
大咖演讲回顾第3篇
智猩猩整理
编辑:mio
今年8月,清华大学特别研究员、星海图联合创始人赵行在2025世界机器人大会上带来了题为《前沿技术首发:星海图VLA模型——开启具身智能的新纪元》的主题演讲。
本次演讲的重要信息如下。
具身智能的公认路径:模仿学习+高质量数据。
具身智能数据金字塔:底端是互联网上的视频数据,中间是仿真数据,顶端是真实数据。
真实数据能打破具身智能能力上限,但也会面临Real2Real Gap。
为何要把机器人VLA模型分为快执行和慢思考两层模型?
自回归模型和扩散模型是当下最有效的两种大模型训练方法,合理地进行组合能够大幅提升具身智能VLA模型的效果。
跨本体的预训练效果远不如单本体的预训练效果,具身智能是一个从模型回到数据,再回看机器人本体的全链条的事情。
以下为赵行老师的演讲回顾。
赵行:大家好,我是星海图的赵行,很高兴今天有机会和大家进行分享。
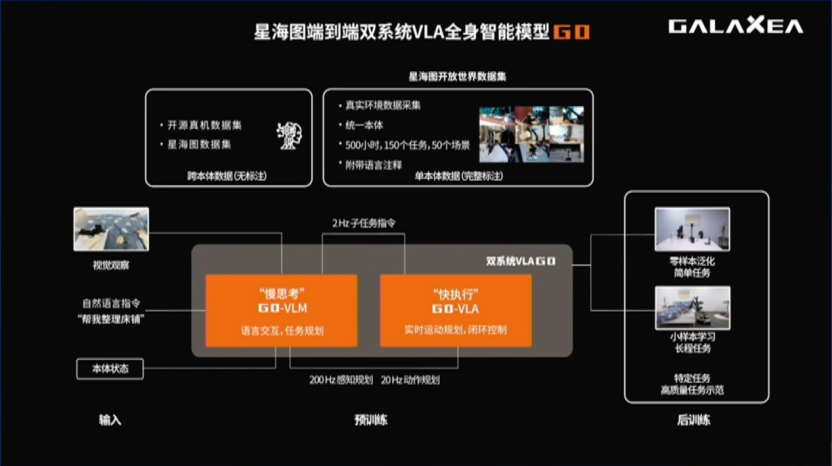
今天这个时间非常特殊,因为今天星海图正式发布了首个VLA模型——星海图G0,以及开源数据集——星海图开放世界数据集
我们把数据采集机器人部署到了真实的开放世界中进行数据采集,包括一系列的家庭生活服务的场景,采集员通过遥操作的方式控制机器人,让机器人去完成这些复杂的、长程的、日常的我们真正需要做的任务。数据集包含了500个小时的真实机器人与物理世界交互的数据,包含了在50个不同场景采集到的150个真实世界的任务。并且我们使用采集到的数据预训练了VLA模型G0。
在下游的任务里,比如说让机器人铺床这个任务上,G0模型展现出了强大的泛化能力。测试员可以随机打乱这个场景,机器人会观察环境并做出决策,最后闭环控制完成任务。同时我们在一系列不同的任务和场景上进行了模型测试,比如说不同任务之间的串联,以及双臂操作等。
刚才大家看到的所有展示,都只使用了不到100条数据来进行模型训练所完成的。在这次WRC的展会上,大家也可以来我们展台,可以实时地看到我们的机器人进行铺床整理的展示,并且有相应的讲解。
Scaling Law的震撼与The Bitter Lesson的影响
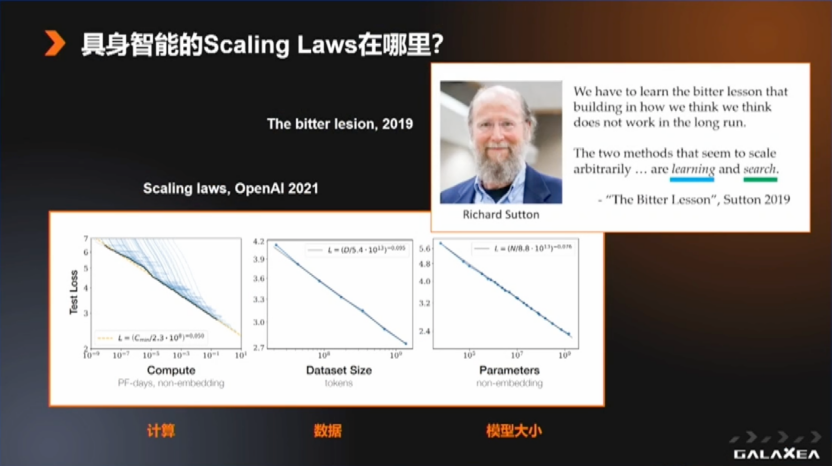
接下来说一说我们为什么要做这个事情。刚才说到我们发布了两个重磅的成果,第一个是数据集,第二个是模型。我自己在AI领域已经工作了十多年,在这十多年里给我最大的震撼是什么?第一个大家可能都知道,是OpenAI在几年前推出的Scaling Law。
