作者 | vasgaowei 编辑 | 大模型之心Tech
原文链接:https://zhuanlan.zhihu.com/p/1927391836932142920
点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型没那么大Tech技术交流群
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
本文将探讨到2025年年中,生成和理解统一的多模态大模型的发展趋势,特别是图片理解和图片生成一体的多模态大模型,揭示该领域的重要进展和挑战。
本文将结合之前阅读的论文和一些工业界的进展,谈谈到2025年年中为止,生成和理解统一的多模态大模型的发展概况。如有不当之处,烦请指出,我再更正原文。
当然更详细论文介绍可以refer我的系列笔记生成和理解多模态大模型、生成和理解多模态大模型之二等。
首先要说明的是,本文谈的“生成和理解多模态大模型”主要指图片理解和图片生成一体的多模态大模型,至于更多模态理解和生成的(俗称Omini-LLM)大模型就不在谈论之列了,原因是这一个方向的学术界论文相比“图片理解和图片生成一体的多模态大模型”来说还是显著少了。不过也可以推荐一些早期的论文,供大家参考,比如Google的Unified-IO和Unified-IO-2(这个系列的工作可以看作是Omini-LLM的早期代表作)、阿里的OFA、复旦的AnyGPT、meta的CM3Leon和Chameleon(多模态预训练)还有ANOLE、VITA等工作,这些工作其实也对后面的一系列工作有很大的影响,其中AnyGPT、CM3Leon、Chameleon和ANOLE也比较新了,所以也会介绍一下。

