点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
写在前面
在AI视频生成领域,“短平快”的惊艳早已屡见不鲜。
从几秒的动态画面到十几秒的创意片段,模型总能用细腻的纹理和流畅的转场打动观众。
但当视频时长拉长到20秒、30秒甚至更久,“崩坏”便会悄然降临:原本清晰的人物轮廓逐渐扭曲,连贯的动作突然卡顿,背景元素莫名漂移,物理规律仿佛被按下“混乱键”。这便是长时程视频生成的核心痛点——时间维度上的误差积累,也是学界和工业界长期攻坚的“卡脖子”难题。

近日,来自香港大学与字节跳动Seed团队的研究者提出了名为WorldWeaver的长视频生成框架,直指RGB信号单一依赖导致的“漂移魔咒”。通过将深度、光流等感知信号与RGB帧统一建模,搭配创新的记忆库设计与分段噪声调度策略,该框架在20-30秒长视频生成中实现了时空一致性的显著突破,无论是普通人的日常场景,还是机器人的精密操作,都能保持稳定的结构与流畅的运动。相关论文已上传至arXiv,代码与演示视频也已开放。
长视频生成的难点:为何RGB信号撑不起“漫长时光”?
在深入WorldWeaver的技术细节前,需要先理解一个关键问题:为什么现有模型在长视频生成中会“水土不服”?
当前主流的生成式视频模型,无论是扩散模型(如CogVideoX)还是流匹配模型(如Wan),大多以RGB像素信号作为核心训练数据,优化目标聚焦于像素级的重建精度。这种思路在短序列生成中效果显著——模型只需捕捉几秒钟内的颜色变化与简单运动,就能生成逼真画面。但当视频时长超过10秒,隐患便会暴露:
信号优先级失衡:RGB信号天然侧重颜色与纹理,模型在训练中会不自觉地“忽视”更关键的结构与动态属性。比如,一个人走路的视频中,模型可能精准还原衣服的花纹,却无法稳定人物的骨骼运动轨迹,导致后期出现“肢体扭曲”; 误差积累的“蝴蝶效应”:长视频生成本质是“逐帧预测+时序衔接”的过程。若仅依赖RGB信号,每帧预测中微小的结构偏差(如物体位置偏移1个像素),会随着帧数增加不断放大。实验显示,仅用RGB训练的模型,在生成180帧(约30秒)后,物体结构会出现严重变形,颜色也会偏离初始状态; 物理规律的“隐形缺失”:RGB信号无法直接编码物理约束,比如“杯子不会凭空悬浮”“人物行走时重心会自然起伏”。在长序列中,模型缺乏这类底层逻辑引导,容易生成违反常识的画面,例如杯子突然从桌面消失,或人物脚步与身体运动脱节。
为了打破这一困局,WorldWeaver提出了一个核心思路:跳出RGB的单一视角,引入更稳定的感知信号作为“时空锚点”,从根本上提升长序列的建模能力。

WorldWeaver的三大技术支柱:感知融合、记忆留存与噪声调度
WorldWeaver的整体框架围绕“如何让模型在长时程生成中保持‘记忆’与‘逻辑’”展开,核心包含三大创新模块:联合感知-RGB建模、感知记忆库、分段噪声调度。三者相互配合,分别解决“信号维度不足”“历史信息失效”“训练推理错位”三大问题。