ScalingLaw讲的是什么?讲的是AI模型随着数据规模、计算量以及模型大小的增长,其性能可以持续地提升。这不是学术界的经典论调,而是一个更偏工业界的和产业化的规律。就像摩尔定律一样,我们相信只要计算量能增加5倍到10倍, AI性能就也能够有相应5倍到10倍的提升。
另一个对我影响很大的,我相信也是对很多学AI的人影响很大的一个小论文,叫做《The Bitter Lesson》,是最近获得图灵奖的Richard Sutton提出的。他说在他对于AI过去发展70年的观察中,发现很多小的算法的改进或者方法的改进,其实并不能大幅提升模型的能力。相反的,随着计算的提升,AI才实现了真正的进展。当然,这个论调并不是说只有发展算力才是正确的路线,我们仍然要做方法。
那有哪两类重要的方法呢?他说我们要做元方法(Meta Methods),第一类元方法叫做学习,第二类元方法叫做搜索。
反观现在具身智能的发展,什么是学习?什么是搜索?学习就是说通过给机器人大量释义的数据,让机器人学会它应该怎么做。搜索就是通过让机器人自主地在环境里进行探索和试错,然后学会什么是正确的做法。
具身智能的公认路径:模仿学习+高质量数据
对应到具身智能的发展里,它正好对应两个重要的技术,第一个是模仿学习,第二个是强化学习。
模仿学习对于机器人操作领域来说,已经成为了公认的技术路线和方法。从谷歌到约翰斯·霍普金斯,从机器人医疗手术实验,到谷歌机器人的桌面操作和具身理解大模型,他们都使用了模仿学习这条技术路线。
当然,说到模仿学习,那就逃不开数据。模仿学习的算法可以通过聪明的工程师、科学家来获得。但是数据要怎么获得呢?
大家都知道具身智能的数据金字塔。在数据金字塔的底端是互联网上的视频数据,这些都是大家一起进行数据采集后上传的。这些数据的优点是让我们拥有了海量的数据体量,但这些数据里面没有动作的信息,我们可以从里面提取出人手的动作信息,但我们没有办法去想象在这样的数据里,机器人的动作该怎样执行。
在金字塔的中间是我们也常提到的仿真数据。仿真数据是一种非常有意思的切入方法,通过计算换时间,因为我们可以构建仿真器,并使用多台计算机同时进行并行仿真来获取数据,这样的数据获取速度会比我们在真实世界进行数据采集更快。但是它也遇到一个巨大的挑战,叫做Sim2Real Gap,也就是说在仿真里获取的数据和真实世界中真实发生的事情相差特别大。
在金字塔的顶端是大家更经常讨论的真机数据,也就是说我们要带着机器人去真实世界里采集数据。