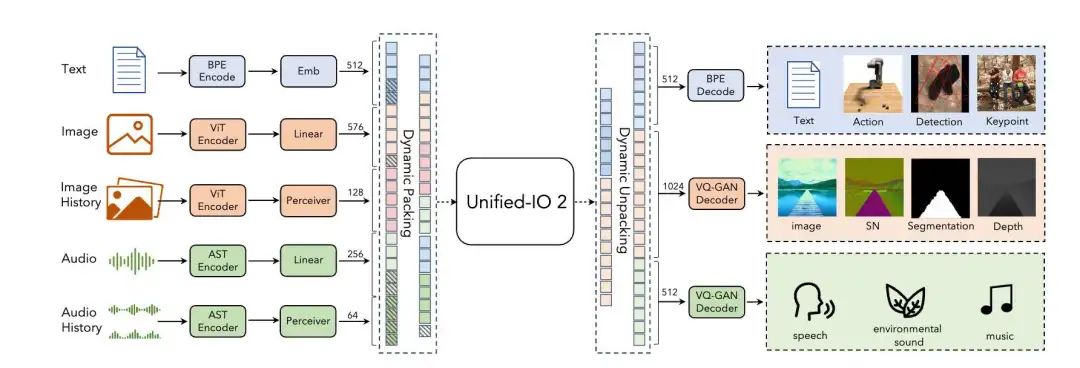


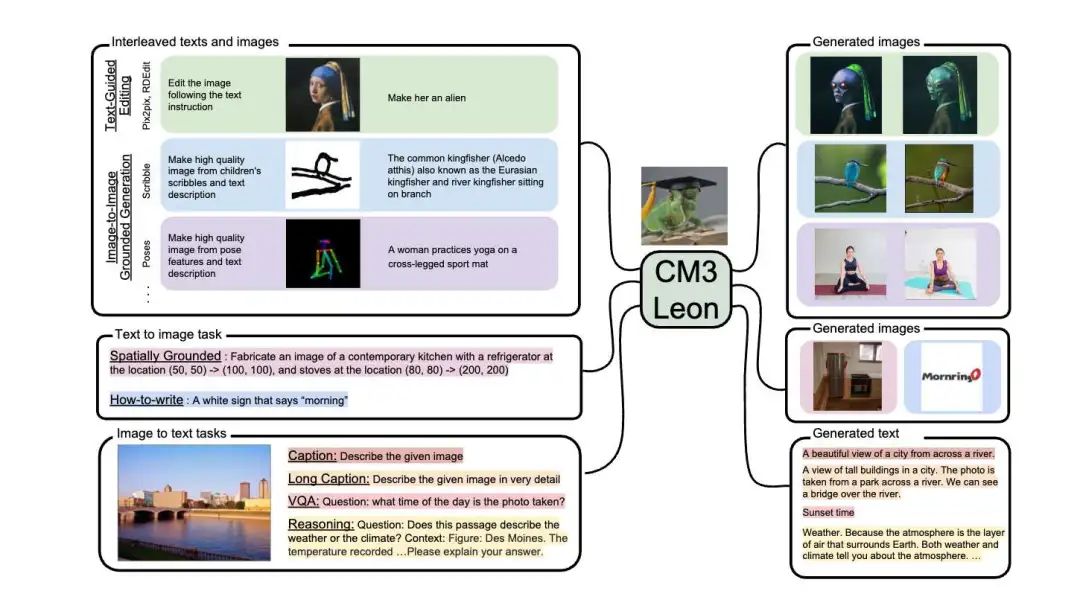


依照我之前阅读的论文,“生成和理解一体”的多模态大模型的研究主要集中在两个大方面:
训练一个适合于理解和生成任务的Visual Tokenizer,这样做的目的是大家发现视觉生成和理解所以来的视觉特征的特点是不一样的,视觉生成更依赖于偏高频、low-level的视觉特征,比如VAE-Based的特征,而视觉理解更偏向于偏高层语义的特征,比如CLIP、SigLIP等,不过一些早期的方法似乎不管这些,CLIP的视觉Encoder直接作为视觉生成的表征提取模型,不过后面就不是主流了。所以目前这方面的研究要么是 视觉生成和视觉理解特征分开提取 (比如DeepSeek的Janus、Janus-Pro),要么是训练一个 两种任务都适配的Visual Tokenizer ,比如字节跳动的Token-Flow、Muse-VL,港大的UniTok等,当然这一块也包含有 两个Visual Encoder 和 单个Visual Encoder 的。 构建一个适合于两种任务的多模态大模型结构,比如meta的meta-query、MetaMorph和Pisces、字节的Mogao和BAGEL等,包括自回归、自回归+扩散、纯扩散(目前还较少,可以参见字节的MMaDA)
下面来看一些典型的论文。
统一视觉Tokenizer
Dual Visual Encoder
首先来看字节的TokenFlow,其针对视觉生成和理解提供了不同的视觉Encoder:视觉理解侧用CLIP ViT-B/14-224/了ViTaminXL-256/SigLIP-SO400M-patch14-384提取适合于理解任务的高层视觉语义特征,而适合于生成任务的视觉特征则使用一个类似于Stable-Diffusion里面的VAE的Encoder的结构(确切来说是VQ-GAN,看代码可以确定)来提取low-level的视觉特征,两类特征在不同的Codebook里面去计算和Codebook的Embedding的距离,两类距离相加之后,再取argmax,得到的ID,作为两类特征的share的ID去各自的Codebook里面检索量化之后的特征,然后通过各自的Decoder,去做图像像素或者图像语义特征重建。
字节的的另外一个团队的Muse-VL的操作类似,唯一的不同点是两种特征在dimension侧concat之后经过一个MLP映射,再做特征的离散量化。Semantic encoder用的SigLIP-SO400m-patch14-384和SigLIP-Large-patch16-256,Image Encoder用的SigLIP权重做初始化,这一点和TokenFlow也不一样。

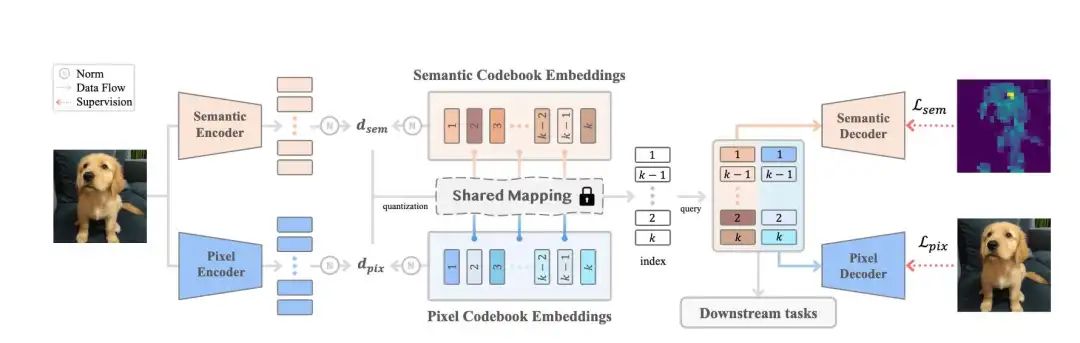
中山大学和华为联合提出的工作SemHiTok和Token-Flow、Muse-VL有异曲同工之妙,SemHiTok的特点是将语义特征重建和像素级图片重建任务结合起来,同时又解耦了Codebook,这样可以让Image Tokenizer同时具备提取高级语义特征(理解)和low-level特征(重建、生成)的能力。

文中先是训练了一个Semantic-Priority Codebook(SPC),发现这样的语义特征在图片重建任务上质量比较差。
输入图片 经过语义编码器 (CLIP、SigLIP的Image Encoder)之后得到语义特征 ,量化bottleneck 将 量化到离散的特征空间 ,量化的公式化表达如下,