1. 支柱一:联合感知-RGB建模,给模型装上“结构眼睛”
WorldWeaver的第一个突破,是将深度(Depth)、光流(Optical Flow)等感知信号与RGB帧融合,构建统一的 latent 表示空间。这些感知信号的优势在于:它们不依赖光照、纹理等易变因素,能直接编码场景的几何结构与运动规律,是比RGB更稳定的“时空锚点”。
具体实现分为三步:
(1)感知信号的提取与预处理
深度信号(Depth):深度图反映场景中物体的空间距离,是解决“结构漂移”的关键。研究者采用两步法生成深度序列:首先用Video Depth Anything生成单帧初始深度图,再通过DepthAnythingV2的最小二乘优化,计算帧间的相对深度,确保时序一致性。最终得到的深度序列维度为(F为帧数,H、W为画面尺寸),为匹配3D VAE的输入格式(3通道),将单通道深度图重复3次,得到; 光流信号(Optical Flow):光流描述相邻帧间像素的运动轨迹,直接反映物体的运动状态。研究者使用SEA-RAFT模型提取光流场(2通道分别对应水平、垂直位移),再将其转换为RGB格式:通过计算像素运动的幅度(,)和方向(),用幅度控制像素透明度,用方向映射颜色,最后补零帧对齐时序维度,得到; 分割信号(Segmentation,消融实验用):采用SAM2模型提取视频中置信度最高的10个物体掩码,作为可选的感知信号,用于验证不同感知模态的效果。
(2)统一 latent 空间构建
研究者通过3D VAE将RGB、深度、光流分别编码为 latent 表示:(RGB)、(深度)、(光流)。为了兼容现有预训练模型,RGB对应的VAE编码器权重从预训练模型初始化,而深度、光流对应的编码器通道则随机初始化,在微调中自适应学习感知信号的特征。
最终,三者的 latent 表示沿通道维度拼接,形成联合表示。这种设计的核心优势在于:模型能在同一空间中同时学习“外观(RGB)”“结构(深度)”“运动(光流)”的关联,避免单一信号导致的偏科。
(3)联合训练目标设计
传统模型仅优化RGB的重建损失,而WorldWeaver将损失函数扩展到三个模态,公式如下:
其中,是模型预测的RGB、深度、光流 latent,是对应的目标速度(基于流匹配框架的轨迹导数)。通过联合优化三个模态的损失,模型被迫学习更全面的场景动态,而不是“只顾颜色不顾结构”。
实验验证了这一设计的有效性:仅用RGB训练的模型,生成180帧后会出现严重的结构变形与颜色漂移;而联合深度训练的模型,即使到180帧仍能保持物体的完整轮廓(如图3所示)。

