“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注!

论文标题: Foundation Model for Skeleton-Based Human Action Understanding 作者团队: Hongsong Wang, Wanjiang Weng, Xin Geng ;Junbo Wang;Fang Zhao ; Guo-Sen Xie ; Liang Wang 机构: 东南大学;西北工业大学;南京大学;南京理工大学;中国科学院 论文地址: https://arxiv.org/abs/2508.12586 项目地址: https://github.com/wengwanjiang/FoundSkelModel 录用期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
研究背景与意义
基于骨架的人体动作理解是具身智能、人机交互和运动分析等领域的核心技术。骨架数据因其轻量、高效且保护隐私的特性而备受青睐。然而,现有的方法大多存在以下问题:
缺乏通用性: 多数模型为特定任务设计,难以泛化到多样的动作理解任务中。 忽视密集预测: 以往工作主要集中在粗粒度的动作识别(对已分割的视频分类),而对更符合现实场景的密集预测任务,如时序动作检测(从长视频中定位动作起止)、动作分割(对每一帧进行分类)和动作预测(根据部分观测预测未来动作)等关注不足。
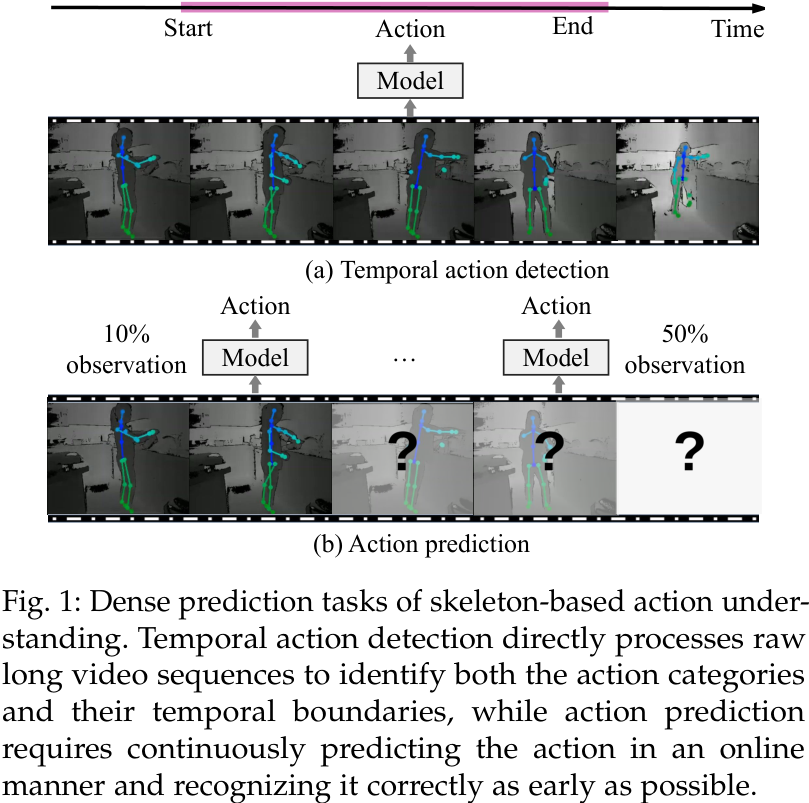

因此,构建一个能够统一处理各类任务、学习有效密集表征、并且高效易用的骨架动作理解基础模型,是当前领域亟待解决的挑战。
USDRL:统一骨架密集表征学习框架
为应对上述挑战,研究者们提出了USDRL框架。其核心思想是利用特征去相关(Feature Decorrelation)的自监督范式,学习高质量的时空密集表征。整个框架主要由三大核心模块构成:密集时空编码器(DSTE)、多粒度特征去相关(MG-FD)和多视角一致性训练(MPCT)。