其中 是量化之后的特征在码本里面的index, 是量化之后的特征,会作为semantic decoder 的输入,得到 ,整个训练过程是 和 。
文中尝试将这样的特征作为LLaVA-1.5的输入,做图像理解任务,发现比未经过量化之前的、连续的图像特征效果差一些,但是也不赖,但是用到图片重建任务上,效果比较差。
文中就引入了层次化的Codebook即Semantic-Guided Hierarchical Codebook (SGHC)。
基于上面的步骤训练的semantic codebook即 ,pixel codebook为 ,每一个pixel codebook 和一个semantic codebook里面的code 对应。输入图片经过Pixel Encoder提取特征 ,基于semantic codebook的量化结果选择对应的Pixel codebook,然后对Pixel特征做量化,即

然后semantic和pixel方式量化得到的特征连接起来 ,作为Pixel Decoder 的输入,重建图片,
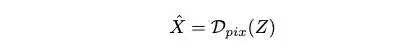
训练损失函数为,
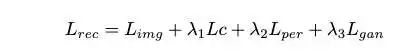
这样Semantic Codebook和Pixel Codebook的训练是解耦的,避免了训练过程之中的冲突。一句话总结,就是semantic-encoder的量化结果引导pixel-encoder选择codebook然后做量化。
Single Visual Encoder
QLIP是UT Austin和Nvidia提出的工作,这个工作算是另辟蹊径,核心仍然是优化视觉理解和生成的Visual Tokenizer,只不过QLIP不是从视觉理解和生成特征的特性差异出发,而是转了一个弯:前面的工作这些高层语义特征其实一般是CLIP、SigLIP的视觉Encoder,都是经过视觉-文本预训练的,而我们的特征不管是视觉理解、还是视觉生成都需要作为LLM的输入,那么特征需要能和文本特征对齐,那么能不能让适合于视觉生成(比如VAE、VQ-GAN提取的视觉特征)和文本特征先做一个对齐呢,这样其实也算是让适合于图片生成的特征包含适合于视觉理解的语义信息了。而且真的是Unified Visual Tokenizer,因为无论是视觉理解还是视觉生成的特征提取都只用了一个Visual Encoder。

训练的时候比较讲究,用到了两阶段的训练策略:
第一个阶段对Text Encoder、Visual Encoder、Quantizer和Visual Decoder进行训练,损失函数包括图片重建损失、量化损失和对比学习的Loss,这个阶段主要是优先学习语义丰富的特征表达,而不是视觉重建,所以也没有Perceptual Loss和Adversarial Loss,视觉特征量化方式为二进制球量化(Binary Spherical Quantization, BSQ)。



第二个阶段会着重提高图片重建质量并且恢复高频细节,这个阶段的损失函数为

港大、华科和字节的工作UniTok和QLIP其实做法有点儿类似,也是只有一个视觉Encoder,而且同时用作视觉生成和理解的特征提取器,只不过在训练的时候,用到了多个codebook的量化,而且和文本特征的对齐也是放在经过离散量化的视觉特征这儿,而不是Vision Encoder输出的特征。

损失函数包括VQ-GAN的重建损失和对比学习损失函数,
Multi-codebook quantization (MCQ)的操作比较常见了(提高codebook利用率),具体操作如下,
视觉特征 在通道维度分为 个块 ,量化过程为:
是离散量化之后的特征, 是code index lookup操作, 是第 个sub-codebook,这种方式理论上增加了Codebook的Size,但是由于是每一个sub-codebook都会用到,所以利用率低和优化难问题会不明显一些。再看一下
再看一下Attention factorization,之前的VQ方法一般在特征量化之前和之后一般是用卷积层或者线性层做特征的维度升降,但是这个方法过于简单的,因此文中提出了一种attention的结构。
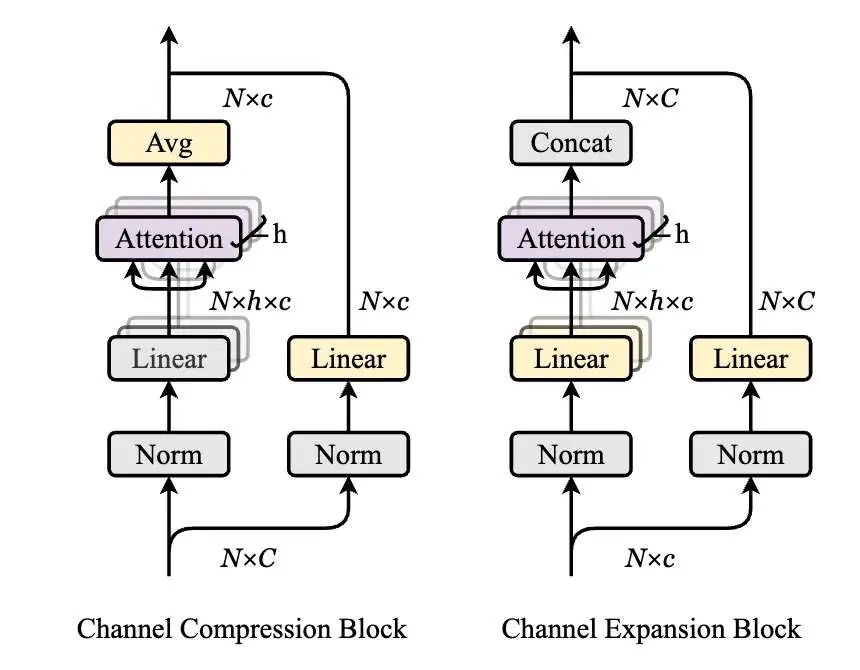
基于UniTok的MLLM,文中用到了Liquid,有一些细节需要注意一下,UniTok把图片映射为 的Token ID,其中 表示有 个Sub-Codebook,在M-LLM输入侧,会把 个Embedding Merge起来得到一个Embedding,在预测的时候,则是一个视觉Token预测K个Code,这里是用了RQ-Transformer里面的Depth Transformer Head。
百川、西湖大学、浙江大学、上海AI Lab、上海创新中心和武汉大学提出的DualToken也是只用一个Visual Encoder提取适合于理解和生成任务的视觉特征,DualToken和TokenFlow、Muse-VL类的方法不一样,没有引入Vision Encoder和Semantic Encoder,而是使用了单一的Vision Encoder,其中底层的视觉特征用于图片重建,深层的视觉特征用于semantic对齐;相同的是针对语义特征和图片重建特征分别用了不同的Visual Codebook。