2. 支柱二:感知记忆库,让模型“记住”稳定的历史信息
长视频生成的另一个难题是:模型在推理时只能依赖自己生成的历史帧,而这些帧不可避免地存在误差。若直接将带误差的历史帧输入模型,误差会不断积累,最终导致“崩盘”。
为解决这一问题,WorldWeaver设计了感知记忆库(Memory Bank),分为短期记忆与长期记忆两部分,分别负责“细节留存”与“结构稳定”:
(1)短期记忆:保留精细纹理
短期记忆存储与当前帧相邻的少量历史帧(如前5帧)。研究者发现,视频的高频细节(如衣服纹理、面部表情)通常在去噪后期重建,因此将短期记忆的噪声水平设为0(即完全去噪),让模型能直接利用清晰的细节信息,避免细节随时间模糊。
(2)长期记忆:用感知信号锚定结构
长期记忆存储更早的历史帧(如前20-50帧),这类帧对当前帧的细节贡献较小,但对全局结构至关重要。基于“深度比RGB更稳定”的观察(图3),研究者对长期记忆采用差异化噪声策略:
深度信号:保持无噪声,作为全局结构的“稳定锚点”,确保物体的大小、位置、空间关系不随时间漂移; RGB与光流信号:施加低水平噪声(训练时从0.7-0.9随机采样,推理时固定为0.8)。这里的“低噪声”对应高(流匹配框架中,越接近1,噪声越少),既能缓解训练与推理的差异,又不会让历史信息因噪声过多而失效。
对比传统方法(如Diffusion Forcing):传统方法会对历史帧施加大量随机噪声,虽能减少漂移,但也丢失了有用的上下文;而WorldWeaver的感知记忆库,通过深度的“无噪声保护”和RGB/光流的“低噪声调控”,在保留历史信息的同时抑制了误差积累。
3. 支柱三:分段噪声调度,让训练与推理“同频共振”
生成模型的训练与推理过程往往存在“错位”:训练时模型能接触到真实的帧序列,而推理时只能逐帧生成,这种差异会加剧长序列的误差。WorldWeaver通过分段噪声调度(Segmented Noise Scheduling) ,让训练与推理的噪声模式对齐,从根本上减少这种错位。
(1)训练阶段:分组分配噪声
研究者将输入帧分为个连续组(如,每组合并10帧),为每组分配噪声调度曲线中不同段的噪声水平。具体步骤如下:
对每个训练样本,从区间中均匀采样一个索引(训练总步数设为1000); 对第组(),计算其噪声索引:; 根据从噪声调度器中获取对应的sigma值与时间步,为每组分配差异化噪声。
这种设计的优势在于:每组帧的噪声水平覆盖调度曲线的不同段,模型能学习到“从高噪声到低噪声”的连续去噪过程,更贴近推理时的流式生成逻辑。
(2)推理阶段:流式逐组去噪
推理时,模型按组顺序去噪,每组的噪声水平随处理顺序递减(从高噪声到低噪声)。例如,第一组用较高噪声初始化,去噪后作为第二组的上下文,第二组在更低噪声下生成,以此类推。这种流式处理不仅符合人类视觉对“从模糊到清晰”的感知习惯,还能显著降低计算成本——无需一次性处理所有帧,只需缓存当前组与历史记忆库的信息。
实验显示,这种分段噪声调度能让模型的训练收敛速度提升30%以上:相比Diffusion Forcing(80K步收敛)和History Diffusion(70K步收敛),WorldWeaver仅需30K步就能达到稳定性能(表2)。
实验验证:从机器人操作到日常场景,均实现稳定长生成
为了全面验证WorldWeaver的有效性,研究者在两种模型架构(流匹配、扩散)、两种数据集(通用视频、机器人操作)上开展了大量实验,并与10余种主流长视频生成方法进行对比。
1. 实验设置:严谨的基准与指标
模型与数据集: 流匹配模型:Wan2.1-1.3B,训练于字节跳动内部通用视频数据集(300K raw视频,分割为1M短片段,分辨率480×832); 扩散模型:CogVideoX-2B,训练于DROID机器人操作数据集(200K成功操作片段,分辨率480×720); 文本提示:用Tarsier2模型为短片段自动生成字幕,确保提示与内容的一致性; 训练配置:32张NVIDIA A100 GPU,AdamW优化器,学习率1e-4,单卡batch size=4;Wan2.1-1.3B训练50K轮,CogVideoX-2B训练15K步; 评价指标:采用VBench基准,分为“一致性”(主体一致性、背景一致性)与“运动”(运动平滑度、动态程度)两大类,新增指标(计算视频前5秒与后5秒的质量差异),量化“时间漂移”程度。
2. 核心结果:三大维度全面领先
(1)与开源长视频模型对比:漂移控制最优
研究者选取StreamingT2V、CausVid、SkyReels-V2、Magi等开源模型,在20-30秒长视频生成任务上对比。从表1可见:
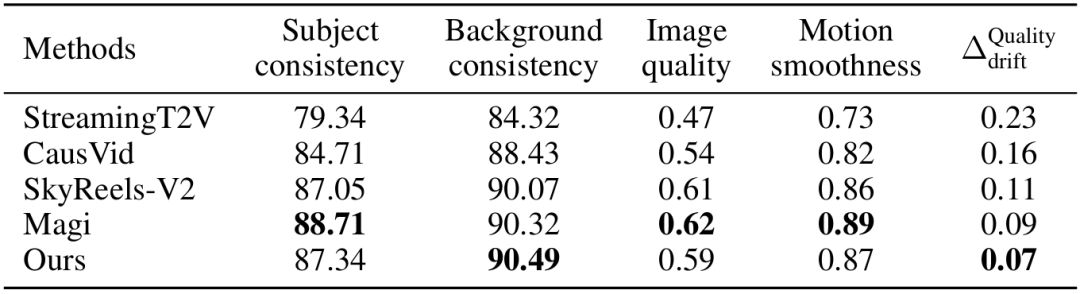
背景一致性:WorldWeaver达到90.49,超过Magi(90.32)、SkyReels-V2(90.07),说明其能更好地保持场景背景的稳定性; 时间漂移:WorldWeaver的仅为0.07,显著低于Magi(0.09)、SkyReels-V2(0.11),即使生成30秒后,视频首尾的质量差异仍很小; 运动平滑度:WorldWeaver达到0.87,与Magi(0.89)接近,说明在控制漂移的同时,并未牺牲运动的流畅性。
(2)与长时程生成方法对比:效率与性能双赢
在更严谨的“同模型同数据集”对比中(CogVideoX-2B+DROID数据集),WorldWeaver与I2V、CausVid、History Diffusion等6种方法较量,结果如表2所示:

