
8月1日晚,谷歌宣布向 Google AI Ultra 订阅用户推出 Deep Think 功能,Gemini 2.5 Deep Think 模型在今年的国际数学奥林匹克竞赛 (IMO) 上夺得金牌。
谷歌表示,这是其最先进的人工智能推理模型,能够通过同时探索和考虑多个想法来回答问题,然后使用这些输出来选择最佳答案。
从昨天起,谷歌每月 250 美元的 Ultra 订阅用户将可以在 Gemini 应用程序中访问 Gemini 2.5 Deep Think。
Gemini 2.5 Deep Think 于 2025 年 5 月在 Google I/O 开发者大会上首次亮相,是谷歌首个公开的多智能体模型。这些系统会生成多个 AI 智能体来并行处理一个问题,这个过程比单个智能体消耗更多的计算资源,但往往会得到更好的答案。
除了 Gemini 2.5 Deep Think 之外,谷歌还表示将向特定数学家和学者群体发布其在国际海事组织 (IMO) 中使用的模型。
谷歌表示,该 AI 模型“推理只需数小时”,而不像大多数面向消费者的 AI 模型那样只需几秒或几分钟。该公司希望 IMO 模型能够加强研究工作,并旨在收集关于如何改进多智能体系统以用于学术用例的反馈。
谷歌指出,Gemini 2.5 Deep Think 模型比其在 I/O 大会上发布的模型有了显著改进。该公司还声称已经开发出“新颖的强化学习技术”,以鼓励 Gemini 2.5 Deep Think 更好地利用其推理路径。
谷歌在与 TechCrunch 分享的博客文章中表示:“Deep Think 可以帮助人们解决需要创造力、战略规划和逐步改进的问题。”
正如人们会花时间探索不同的角度、权衡各种潜在解决方案并最终完善答案,从而解决复杂问题一样,Deep Think 也通过运用并行思维技巧,突破了思维能力的界限。这种方法让 Gemini 能够同时产生多个想法,并同时进行思考,甚至随着时间的推移不断修改或整合不同的想法,最终得出最佳答案。
此外,通过延长推理时间或“思考时间”,DeepMind 研发团队给了 Gemini 更多的时间来探索不同的假设,并为复杂问题找到创造性的解决方案。
此外,谷歌还开发了新颖的强化学习技术,鼓励模型利用这些扩展的推理路径,从而使 Deep Think 随着时间的推移成为更好、更直观的问题解决者。
深度思考可以帮助人们解决需要创造力、战略规划和逐步改进的问题,例如:
迭代开发和设计: Deep Think 在处理需要逐个构建复杂内容的任务时表现出色,这给我们留下了深刻的印象。例如,技术团队观察到 Deep Think 可以同时提升 Web 开发任务的美观度和功能性。

