
MIND Project
Massive BCI Interaction and Neural Dataset



01
MIND Dataset Background

The history of scientific and technological progress is replete with examples of transformative leaps catalyzed by the creation of large-scale, high-quality, and publicly accessible datasets. In artificial intelligence, the ImageNet Large Scale Visual Recognition Challenge, with its millions of labeled images, created the "ImageNet moment"—a pivotal event that fueled the deep learning revolution. It provided the fertile ground for architectures like AlexNet to demonstrate their power, leading to breakthroughs in object recognition that now underpin technologies from autonomous vehicles to medical image analysis. Similarly, the recent success of Large Language Models (LLMs) is built upon the bedrock of vast text and code corpora like Common Crawl and The Pile, which enabled the scaling of transformer models to unprecedented capabilities. In robotics and embodied AI, progress in training intelligent agents to navigate and interact with the world is increasingly driven by extensive simulation data from platforms like Habitat and Gibson, which allow for safe and scalable policy learning.

This paradigm extends far beyond AI. In genomics, the Human Genome Project and The Cancer Genome Atlas (TCGA) produced massive, standardized biological datasets that have become indispensable for drug discovery, personalized medicine, and our fundamental understanding of disease. In astronomy, the Sloan Digital Sky Survey created a comprehensive three-dimensional map of the universe, leading to countless discoveries about the large-scale structure of the cosmos. In each case, a concerted effort to build a foundational dataset served as a powerful catalyst, democratizing research and unleashing a wave of innovation.
Despite these advances, the field of Brain-Computer Interfaces (BCI) has remained data-constrained. Progress in developing robust, high-performance, and generalizable BCIs—particularly those using non-invasive methods like electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS)—has been hampered by a lack of large, diverse, and standardized datasets. This data scarcity limits the potential of advanced machine learning models and impedes the translation of BCI technology from controlled laboratory settings to real-world applications. To address this critical gap, we are proud to announce the launch of a new, ambitious initiative: the "Massive Interaction and Neural Dataset (MIND)" Our mission is to create and openly share a foundational dataset that will serve as a catalyst for innovation across neuroscience, machine learning, and human-computer interaction.

02
MIND Dataset Project Overview

The MIND dataset project, initiated and organized by Machine Robot, is a large-scale, multi-task, foundational brain-computer interface (BCI) dataset project on a global scale. It aims to overcome the main obstacles in BCI and human-computer interaction by supporting a collection of AI models and algorithms with this dataset, thereby helping to advance the advent of the BCI era. Machine Robot Technology has accumulated many years of experience and understanding in various areas, including BCI hardware platform development, BCI data platform construction, BCI algorithm platform design, and multi-scenario BCI interaction tasks. Since 2021, Machine Robot Technology has also continuously collaborated with numerous universities and medical institutions, both domestically and internationally, to build and implement several BCI dataset projects for different tasks, accumulating valuable experience for the development of the MIND large-scale, real-world scenario BCI dataset project.
The construction of the specialized MIND BCI dataset project aims to establish a data collection paradigm that supports various types of BCI devices across different real-world applications and interaction scenarios, while continuously collecting effective data. The project focuses on achieving goals such as comprehensive BCI device support, numerous interaction tasks, wide coverage of brain regions, refined collection paradigms, fine data granularity, and accurate data labeling. It further seeks to create a new generation of human-computer interaction paradigms based on thought-driven interaction, hoping to one day seamlessly integrate human intelligence with artificial intelligence, and ultimately usher in the era of AI 4.0 (Artificial Intelligence inspired by the brain and BCI — Brain-Computer Interface and Brain-Like Intelligence).

AI4.0BCI and brain-inspired intelligence
(1)MIND Dataset Equipment
The dataset project will support different types of medical, research, and interactive brain-machine related data collection device systems that meet the corresponding signal quality. The main equipment will cover various mainstream and large-scale application brands, as shown in the figure below (not an exhaustive list,only some devices are included).
Device model | Device display image | Scenario | Recommended tasks |
Delikai-EEG series |  | laboratory | to be determined |
Natus-NicoletOne |  | laboratory | to be determined |
Neuracle -NSEseries |  | laboratory | to be determined |
Neuracle - NeuSen Wseries- |  | laboratory/open environment | to be determined |
NeuroDance |  | laboratory/open environment | to be determined |
ANT Neuro-visor2 |  | laboratory | to be determined |
ANT neuro-WaveGuardseries |  | laboratory/open environment | to be determined |
EGI-GESseries |  | laboratory | to be determined |
Natus- LTMseries |  | laboratory | to be determined |
Nox-A1sseries |  | laboratory | to be determined |
BEL-EEG system |  | laboratory | to be determined |
Kangdi-neuroscanseries |  | laboratory | to be determined |
Brain Products-BrainAmpseries |  | laboratory | to be determined |
Philips-Aliceseries |  | laboratory | to be determined |
SOMMOmedics-PSGseries |  | laboratory | to be determined |
Neuroelectrics-portable EEG cap- |  | laboratory/open environment | to be determined |
Emotiv-portableEEGhead-mounted device |  | laboratory/open environment | to be determined |
X-BCI brain-computer interface platform device |  | laboratory/open environment | to be determined |
BrianCo headband |  | laboratory/open environment | to be determined |
(2)MIND Dataset channel configuration
This brain-machine interaction dataset includes different types of brain-machine devices corresponding to different channels, mainly1、2、4、8、16、22、42、64、128、256and other channels. The standard layout rules for channel placement are shown in the figure below.