结构一致性:WorldWeaver的主体一致性(90.92)、背景一致性(92.39)均排名第一,比第二名CausVid分别高0.49、0.83; 运动质量:运动平滑度达0.75,超过Rolling Diffusion(0.70)、Diffusion Forcing(0.72),说明感知信号的引入有效提升了运动连贯性; 训练效率:仅需30K步收敛,是History Diffusion(70K步)的43%、Diffusion Forcing(80K步)的38%,显著降低了训练成本。
(3)感知信号消融实验:深度+光流是“黄金组合”
为了验证不同感知信号的作用,研究者在5秒短视频上开展消融实验(避免漂移干扰),结果如表3所示:

深度信号:单独加入深度后,主体一致性从92.72提升至94.87,运动平滑度从0.74提升至0.82,证明深度对结构与运动的双重增益; 光流信号:单独加入光流后,动态程度从0.62提升至0.74,是所有单一感知信号中最高的,说明光流对运动建模的关键作用; 深度+光流:两者组合实现最优性能,运动平滑度达0.85,主体一致性94.76,背景一致性95.23,验证了“结构+运动”双锚点的有效性; 分割信号:单独加入分割能提升一致性(94.01),但会略微降低运动质量(0.70),因此未纳入最终框架。
(4)记忆库噪声分析:感知信号提升鲁棒性
研究者还分析了长期记忆库中噪声水平()对性能的影响,结果如表4所示:

无感知条件:当从0.9降至0.3(噪声增加),从0.19降至0.10,但主体一致性从89.64降至88.49,说明“降噪”与“保结构”存在矛盾; 有感知条件:即使(低噪声),仍低至0.07,主体一致性达91.78,证明深度信号的引入让模型对噪声更鲁棒,无需牺牲结构一致性就能控制漂移。
3. 可视化结果:从“崩坏”到“稳定”的质变
论文中展示的可视化结果更直观地体现了WorldWeaver的优势:

在“人物戴墨镜走路”的30秒生成案例中(图1),传统方法生成的视频在15秒后便出现明显问题:人物面部逐渐模糊,墨镜位置偏移,挥手动作僵硬且出现“断帧”,背景中的街道纹理也开始扭曲;而WorldWeaver生成的视频,即使到30秒,人物的面部表情、墨镜位置始终稳定,挥手、转身、走开的动作连贯自然,背景街道的透视关系与纹理细节也保持一致,完全看不出“时间漂移”的痕迹。