Gemini 应用程序中的 Deep Think 使用平行思维技术来提供更详细、更有创意和更周到的回应。
科学和数学发现:由于深度思考能够推理高度复杂的问题,它可以成为研究人员的强大工具。它可以帮助构建和探索数学猜想,或推理复杂的科学文献,从而有可能加速发现的进程。
算法开发和代码: Deep Think 特别擅长解决棘手的编码问题,其中问题的制定和对权衡和时间复杂性的仔细考虑至关重要。
Deep Think 在衡量编码、科学、知识和推理能力的挑战性基准测试中也表现突出。
例如,与其他不使用工具的模型相比,Gemini 2.5 Deep Think 在 LiveCodeBench V6(用于衡量竞争性代码性能)和 Humanity's Last Exam(HLE 是一项极具挑战性的测试,旨在衡量 AI 回答数千道数学、人文和科学领域众包问题的能力)中均取得了最佳性能。
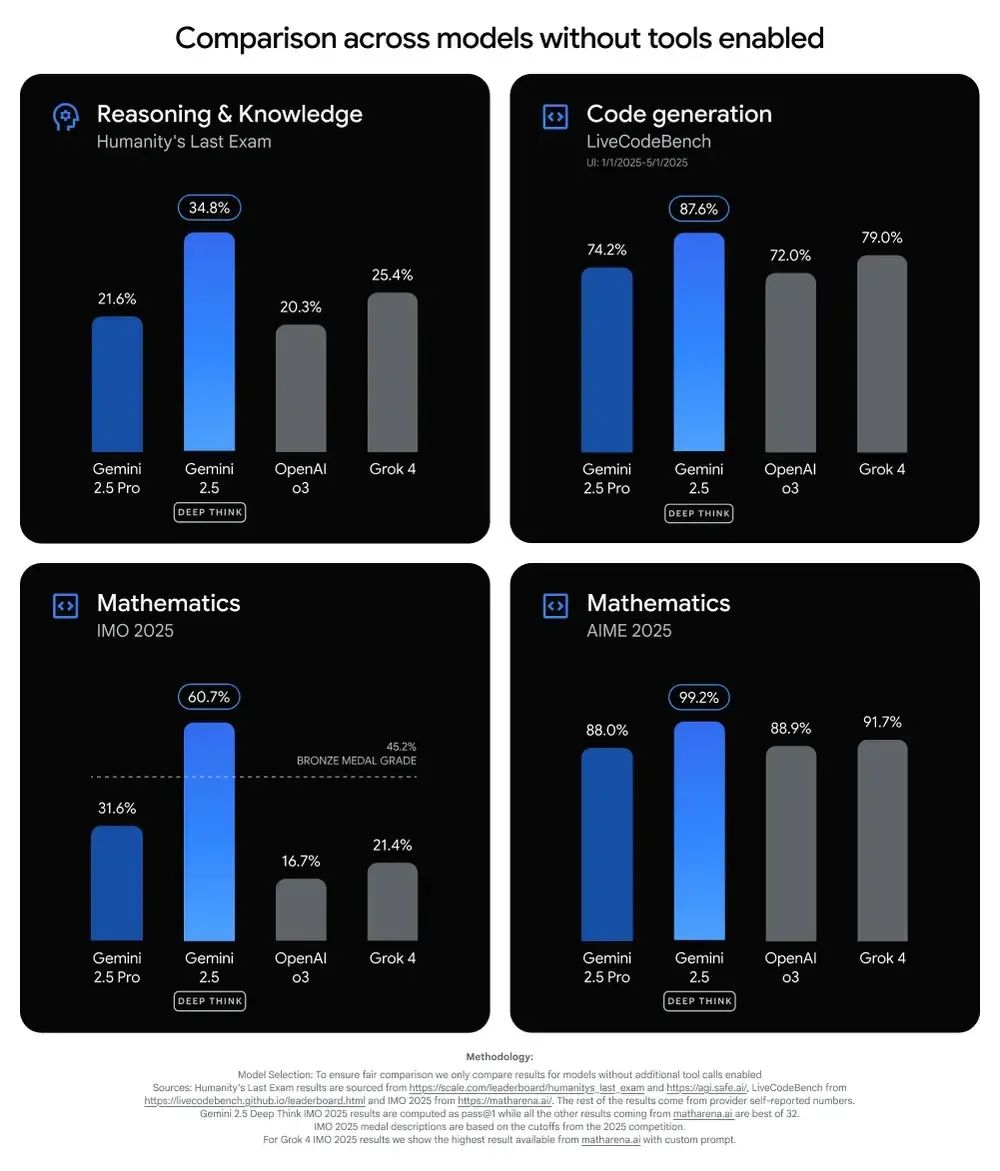
谷歌声称,其模型在 HLE(不使用工具)上的得分为 34.8%,而 xAI 的 Grok 4 得分为 25.4%,OpenAI 的 o3 得分为 20.3%。
谷歌还表示,Gemini 2.5 Deep Think 在 LiveCodeBench 6 中的表现优于 OpenAI、xAI 和 Anthropic 的 AI 模型。谷歌的模型得分为 87.6%,Grok 4 得分为 79%,OpenAI 的 o3 得分为 72%。
谷歌最新发布的 Gemini 2.5 Deep Think 模型在社交媒体和科技论坛上引发了热烈讨论,尤其是在 Hacker News、Reddit 和 X(原 Twitter) 等平台上。许多网友第一时间进行了测试,并分享了他们的使用体验和看法。
在 X 上,有网友尝试过 Gemini 2.5 Deep Think 后表示,其上下文窗口比 Gemini 2.5 Pro 要短。


