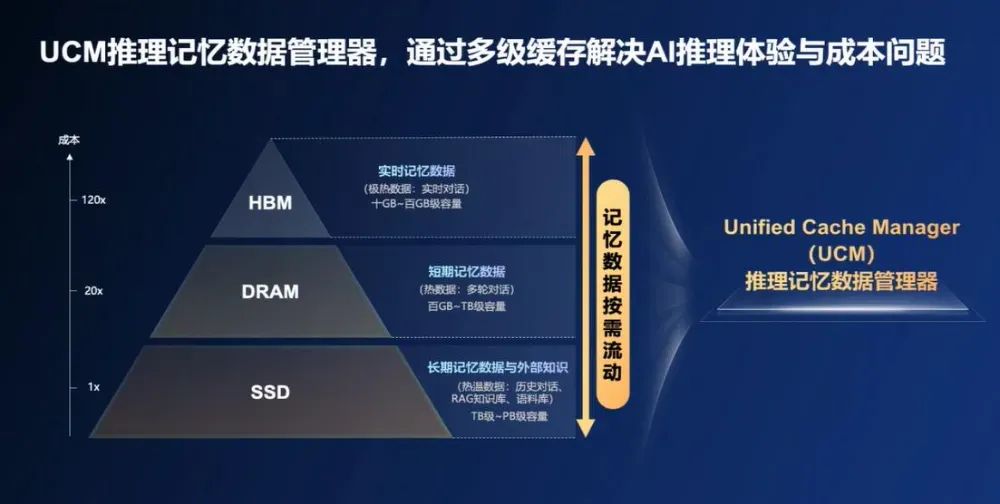
电子发烧友网报道(文/章鹰)8月12日,在2025金融AI推理应用落地与发展论坛上,华为公司副总裁、数据存储产品线总裁周越峰宣布,华为此次和银联联合创新,推出AI推理创新技术UCM(推理记忆数据管理其器)和管理系统的算法,这项突破性成果降低对HBM技术的依赖,提升国内AI大模型的推理能力。该技术是一款以KV Cache为中心的推理加速套件,UCM集成了多类型缓存加速算法工具,实现推理过程中KV Cache记忆数据的分级管理,从而扩大推理上下文窗口,提升推理效率。“银联的实际案例和大量测试显示,UCM显著降低首Token的时延,最高降低90%,系统吞吐率最大提升22倍,上下文的推理窗口可以扩展10倍以上,这是对于AI推理系统一个巨大的进步。” 周越峰指出。华为UCM技术已率先应用在中国银联“客户之声”、“营销策划”和“办公助手”三大业务场景,开展智慧金融AI推理加速应用试点,并且已经取得成果。华为表示,计划于2025年9月正式开源UCM,将在魔擎社区首发,并共享给业内所有Share Everything(共享架构)存储厂商和生态伙伴。AI大模型推理给存储带来哪些挑战?UCM的创新之处如何解读?本文结合中国信通院人工智能研究平台与工程化部主任曹峰、华为数据存储产品线AI存储首席架构师李国杰的观点,进行详细分析。AI大模型推理给存储带来三重挑战“ChatGPT的访问量呈现线性增长,最新访问量达到4亿,受益于中国AI大模型DeepSeek爆发,日均调用量也在快速上升,2025年1月开始,中国AI推理的需求增长20倍,未来三年算力需求爆发。IDC表示,2024年算力需求60%是训练,40%是推理,到2027年中国用于推理的算力需求——工作负载将达到72.6%。” 中国信通院人工智能研究平台与工程化部主任曹峰分析说。当下,AI大模型推理应用落地中,遇到推不懂、推得慢和推得贵的三大挑战。首先,长文本越来越多,输入超过模型上下文窗口的内容,推理窗口小就推不动;其次,由于中美在AI基础设施的差距,中国互联网大模型首Token时延普遍慢于美国头部厂商的首Token时延,时延长度为后者的两倍;推得贵,美国大模型的推理吞吐率为中国大模型推理吞吐率的10倍。华为公司副总裁、数据存储产品线总裁周越峰指出,AI时代,模型训练、推理效率与体验的量纲都以Token数为表征,Token经济已经到来。在AI基础设施投资,中国和美国有差距,为了保障流畅的推理体验,企业要加大算力投入,但是如何改善AI推理的效率和体验,在推理效率与成本之间找到最佳平衡点?华为推出UCM,以KV Cache和记忆管理为中心提供全场景化系列化推理加速能力。UCM两大关键能力和创新算法,破解HBM受困难题HBM是解决"数据搬运"的关键技术。当HBM不足时,用户使用AI推理的体验会明显下降,导致出现任务卡顿、响应慢等问题。华为此次技术突破有望缓解这一瓶颈。华为重磅推出UCM推理记忆数据管理器,包括对接不同引擎与算力的推理引擎插件(Connector)、支持多级KV Cache管理及加速算法的功能库(Accelerator)、高性能KV Cache存取适配器(Adapter)三大组件,通过推理框架、算力、存储三层协同,实现AI推理“更优体验、更低成本”。