 16-32Channel brain-machine channel layout reference diagram
16-32Channel brain-machine channel layout reference diagram 32-64Channel brain-machine channel layout reference diagram
32-64Channel brain-machine channel layout reference diagram 64-128Channel brain-machine channel layout reference diagram
64-128Channel brain-machine channel layout reference diagram 128-256Channel brain-machine channel layout reference diagram
128-256Channel brain-machine channel layout reference diagram
3) MIND Dataset Tasks
The MIND dataset primarily targets the various human-computer interaction (HCI) tasks encountered in real-world application scenarios of artificial intelligence and brain-computer interface (BCI) technology. It mainly includes 5 major categories of datasets, centered on interaction tasks:
a. State Task Dataset; (20%)
b. Interaction Task Dataset; (30%)
c. Neurofeedback Dataset; (20%)
d. Multimodal Interaction Dataset; (20%)
e. Mental and Neurological Health Dataset; (10%)
This dataset supports collection from different types of devices and allows for parallel data acquisition from multiple source devices, such as eye-tracking signals and motion signals. At the same time, this dataset project will introduce VR, AR, and smart glasses as content and interaction mediums for BCI data collection. The main requirements are to achieve a full range of data interaction tasks, use a wide variety of collection devices, collect refined signals, ensure fine data granularity, and provide accurate data annotation.

MINDDataset collection system
 MIND Dataset collection plan
MIND Dataset collection plan(4)MIND Dataset Project Plan
The MIND Dataset Project is expected to complete the construction of an ultra-large-scale BCI dataset within 5 years, accumulating 100,000 participant sessions across more than 100 different brain-computer interface (BCI) tasks. The main project plan is as follows:
Year 1: Foundational sample data paradigm and dataset collection (2025.10.01 - 2026.09.30)
Year 2: Large-scale dataset collection and evaluation (2026.10.01 - 2027.09.30)
Year 3: First-phase large-scale dataset collection and release (2027.10.01 - 2028.09.30)
Year 4: Second-phase large-scale dataset collection and release (2028.10.01 - 2029.09.30)
Year 5: Third-phase large-scale dataset collection and release (2029.09.30 - 2030.09.30)
The dataset construction will officially launch on October 1, 2025, and will complete the primary data sample paradigm construction and sample dataset collection by September 30, 2026. It will also provide distribution and support of collection tasks and protocols for the participating open-source contributors from the first year. On October 1, 2027, the first phase of large-scale dataset task allocation, data collection acceptance testing, and data annotation will be initiated. The first phase of the MIND dataset will be officially released for industry use on October 1, 2028. Subsequently, the data scale will continue to expand, with the second and third phases of the MIND dataset scheduled for successive release on October 1, 2029, and October 1, 2030, respectively.
04
MIND Dataset Collection Tasks and Plans

MIND At its inception, the MIND Dataset Project is positioned to primarily include 5 major categories of datasets centered on interaction tasks:
(1) Mind State Task Dataset
(2) Brain Interaction Task Dataset
(3) Neurofeedback Dataset
(4) Multimodal Interaction Dataset
(5) Mental and Neurological Health Dataset
Each of these categories corresponds to different types of supported collection tasks and recommended collection scenarios to meet the corresponding quality and generalization requirements during the dataset construction process.