有网友认为这款新模型棒极了,并考虑买个 Ultra sub。

还有网友认为,这款模型的一些基准测试结果好得让人震惊,即便这样谷歌也没有高调宣传它。
但也有网友对这款模型并不买账,认为与顶级模型相比,其性能没什么竞争力。该网友表示:
“我开始用这个新的 Deep Think 代理进行一些实验,但五次提示后就达到了每日使用上限。每月 250 美元的价格实在令人难以接受。与 o3-pro 和 Grok 4 Heavy 相比,它简直毫无竞争力。在性能方面,目前为止我甚至还没能看出什么明显优势。我向它提出了一个我公司面临的棘手组织问题,并提供了相关背景信息,它确实提出了一个清晰、经过深思熟虑的解决方案,与我们内部讨论的内容一致。但值得注意的是,o3 以更低的成本得出了同样有效的结论,尽管它的报告在“综合能力”方面略逊一筹。看来,我得等到明天才能了解更多关于这个 Agent 的实际性能信息了。”
也有网友认为,不能指望谷歌新模型做到十分完美,因为即使最顶尖的模型也有时候会“拖后腿”,而且“输入一个问题就能生成代码”也不是件新鲜事,大模型出来前就已经有了,只不过没那么好用罢了。
“它们在训练集中见过但未加权的数据上表现得非常糟糕。即使是最优秀的模型——比如表现出色的 Opus 4,以及时常带来惊喜的 Qwen 和 K2——在一些不那么显眼的方面也会拖后腿。
最明显的例子可能就是构建系统相关的内容:你一眼就能看出哪些模型“见过”大量的 nixpkgs 数据。而即便是最好的模型,似乎也很难很好地处理 Bazel,甚至有时连 CMake 都搞不定。
那些顶级的搜索引擎每天烧掉超过一百美元的成本,我认为它们比 SEO 时代之前的 Google 或 Stack Overflow 有了明显的提升……但如果和一个真正好用的搜索索引相比,还算不上“遥遥领先”。曾经,几乎所有编程主题的源代码、文档和故障排除信息,Google 搜索首页都能展示出来。那时候的体验就像是:你在那个神奇的搜索框里输入一个问题,立马就能弹出一段能用的代码。在 FAANG 的黄金时期,内部也有那种超强的 grep 工具,效果类似。
我感觉有一两代人会觉得“输入一个问题就能生成代码”是一件很新奇的事。但其实,这根本不是什么新鲜事——只是我们过去这五到十年里没再用过而已。”
参考链接:
https://techcrunch.com/2025/08/01/google-rolls-out-gemini-deep-think-ai-a-reasoning-model-that-tests-multiple-ideas-in-parallel/
https://blog.google/products/gemini/gemini-2-5-deep-think/
首届 AICon 全球人工智能开发与应用大会(深圳站)将于 8 月 22-23 日正式举行!本次大会以 “探索 AI 应用边界” 为主题,聚焦 Agent、多模态、AI 产品设计等热门方向,围绕企业如何通过大模型降低成本、提升经营效率的实际应用案例,邀请来自头部企业、大厂以及明星创业公司的专家,带来一线的大模型实践经验和前沿洞察。一起探索 AI 应用的更多可能,发掘 AI 驱动业务增长的新路径!

今日荐文
DeepSeek V4 借实习生获奖论文“起飞”?梁文峰剑指上下文:处理速度提10倍、要“完美”准确率
一个“蠢问题”改写模型规则!Anthropic联创亲曝:瞄准Claude 5开发爆款应用,最强模型的价值会让人忽略成本负担

你也「在看」吗?👇