密集时空编码器 (DSTE)
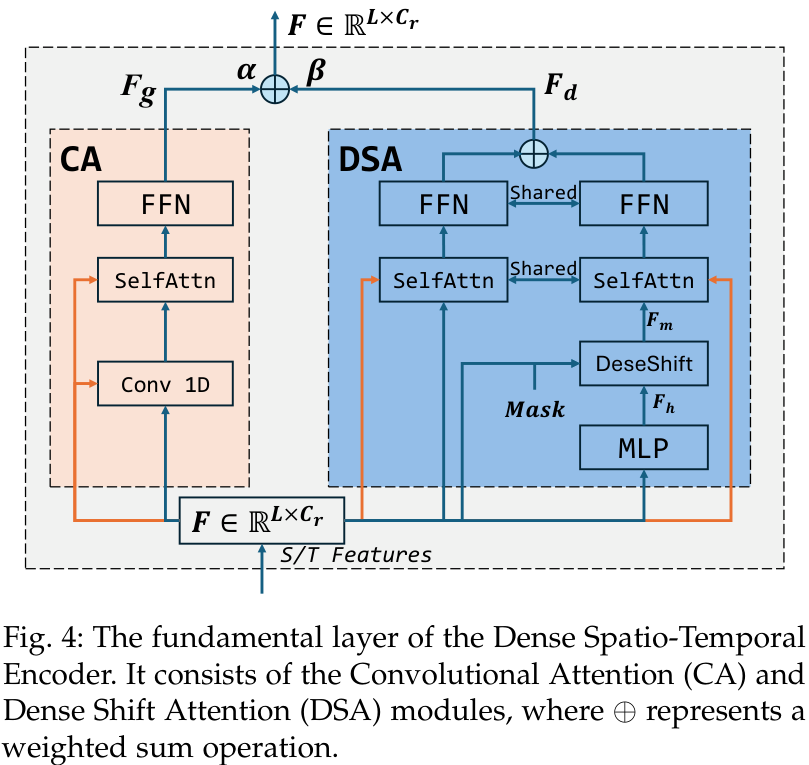
DSTE是模型的主干网络,它采用并行的双流架构,分别用于捕捉骨架序列的时间动态特征和空间结构特征。与传统的Transformer不同,DSTE的每一层都集成了两个创新的模块:
卷积注意力 (Convolutional Attention, CA): 利用1D卷积来高效地捕捉局部特征关系。 密集位移注意力 (Dense Shift Attention, DSA): 通过一种新颖的位移操作和自注意力机制,来发现特征间的深层依赖关系。
这两个模块的加权组合使得DSTE能够有效地建模时空信息,为生成高质量的密集表征奠定基础。
多粒度特征去相关 (MG-FD)
MG-FD是USDRL自监督学习的核心。它摒弃了传统对比学习对负样本的依赖,通过最小化特征维度之间的冗余来防止模型坍塌,从而学习到信息量更丰富的表征。具体来说,MG-FD在三个粒度上进行特征去相关:
实例(Instance)粒度: 确保同一动作在不同数据增强下的表征具有一致性(Intra-Sample Consistency),同时不同动作的表征具有可分性(Inter-Sample Separability)。 时间和空间粒度: 将去相关操作从实例级别扩展到时间和空间维度,进一步提升了模型学习细粒度特征的能力,这对于密集预测任务至关重要。
通过这种多粒度的设计,模型能够学习到既具有判别性又不过于冗余的特征。
多视角一致性训练 (MPCT)
为了进一步提升模型的鲁棒性和泛化能力,研究者引入了MPCT策略。该策略包含两个方面:
多视角训练: 将来自不同摄像机视角下的同一个动作序列作为正样本对进行训练。这使得模型能够学习到视角不变的高层语义信息,忽略低级的视角差异。 多模态训练: 将骨架的不同模态(如关节点坐标-Joint、骨骼信息-Bone、运动信息-Motion)进行早期融合,并共享同一个编码器主干。这种方式相比于为每个模态使用独立编码器的后期融合策略,极大地降低了计算成本,同时促进了信息丰富的多模态特征学习。
实验结果与分析
论文在 9大类任务、25个基准数据集 上对USDRL进行了极为广泛和全面的评估,覆盖了粗粒度预测、密集预测和迁移预测三大类场景。
粗粒度预测任务(无监督识别与检索)
在NTU-60、NTU-120和PKU-MMD II等主流数据集上,USDRL在无监督动作识别任务中全面超越了以往的所有方法,包括基于对比学习、掩码建模和混合学习的SOTA模型。值得注意的是,仅使用单一模态(Joint)的USDRL性能就超过了使用三种模态(J+M+B)的先前最佳方法UmURL。

在半监督动作识别任务上,仅使用1%和10%的随机采样标注训练数据进行全模型微调,证实了所提出方法具有强大的泛化能力,在半监督动作识别任务中展现出竞争优势。

除3D骨架动作识别外,还在2D骨架动作识别任务上评估了本方法。如下表所示,在极具挑战性的UAV-Human数据集上,本方法性能甚至超越部分全监督训练方法。

在半监督和动作检索任务上,USDRL同样展现出强大的性能,证明了其学习到的表征具有优越的泛化性和判别力。

密集预测任务(检测、分割、预测)
这是本次研究的重点。在时序动作检测任务上,USDRL在PKU-MMD I数据集上取得了SOTA性能,其mAPa指标达到了 75.7%,远超之前的方法。

在动作预测、动作分割任务中,仍展现出竞争优势。

下面的可视化结果也直观地展示了USDRL(使用DSTE主干)相比于基线模型(STTR)在动作检测上具有更高的准确率和更精确的定位(更高的IoU)。

在动作预测任务上,USDRL仅需观测到 30% 的动作序列,就能准确识别大多数动作,展现了在现实场景中进行早期动作识别的巨大潜力。

消融实验与可视化
消融研究证实了MG-FD和MPCT中每个组件的有效性。特征可视化分析(下图)清晰地表明,相比于传统对比学习,USDRL所学习到的特征在类别间具有更好的可分性,形成了清晰的簇状结构,证明了特征去相关范式的优越性。

论文贡献与价值
CV君认为,这篇论文的贡献是多方面的,对学术界和工业界都具有重要的参考价值:
提出首个骨架动作理解基础模型: 论文首次明确提出并构建了一个面向通用骨架动作理解的基础模型USDRL,填补了该领域的空白。它为处理多样化、特别是密集预测任务提供了一个强大而统一的基线。 创新的自监督学习范式: 提出的多粒度特征去相关(MG-FD)是一种高效且有效的自监督学习方法,它摆脱了对负样本和复杂网络设计的依赖,为表征学习提供了新的思路。 推动密集预测任务的研究: 论文通过大量的实验和出色的结果,有力地证明了密集表征学习的重要性,有望引导社区将研究重心从传统的动作识别更多地转向更具挑战和实用价值的密集预测任务。 提供高质量的开源代码: 作者开源了他们的代码,这将极大地便利后续研究者在此基础上进行复现、改进和扩展,从而推动整个领域的快速发展。
总而言之,这项工作不仅在技术上取得了突破,更重要的是为基于骨架的人体动作理解研究描绘了新的蓝图,指明了构建通用基础模型这一未来方向。
 本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!
