·聚焦:人工智能、芯片等行业
欢迎各位客官关注、转发


推动AI推理进入商业正循环,成国内最紧迫任务
随着Agentic AI时代来临,模型规模扩张、长序列需求激增及推理任务并发量上升。
KV Cache容量增长已超出HBM承载极限,频繁内存溢出导致推理[失忆]现象,迫使GPU反复计算,引发延迟卡顿。
数据显示,海外主流大模型输出速度在200 tokens/s左右(时延约5ms),而中国普遍低于60 tokens/s(时延50-100ms),最大差距达10倍。
在上下文窗口支持上,海外模型如GPT-5和Claude 3.5普遍支持百万级Token,国内领先模型仅50万Token,且在长文本分析中遗漏关键信息的概率超过50%。
这种性能差距不利于中国AI的规模化推广,长期可能形成商业恶性循环,加剧企业投入减少、投资放缓,在国际AI竞争中落后。
因此,如何在不大幅增加算力基础设施投入的前提下,显著改善推理体验,推动AI推理进入商业正循环,已成为中国当前最紧迫的任务。

近期,在[2025金融AI推理应用落地与发展论坛]上,华为发布了AI推理创新技术UCM(推理记忆数据管理器)。
该技术借助创新架构降低对HBM的依赖,提升国产大模型推理效率,加速AI产业自主化进程。
华为副总裁、数据存储产品线总裁周跃峰强调,UCM以键值缓存(KV Cache)为核心,融合多种缓存加速算法工具,对推理生成的KV Cache数据进行分层管理,旨在扩展推理上下文窗口,提供高吞吐量、低延迟的推理服务,同时降低每个Token的处理成本。
华为UCM技术的核心理念清晰明:它避免将所有[记忆]数据都塞入昂贵且稀缺的HBM内存,而是依据数据访问频率进行分层管理。
高频使用的热数据保留在高速存储区,低频使用的冷数据则迁移至成本更低、容量更易扩展的存储设备中。
这种策略显著减轻了HBM的负担,在确保模型响应速度的同时大幅提升了记忆容量。
尤为关键的是,UCM通过软件层面对存储调度规则进行革新,将其封装成一套可适配多种推理引擎的统一解决方案。
据华为披露,该技术能显著提升长对话或长文本的处理效率,将首个字符生成时间缩短至原来的十分之一,并将模型的记忆范围扩展至过去的十倍。

在AI深入日常应用的当下,大模型的[推理]过程——即AI理解问题并生成答案的关键环节——才是真正创造价值的核心。然而,尤其在中文互联网环境,推理体验常不尽如人意。
华为昇腾计算产品部总裁周跃峰博士指出,当前模型训练与推理的效率均以Token数量为衡量标准,而[因基础设施投入的差距,国内大模型的首Token响应延迟普遍高于海外头部模型]。
数据显示,海外主流模型单用户输出速度已达200 Tokens/s(延迟5ms),而国内普遍低于60 Tokens/s(延迟50-100ms)。
这意味着国内用户在同等问题下获得响应的速度更慢,尤其在处理长对话或文档时,模型常出现[遗忘]上下文的现象——阅读后文时丢失前文信息。
造成这种差距的核心瓶颈之一,正是AI推理的[记忆能力]限制。
传统推理系统几乎完全依赖HBM和DRAM,却忽视了SSD等低成本、大容量存储的价值。
这就如同仅依赖大脑和短期记忆,拒绝使用笔记本与外部存档,结果要么无法记住完整信息,要么让宝贵的内存空间被大量低频数据占据。
华为UCM技术正是为解决这种[内存结构失衡]而生。
它通过智能算法,在推理过程中依据数据的热度和访问延迟需求进行分级存储:实时必需的热数据置于HBM;
即将使用但非紧急的数据存于DRAM;而体量庞大、访问稀疏的冷数据则下沉至SSD。
由此,HBM得以专注于最高优先级任务,彻底摆脱冷数据的无效占用,从而充分释放整个系统的推理效能。
针对AI推理的[不可能三角]
当前,AI推理在成本、效率和性能三者间难以兼顾的困境,已成为行业发展的核心瓶颈。
要理解这一现象,需从AI推理的关键机制——KV Cache(键值缓存)切入。
通俗而言,KV Cache相当于AI的[短期记忆系统],通过临时存储对话中的关键信息,避免重复计算,确保多轮对话和长文档分析等场景的流畅体验。
然而该机制在提升效率的同时,也带来三大核心问题:
①KV Cache占用大量GPU显存,在现有算力设施不足的情况下,导致复杂数据或长文本处理时出现信息遗漏,影响推理准确性。
②随着任务复杂度提升,KV Cache随文本量增长而膨胀,直接拖慢处理速度。多用户并发时尤为明显,表现为响应延迟或生成中断。
③GPU内存限制迫使可复用的KV Cache被频繁丢弃重建,造成算力资源浪费,高昂成本使中小企业难以负担,阻碍AI服务规模化。