真机数据可打破具身智能能力天花板
星海图认为真实的机器人数据是最重要的,是打破具身智能天花板上限能力的一个关键技术。但即便是真实数据也是有区别的,不仅存在Sim2Real Gap,甚至还存在Real2Real Gap。
什么是Real2RealGap呢?有很多团队和公司在积极地构建机器人的数据采集场。在这些数据采集场里,我们非常希望去构建一些复杂的环境,比如说构建一个家庭环境,这个家庭环境窗明几净、一尘不染,然后就在里面采集了很多的数据。但是当我们把机器人部署到真实的环境以后,东西会乱堆乱放,和我们的数据采集场完全不一样,那机器人瞬间就傻眼了,因为它不知道该如何去应对更加真实、更加复杂的场景。

意识到这个问题以后,我们在去年年底就决定开始做这个事情,也就是进入到真实的世界去采集数据。我们不希望机器人像赛车场里的赛车一样不停地绕圈,而是希望我们的车走到真实、公开的道路上,去面对真实的交通和驾驶场景。所以,我们也希望机器人到真实的家庭里去看一看、走一走、做一做、干一干,最后把数据收集回来,来训练我们的具身基础模型。

在G0数据标注与模型训练上的技术心得
接下来的内容,更多是我们在数据采集、标注和模型训练里的一些技术心得。
首先,我们发现数据标注特别重要,因为我们的目标是训练VLA模型(Vision Language Action)。其中Language的存在非常重要,因为Language定义了人类和机器人的交互界面,同时也会把原本长程的任务切分成小的任务,让机器人能更好地执行。

在完成了数据标注以后,我们的模型G0是一个双系统大模型,双系统大模型分为两个部分,系统一和系统二。系统一是端到端的快执行模型,系统二是一个慢思考、能和人类交互、把任务进行拆解的慢模型。通过这两个模型联合在我们的开放世界数据集上的训练,把它们联合部署到机器人上,最后能够端到端地完成我们要机器人面对的任务和问题。
为什么要把机器人的模型分为两层呢?我觉得这在生物进化上是有它的道理的。首先我们可以观察到,人类大脑皮层的视觉感知能力、语言中枢理解能力、以及小脑的控制能力和四肢身体运动能力,它们并没有运行在同一个频率上,这是为什么呢?这是进化的结果,进化告诉我们合理的分工是必要的,能够大幅提高能量的利用率,这对于机器人来说也是适用的。这样我们就能够把双系统模型真正地落地部署到机器人上,机器人不再会因为思考的慢,所以动作也变慢。
系统一和系统二是并行推理的、在不同的速度上的两个模型。但是这两个模型并不是孤立的,在进化的过程中,因为数据的原因,它们会自发地进行合理的信息和特征传递。往未来看,我甚至相信系统一和系统二的模型之间会相互进行转化,比如当第一天学一个任务的时候,要很严密地进行思考,但当第二次、第三次、第四次做同一个任务的时候,就不再需要大脑进行严密的思考了,我可以把这个运动和动作记下来,直接记在我的小脑模型里,然后直接自发地、下意识地去完成任务。
G0的算法设计:结合回归与扩散提升VLA效果
接下来讲一讲我们的算法设计,首先要分清模型、算法、数据它们是三个不同的概念。
我们接下来讲算法。在大模型时代有两个最火热的算法,第一个叫自回归模型(Next Token Prediction),第二个叫做扩散模型(Diffusion Model)。我们发现合理地组合这两种当下最有用、最有效的大模型训练方法,能够大幅提升具身智能VLA模型的效果。
具体来说,首先在第一阶段,我们使用跨本体的数据,通过自回归学习的Next Token Prediction的方法,进行第一阶段的模型预训练。
接下来使用星海图自己采集的单本体的高质量数据,进行第二阶段的预训练。不同的是第二阶段的预训练,我们会给机器人加上一个Action Expert或者Action Decoder,它也是一个Transformer模型。通过第二阶段的预训练,机器人能够真正学习到在单本体上控制自己身体的能力。
最后第三阶段是后训练的,如果面对的任务非常复杂和长程,那么我们大概率需要采集几条后训练的数据,然后来微调模型。第二阶段的预训练和后训练阶段使用的都是扩散模型的学习方法。
经过一系列的实验和分析发现,这样的训练方式和组合是能让我们得到最好结果的一个方案。

我们在一系列的任务上进行了对G0-VLA模型的评测,也和时下全世界最火的开源模型π0进行了对比,发现在许多的任务上,我们的预训练模型会优于π0。从多个模型平均下来的结果看,我们的G0模型超越π0模型20个百分点。
再接下来,我们还做了更极限的测试,让后训练数据只有20条,也就是说面对一个非常复杂的问题的时候,我们的预训练模型不再能够进行大规模的后训练了,它只能看到少量的示范。结果发现,即便在20条数据的情况下,我们的G0模型仍然能够表现的非常出色。

在这些任务里,有一些很有意思的观察,我们发现跨本体的预训练效果远不如单本体的预训练效果。这也就是说,机器人模型和机器人具身智能模型的能力其实是和本体紧密相关的,那么我们就要有针对性地,在想要使用的具身智能的本体上进行数据采集。这也告诉我们,实际上具身智能是一个从模型回到数据,再回看机器人本体的全链条的事情。
要把它做好,光靠我们一家公司是不够的。接下来,我们会重点去发展开发者群体,希望为具身智能的开发者群体提供好的硬件、好的数据、好的预训练模型的checkpoint,以及后训练微调的工具。希望通过这样的方式,让更多的开发者和我们一起把具身智能做好,迈向具身智能和人形机器人的下一个台阶。
我们的模型和数据集即将在接下来的几周内开源,欢迎感兴趣的同学、老师、开发者们来关注。谢谢大家!
点击蓝字 关注我们