MiDashengLM在音频描述、声音理解、音频问答任务中有比较明显的优势:▲音频描述任务性能(FENSE指标)
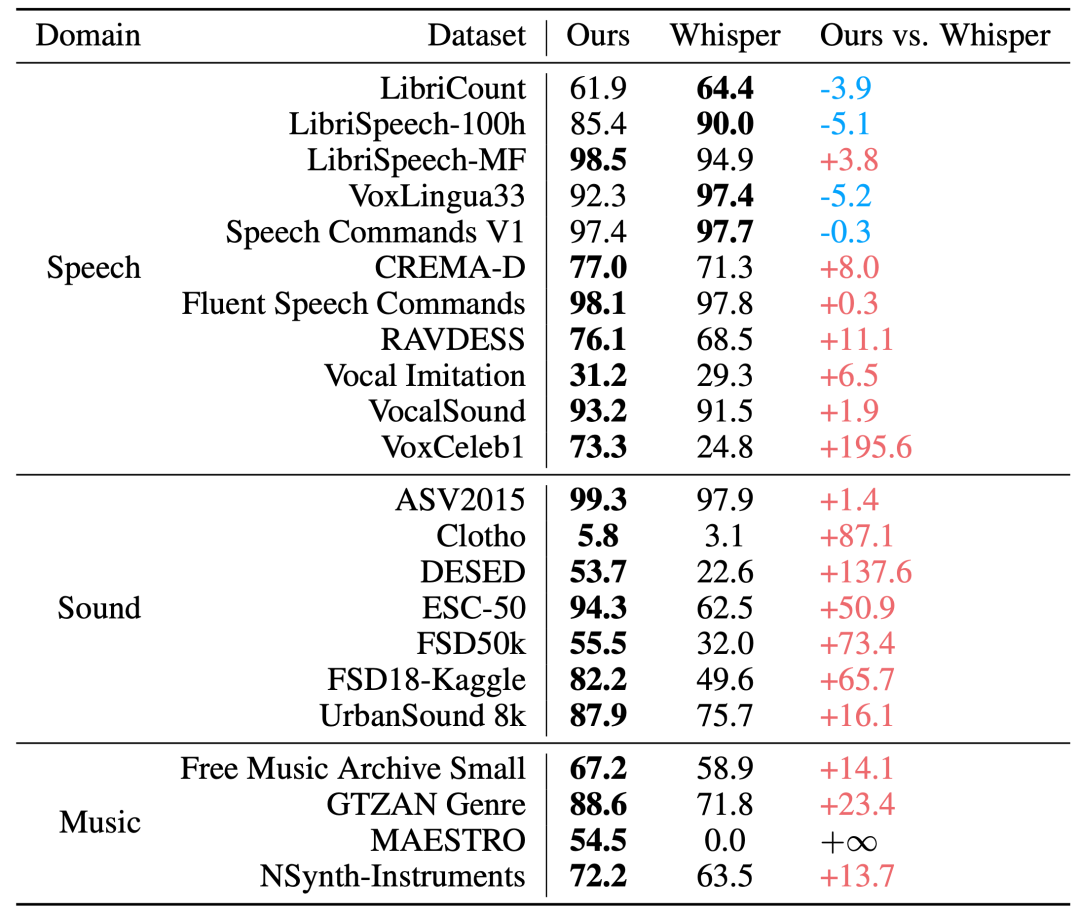
在音频描述任务中,MiDashengLM-7B比Qwen、Kimi同类7B模型性能更强。▲声音理解任务性能
在声音理解任务中,MiDashengLM-7B除FMA、VoxCeleb-Gender项目均领先于Qwen的7B模型,与Kimi的7B模型相比,仅有VoxCeleb-Gender项目略微落后。▲语音识别任务性能(WER/CER指标)
在语音识别任务中,MiDashengLM-7B的主要优势在于GigaSpeech 2,在其他两组测试中Qwen和Kimi有一定优势。▲音频问答任务性能
其中,Xiaomi Dasheng音频编码器是MiDashengLM音频理解能力的重要来源。在用于评估编码器通用能力的X-ARES Benchmark上,Xiaomi Dasheng在多项关键任务上优于作为Qwen2.5-Omni、Kimi-Audio等模型音频编码器的Whisper。▲音频编码器在X-ARES Benchmark上的分数对比
除了声音理解,Xiaomi Dasheng还可以用于音频生成任务,如语音降噪、提取和增强。
MiDashengLM的训练和推理效率是其另一项优势。对于单个样本推理的情形,即batch size为1时,MiDashengLM的首个token预测时间(TTFT)为Qwen2.5-Omni-7B的1/4。批次处理时,在80GB GPU上处理30秒音频并生成100个token的测试中,MiDashengLM可以把batch size设置为512,而Qwen2.5-omni-7B在batch size设置为16时即出现显存溢出(OOM)。▲Batch size=1时TTFT和GMACS指标对比
在实际部署中,MiDashengLM在同等硬件条件下可支持更多的并发请求量,降低计算成本。▲80G显存环境下模型每秒可处理的30s音频个数
这背后,MiDashengLM基于Xiaomi Dasheng架构,在维持音频理解核心性能指标基本持平的前提下,通过优化音频编码器设计,将其输出帧率从Qwen2.5-Omni的25Hz降至5Hz,降幅80%,降低了计算负载并实现了推理效率提升。
MiDashengLM采用通用音频描述对齐范式,避免了用ASR转录数据对齐仅关注语音内容而丢弃环境声音和音乐信息,且无法捕捉说话人情感、空间混响等关键声学特征的局限,通用描述对齐策略通过非单调的全局语义映射,迫使模型学习音频场景的深层语义关联。该方法可以使用几乎所有的数据,包括噪声或非语音内容,而基于ASR转录的方法会丢弃非语音数据如环境声或音乐,导致数据利用率低下,基于ASR的对齐方法在ACAV100M-Speech数据集上会损失90%潜在有用数据。▲MiDashengLM训练框架
MiDashengLM的训练数据通过多专家分析管道生成:首先对原始音频使用各种专家模型作语音、人声、音乐和环境声学的细粒度标注,包括使用Dasheng-CED模型预测2秒粒度的声音事件,再通过DeepSeek-R1推理大模型合成统一描述。全部训练数据的原始标签在预训练中被弃用,只采用利用上述流程生成的新的丰富文本描述标签,以迫使模型学习更丰富全面的声音信息。其中,来自ACAV100M的开源数据集经过上述流程重新标注后,形成了新的ACAVCaps训练集和MECAT Benchmark。MECAT Benchmark已于近期开源,ACAVCaps数据集将在ICASSP论文评审后开放下载。▲ACAVCaps训练数据集构建流程
此次MiDashengLM训练数据100%来自公开数据集,涵盖五类110万小时资源,包括语音识别、环境声音、音乐理解、语音副语言和问答任务等多项领域。MiDashengLM完整公开了77个数据源的详细配比,技术报告公开了从音频编码器预训练到指令微调的全流程。据官方信息,小米已开始对Xiaomi Dasheng系列模型做计算效率的升级,寻求终端设备上可离线部署。
作为影响自然语言交互体验的关键技术之一,小米Xiaomi Dasheng系列模型此次的升级,对其提升自家设备的AI交互体验有一定帮助,从智能家居、智能汽车到智能手机,各类产品均能受益。AI多模态是当下业界主攻的方向之一,小米重心转向造车后,在AI大模型领域发声并不多,小米未来在多模态领域能否带来更多模型创新,值得期待。(本文系网易新闻•网易号特色内容激励计划签约账号【智东西】原创内容,未经账号授权,禁止随意转载。)