针对上述痛点,华为最新推出的UCM实现突破性创新,该技术具备三大核心能力:
①分级存储:将KV Cache按访问热度分布在HBM(热数据)、DRAM(温数据)和SSD(冷数据)三级存储介质。
②算法优化:融合稀疏注意力算法,使AI精准聚焦关键信息。
③系统协同:通过推理引擎插件、功能库和高性能存取适配器实现全栈优化。
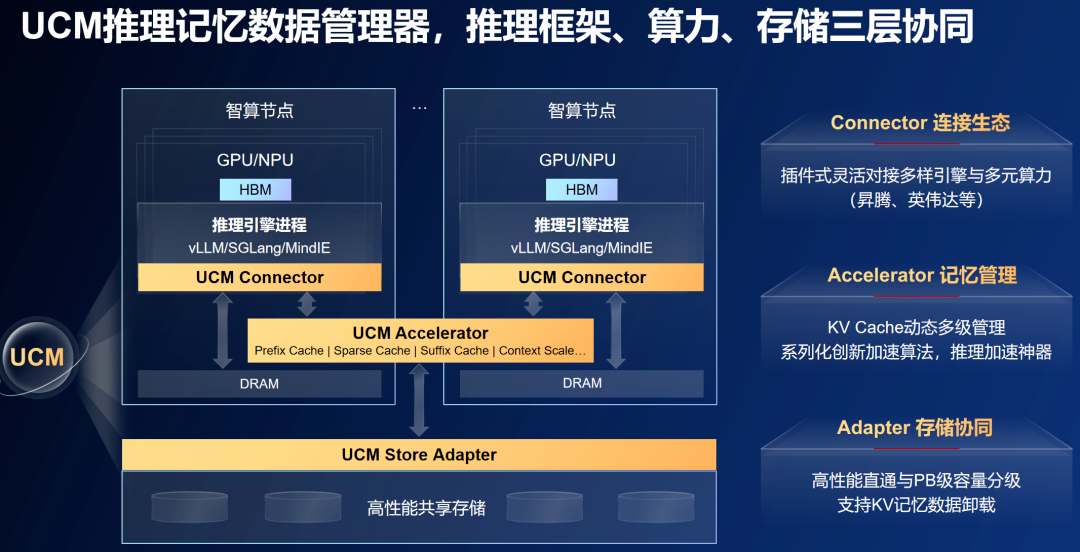
在结构设计上,华为的UCM解决方案主要由三大核心模块组成:
连接各类引擎与计算资源的推理引擎插件(Connector)、支持多级键值缓存管理和加速算法的功能库(Accelerator),以及高效键值缓存访问适配器(Adapter)。
这些模块协同实现了推理框架、计算能力和存储系统的三层优化。
通过标准化的开放接口,UCM能够兼容多种推理引擎框架、计算资源及存储方案。
对于推理框架开发者,UCM的接口简化了技术集成过程,助力提升框架性能和竞争力;
实测数据显示,UCM在长序列场景下使系统吞吐量提升2-22倍,显著降低单Token推理成本。

华为的UCM技术更像是一种[系统级补充方案],其目的并非替代HBM,而是通过降低对HBM的依赖,将HBM的优势精准应用于更合适的场景。
在该技术支持下,企业能在维持算力投入不变的前提下,仅需增加少量外置存储投资,即可实现缓存性能的[原地升级]。
长远来看,华为推出并开源UCM代表系统工程的突破,它将驱动中国AI产业进入[体验优化-用户增加-投资增长-技术迭代]的良性循环。
这场围绕[记忆机制]的技术突破,或将成为中国AI产业落地的关键转折点。
部分资料参考:智能Pro:《华为祭出AI推理黑科技UCM!海力士难了?不一定》,观察者网:《AI落地的关键堵点,华为用"黑科技"打通了》
本公众号所刊发稿件及图片来源于网络,仅用于交流使用,如有侵权请联系回复,我们收到信息后会在24小时内处理。
推荐阅读:



商务合作请加微信勾搭:
18948782064
请务必注明:
「姓名 + 公司 + 合作需求」