(1) Collection Task Description
State Task Dataset: Includes dozens of state tasks such as mental states (e.g., fatigue, concentration, alertness), emotional states, and motor perception states.
Interaction Task Dataset: Includes dozens of interaction commands such as control commands, operational commands, and communication commands.
Neurofeedback Dataset: Includes feedback interaction commands for data types such as tactile, olfactory, gustatory, and auditory perception.
Multimodal Interaction Dataset: Includes dozens of interaction tasks that integrate data from dimensions such as eye tracking, body movement, and physiological sensing.
Mental and Neurological Health Dataset: Primarily includes datasets related to common mental disorders (e.g., depression, anxiety, insomnia) and neurological health conditions (e.g., Parkinson's, ALS, Alzheimer's).
(2) Data Collection Process Description
The MIND data collection process mainly includes the following steps: task claiming, equipment declaration and calibration, paradigm validation and release, data collection and annotation analysis, data submission and acceptance, standardization processing, and data approval. Specifically, collection tasks will be reasonably recommended and allocated based on the collection environment and equipment configuration of the applying team. The collecting team will be provided with a validated, standard collection paradigm. After data collection is complete, the initiating party and the collecting party will jointly advance data annotation and basic data screening. Upon completion of the above steps, the initiating party will conduct data verification and acceptance. Once standards are met, the initiating party will perform unified data standardization processing, followed by centralized storage and classified management. After reaching the corresponding scale and standard, data access will be provided externally.

(3) Collection Plan Description
Collection Paradigm: MIND data collection paradigms will be uniformly designed and defined by the initiating party. After the sample dataset collection and validation are complete, they will be synchronously released to participating collection sites to ensure the consistency of data acquisition paradigms for the same interaction tasks.
Equipment Calibration: The collecting party will cooperate with the initiating party to perform calibration according to the calibration plan. After passing calibration tests, task allocation and collection can proceed to ensure the usability of the equipment and the transferability of the collected data.
Dataset Annotation: The initiating party and the collecting party will jointly set labels and perform effective data matching and selection. Data precision and label accuracy will be guaranteed through strict control over data annotation.
Data Standardization: This will be designed, developed, and implemented by the initiating party. Data standardization will achieve consistency and reusability of data from different devices, facilitating cross-device data usage and model training.
Data Calibration: This will be performed by the initiating party. The initiator will use high-precision BCI systems to build benchmark datasets for different interaction tasks under various paradigms. Datasets provided by different collectors will be uniformly analyzed and calibrated against these benchmark datasets to ensure the stability and usability of the data quality.
Data Warehousing and Release: After data calibration, data will undergo unified cleaning and format standardization. It will be stored in a database organized by task. Once the data in the repository reaches a certain scale, model evaluations will be conducted. After stable evaluation results are achieved, the data access channel will be formally opened to the public.
(4) Data Sharing Rights Description
The MIND Dataset Project adheres to the principles of openness and collaboration, dedicated to creating a dataset that serves the global BCI interactive application industry. Access and usage rights to this dataset will be freely open to core contributing units participating in the data collection project. It will also provide model platform training support to scientific research institutions and startup BCI technology companies.
a. Core Contributors: Individuals or teams that undertake the main collection tasks for the MIND dataset will have access rights to the entire dataset.
b. Non-Core Contributors: Individuals or teams that participate in some of the MIND dataset collection tasks will be granted access to relevant domain datasets and restricted acquisition rights.
c. Research and BCI Tech Teams: Research and technology teams that did not participate in the MIND data collection tasks will be provided with access for model training on an online platform.
(5) Suggested Participants
University BCI labs, BCI technology companies, individual BCI researchers
Hospital psychiatry departments, hospital sleep medicine department.
05
Appendix - Introduction to
Past BCI Dataset Projects