UCM的创新之处,在于可以根据记忆热度在HBM、DRAM、SSD等存储介质中实现按需流动,同时融合多种稀疏注意力算法实现存算深度协同,使长序列场景下TPS(每秒处理token数)提升2至22倍,从而降低每个Token的推理成本。“实时数据放在HBM当中,短期记忆数据放在DRAM中,其他数据就放在共享存储SSD中,极大提高系统的效率和AI推理能力。针对AI推理平衡成本和效能的挑战,华为推出UCM统一的记忆数据管理器,在两个层面以系统化的方案来解决问题。” 华为数据存储产品线AI存储首席架构师李国杰表示。在底层的框架和机制上提供了多级缓存空间,构建智能管理以及智能流动的基础框架能力。在此基础之上,华为构筑了一系列创新的推理的加速算法和加速特性,包括自适应的全局Prefix Cache,降低首Token时延与单位Token成本。采用动态的Training稀疏加速算法,倍数级提升长序列吞吐和体验。还有后缀检索、预测加速算法、PD检索加速和Agent原生记忆加速。UCM将超长序列Cache分层卸载至外置专业存储,通过算法创新突破模型和资源限制,实现推理上下文窗口的10倍级扩展,满足长文本处理需求。中国银联执行副总裁涂晓军分享说,华为与中国银联的联合创新技术试点中,在中国银联的“客户之声”业务场景下,借助UCM技术及工程化手段,大模型推理速度提升125倍,仅需10秒就可以精准识别客户高频问题,促进服务质量提升。众所周知,目前,AI大模型训练对内存带宽需求呈指数级增长,传统DDR内存已无法满足需求。HBM(高带宽内存)是一种专用内存技术,用于 AI 处理器、GPU 和 HPC 系统,这些系统中带宽和能效比原始容量更为重要。HBM3 每堆栈可提供高达 819 GB/s 的传输速度,对于支持大型语言模型 (LLM)、神经网络训练和推理工作负载至关重要。但是去年12月以来美国将HBM2E列入对中国的禁售清单,国产厂商HBM的突破还在推进中,华为推出UCM的重大意义,在于加速推进国产AI推理生态,其核心价值是推进更快的推理响应和更长的推理序列,以及更优化的成本。中国信通院人工智能研究平台与工程化部主任曹峰认为,国产化AI推理生态建设应该加速,KV Cache已经成为架构优化的焦点,以KV Cache为核心的推理方案迭出,背后依赖的高性能存储、先进调度策略的重要性愈发显现。 李国杰还强调指出,AI是一个快速发展的行业,每6个月就会迎来新一轮的技术革新,UCM不仅定位于当下,解决AI推理问题,未来发展UCM将从KV Cache分层管理走向Agentic AI原生记忆管理和应用加速。声明:本文由电子发烧友原创,转载请注明以上来源。如需入群交流,请添加微信elecfans999,投稿爆料采访需求,请发邮箱huangjingjing@elecfans.com。更多热点文章阅读7月28企扎堆IPO,半导体硅片领衔!拆分上市抢滩潮出现105亿!Amphenol史上最大收购!3天涨近70%,这家国产芯片公司有何魔力?窃取华为Wi-Fi技术商业秘密,14人全部判刑理想i8与乘龙卡车对撞测试引争议,多方最新回应点击关注 星标我们将我们设为星标,不错过每一次更新!喜欢就奖励一个“在看”吧!





 喜欢就奖励一个“在看”吧!喜欢就奖励一个“在看”吧!
喜欢就奖励一个“在看”吧!喜欢就奖励一个“在看”吧!