在机器人操作场景中(图4),模型需要生成“机械臂依次拾取蓝、橙、绿三色杯子并放到托盘”的20秒视频。传统方法在拾取第二个橙色杯子时,机械臂的关节角度出现偏差,杯子被“悬空抓起”,违背物理规律;而WorldWeaver生成的机械臂运动轨迹精准,每次拾取、放置的动作都符合机械运动逻辑,三个杯子的颜色、位置始终清晰可辨,未出现任何结构变形或位置漂移。
这些可视化结果印证了一个核心结论:感知信号的引入,让模型从“单纯生成像素”升级为“理解场景逻辑”,这正是长视频生成突破“时间魔咒”的关键。
四、局限与未来:长视频生成的“下一程”在哪?
尽管WorldWeaver在长时程视频生成中取得了显著突破,但研究者也指出了当前存在的局限,这些局限也为后续研究指明了方向:
1. 现存局限:三个待解的核心问题
极小物体的生成稳定性不足:当视频中包含尺寸极小的物体(如硬币、纽扣)时,模型仍可能出现“突然消失”或“结构变形”的问题。这是因为即使是深度信号,也难以精准捕捉极小物体的空间特征,导致模型在长序列中无法持续跟踪这类物体; 超长时间序列的误差积累仍存在:虽然WorldWeaver能稳定生成20-30秒的视频,但当时长超过30秒后,生成成功率会逐渐下降,误差积累的问题再次显现。研究者分析,这是因为现有记忆库的容量与更新策略仍需优化,无法完全抵消长时间生成中的误差传递; 感知信号的潜力尚未完全挖掘:当前框架仅探索了深度、光流、分割三种感知信号,而真实场景中还存在更多有价值的线索,如物体的材质属性(硬度、反光度)、物理交互力(碰撞、摩擦)等。如何将这些更复杂的感知信号融入模型,仍是一个待探索的课题。
2. 未来方向:从“稳定生成”到“可控交互”
基于这些局限,研究者提出了三个值得深入的研究方向:
多模态感知信号的融合:未来可尝试引入红外信号(捕捉温度分布)、点云数据(精准还原3D结构)等更丰富的感知模态,进一步提升模型对场景的理解能力,尤其是对极小物体和复杂物理交互的建模; 动态记忆库与误差修正机制:现有记忆库采用“固定存储+静态噪声策略”,未来可设计动态更新的记忆库——根据当前帧的生成质量,自适应调整历史帧的权重与噪声水平;同时加入实时误差修正模块,一旦检测到结构漂移,立即通过感知信号进行校准; 长视频生成的“可控性”升级:当前长视频生成多为“一次性生成”,用户难以干预中间过程。未来可结合WorldWeaver的感知建模能力,开发“交互式长视频生成”系统——用户可通过调整深度图、光流轨迹等感知信号,实时修改物体的位置、运动方向,实现对长视频生成的精细控制。
行业意义:长视频生成从“技术突破”走向“落地赋能”
WorldWeaver的提出,不仅在技术层面突破了长时程视频生成的核心瓶颈,更在行业层面为AI视频生成的落地打开了新的想象空间。
1. 对技术生态的推动:为长视频模型提供“通用框架”
当前长视频生成领域的方法大多“针对特定模型设计”,如StreamingT2V适配 autoregressive 模型,FreeNoise仅适用于扩散模型。而WorldWeaver的优势在于通用性——它不依赖特定的生成架构,无论是扩散模型(如CogVideoX)还是流匹配模型(如Wan),都能通过该框架提升长序列生成性能。这种通用性意味着,WorldWeaver有望成为长视频生成的“通用增强模块”,降低后续研究的开发成本。
同时,WorldWeaver提出的“感知信号+记忆库+分段噪声”的技术范式,也为学界提供了新的研究思路——不再局限于优化RGB信号的建模精度,而是从“场景感知”的角度重构长视频生成的技术路径。
2. 对行业应用的赋能:三大场景率先受益
随着长视频生成稳定性的提升,以下三大行业场景将率先迎来变革:
影视与游戏制作:当前影视预告片、游戏过场动画的制作往往需要大量人工调整,以确保长序列的一致性。WorldWeaver可自动生成30-60秒的高质量长视频,大幅缩短前期创意原型的制作周期;未来甚至可用于生成“交互式游戏剧情视频”,根据玩家的操作实时生成连贯的长序列画面; 机器人仿真与训练:在机器人领域,高质量的仿真视频是训练强化学习模型的关键。WorldWeaver能稳定生成机器人操作的长序列视频(如20秒的多步骤装配过程),且符合物理规律,可作为低成本的仿真数据来源,加速机器人在工业装配、家庭服务等场景的落地; 广告与内容创作:广告行业常需要制作15-30秒的产品宣传视频,要求画面连贯、信息清晰。WorldWeaver可根据文本提示,自动生成包含多场景、多动作的长广告视频,同时保证产品外观、品牌LOGO的一致性,降低中小商家的内容创作门槛。
总结:AI视频生成,从“惊艳一瞬”到“完整叙事”
从早期的几秒钟短视频,到如今WorldWeaver实现20-30秒的稳定长生成,AI视频生成正在经历从“惊艳一瞬”到“完整叙事”的关键跨越。这一跨越的核心,不仅是技术层面的算法优化,更是模型认知能力的升级——从“像素级的模仿”到“场景级的理解”。
WorldWeaver的创新之处在于,它没有陷入“如何让RGB信号更精准”的单一思维,而是跳出像素,从“感知”的角度为模型构建了更稳定的“时空锚点”。这种思路也为AI生成领域的其他方向(如3D生成、动态图像生成)提供了借鉴:当单一信号无法支撑复杂任务时,引入更贴近人类认知的多模态信号,或许是突破瓶颈的关键。
当然,长视频生成的探索仍未结束。如何实现1分钟以上的超长时间生成?如何让模型理解更复杂的物理规律(如液体流动、物体碰撞)?如何实现用户对长视频生成的精细控制?这些问题仍需学界与工业界共同努力。但可以肯定的是,随着WorldWeaver等技术的突破,AI生成“电影级长视频”的梦想,正一步步从科幻走向现实。
参考
论文标题:WorldWeaver: Generating Long-Horizon Video Worlds via Rich Perception
论文链接:https://arxiv.org/pdf/2508.15720
开源链接:https://johanan528.github.io/worldweaver_web/
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!
