打造一个有温度、有趣味、专业的全栈式AI&AIGC交流社区,
用心写好每一篇文章!
项目主页-https://virtu-lab.github.io/
代码链接-https://github.com/Virtu-Lab/DreamVVT
论文链接-https://arxiv.org/pdf/2508.02807

01-DreamVVT核心优势
DreamVVT是字节最新提出的一个基于扩散变换器(DiTs)的精心设计的两阶段视频虚拟试穿框架,它能够利用各种不成对的以人为中心的数据来增强现实世界场景中的适应性。
为了进一步利用预训练模型和测试时间输入的先验知识,在第一阶段,作者从输入视频中采样代表性帧,并利用与视觉语言模型(VLM)集成的多帧试穿模型来合成高保真度和语义一致的关键帧试穿图像。这些图像可作为后续视频生成的补充外观指南。
在第二阶段,从输入内容中提取骨架图以及细粒度的运动和外观描述,然后将这些与关键帧试穿图像一起输入到用LoRA适配器增强的预训练视频生成模型中。这确保了看不见区域的长期时间一致性,并实现了高度合理的动态运动。
02-DreamVVT变现场景
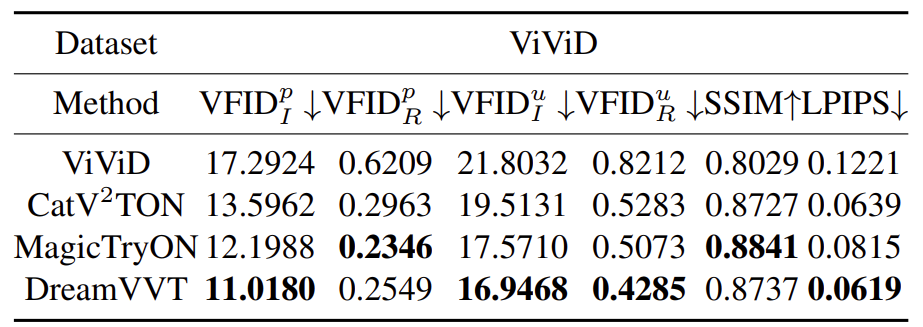
03-DreamVVT性能评估


关注我,AI热点早知道,AI算法早精通,AI产品早上线!

禁止私自转载,需要转载请先征求我的同意!
欢迎你的加入,让我们一起交流、讨论与成长!