(1) Sleep and Dream BCI Dataset Project
Time: 2021
Partner: Zhejiang University
Dataset Purpose: R&D for BCI dream interaction products
(2) ALS Brain State Dataset Project
Time: 2022
Partner: Peking Union Medical College Hospital
Dataset Purpose: Scientific research project
(3) ALS Brain Visual Memory Reconstruction Dataset Project
Time: 2023
Partner: Peking Union Medical College Hospital
Dataset Purpose: Scientific research project
(4) Emotion Interaction Dataset Project
Time: 2024
Partner: Zhejiang University
Dataset Purpose: R&D for BCI emotion interaction products
(5) Normal Population Visual Memory Reconstruction Dataset Project
Time: 2024
Partner: Shanghai Jiao Tong University
Dataset Purpose: Scientific research project
(6) BCI Technology Competition Dataset
Time: 2025
Location: Beijing BCI Laboratory
Dataset Purpose: Model training dataset for a BCI technology competition
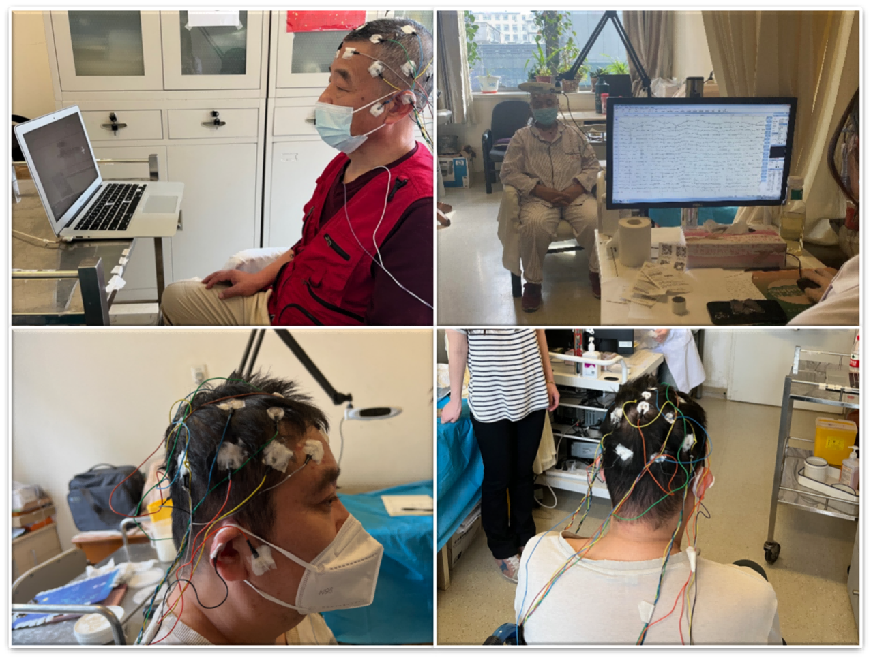 2022 ALS brain state dataset collection
2022 ALS brain state dataset collection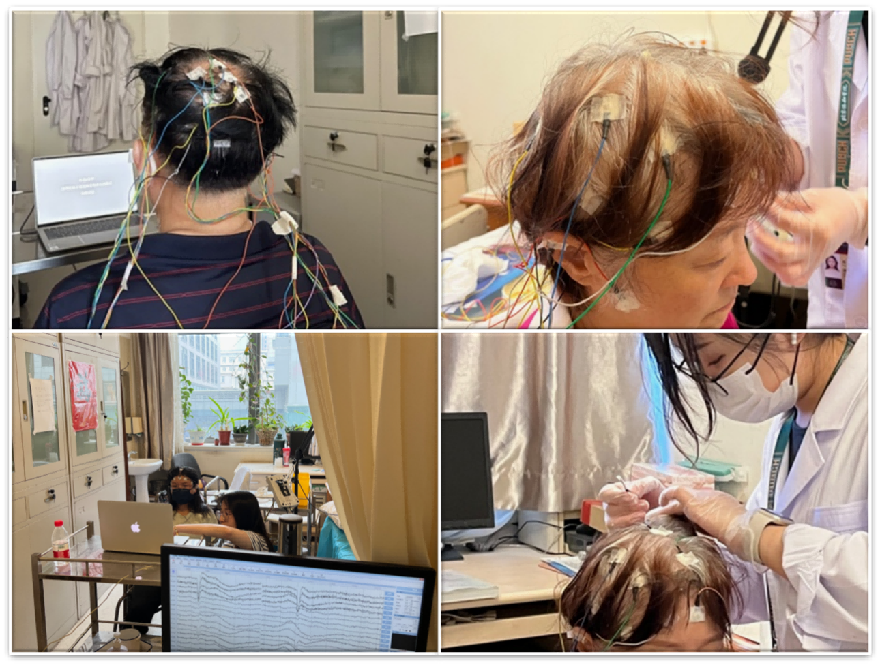 2023 ALS visual memory data collection
2023 ALS visual memory data collection 2024 Visual memory reconstruction data collection
2024 Visual memory reconstruction data collection 2024 Affective interaction data collection
2024 Affective interaction data collection 2025 BCI competition dataset collection
2025 BCI competition dataset collection
06
MIND Dataset Project Participation and Inquiry

The MIND Dataset Project will officially launch on October 1, 2025. Relevant organizations and personnel are welcome to participate in the data collection and make inquiries. A dedicated website will be launched subsequently to synchronize the project plan, publish data collection tasks, and provide related information for task review and application. Please stay tuned!
Contact Person: Alex Chen
Contact Email: xinchen@maschinerobot.com
END
bp@maschinerobot.com
简历投递
hr@maschinerobot.com
关注智姬公众号
获取更多精彩内容