在训练的时候,视觉Encoder的浅层特征(1-6层)输出的特征经过特征量化之后,送入视觉Decoder重建图片,而深层特征(26层)输出的特征则是经过量化(文中使用了残差量化RQ-VAE)之后,和不经过量化的特征进行对比计算损失。

在结合DualToken的LLM的模型中,sementic和pixel的视觉Token在通道维度concat在一起之后,和文本Token连接在一起,作为LLM的输入。在输出侧,用到了RQ-VAE里面的Depth-Transformer预测对应的Token,然后经过Visual Decoder解码出图片。
腾讯提出的TokLIP也是Single-Encoder的形式,VQGAN Encoder提取视觉特征之后,经过离散量化的特征经过一个Causal Token Encoder得到Semantic Feature,之后计算图片Semantic Feature的蒸馏Loss以及和文本特征的对比学习Loss。


TokLIP Tokenizer包括VQGAN的encoder 、MLP和Causal Token Encoder ,输入图片为 ,得到的特征为 ,
损失函数包括文本-图片对比学习Loss和特征的蒸馏Loss,
TokLIP Tokenizer包括VQGAN的encoder 、MLP和Causal Token Encoder ,输入图片为 ,得到的特征为 ,
损失函数包括文本-图片对比学习Loss和特征的蒸馏Loss,
UniLip是北大、阿里和中科院提出的一个工作,把CLIP的Vision Encoder改造成了一个适合于生成和理解任务的Visual Tokenizer。


第一阶段的损失为:
第二阶段的损失为:
最后和MLLM以及DiT结构进行结合。和BILIP3O和MetaQuery一样,都用到了attention-pooling的方式得到DiT的条件Embedding,和BLIP3O不一样的事,MLLM输出的最后一层的Embedding也作为了DiT的条件Embedding输入。
MLLM结构和MetaQuery类似,包含 MLLM、扩散 Transformer、像素解码器、连接器和 个可学习Query。MLLM 采用 InternVL3 - 1B,Pixel Decoder采用了DC-AE,扩散 Transformer 为 SANA - 0.6B,Connector是 6 层 Transformer,与 InternVL3 - 1B 的 LLM 结构一致。
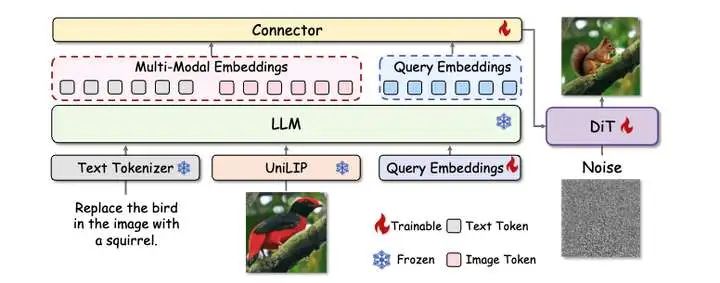
图像生成与编辑训练的训练 分三阶段。第一阶段冻结 MLLM 和扩散 Transformer,仅在生成数据上训练connector 5 万步;第二阶段训练connector和扩散 Transformer,在生成与编辑数据上训练 20 万步;第三阶段在生成与编辑的指令微调数据上训练 2 万步。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!
